 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Vulnerability as a Consequence of On-Manifold Inseparibility
Paper and Code
Oct 09, 2024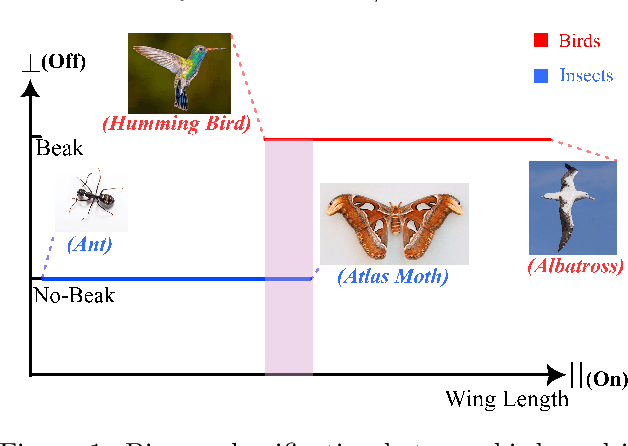
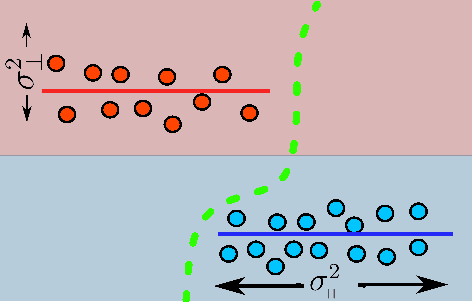
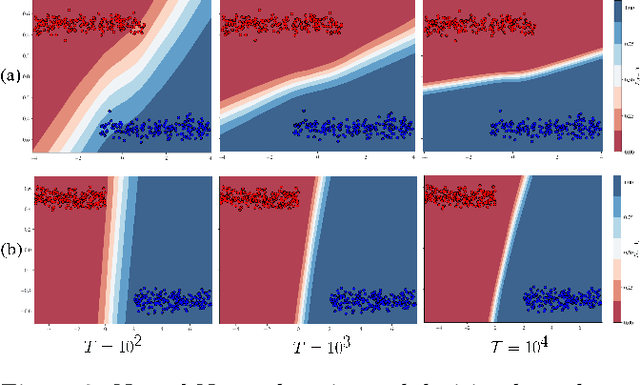
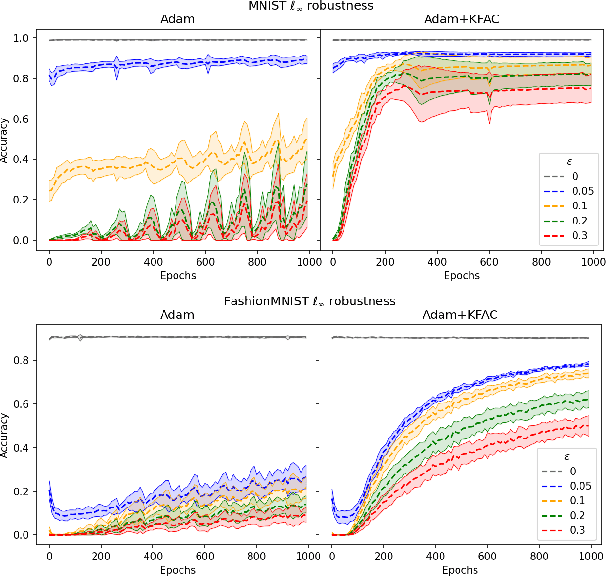
Recent works have shown theoretically and empirically that redundant data dimensions are a source of adversarial vulnerability. However, the inverse doesn't seem to hold in practice; employing dimension-reduction techniques doesn't exhibit robustness as expected. In this work, we consider classification tasks and characterize the data distribution as a low-dimensional manifold, with high/low variance features defining the on/off manifold direction. We argue that clean training experiences poor convergence in the off-manifold direction caused by the ill-conditioning in widely used first-order optimizers like gradient descent. The poor convergence then acts as a source of adversarial vulnerability when the dataset is inseparable in the on-manifold direction. We provide theoretical results for logistic regression and a 2-layer linear network on the considered data distribution. Furthermore, we advocate using second-order methods that are immune to ill-conditioning and lead to better robustness. We perform experiments and exhibit tremendous robustness improvements in clean training through long training and the employment of second-order methods, corroborating our framework. Additionally, we find the inclusion of batch-norm layers hinders such robustness gains. We attribute this to differing implicit biases between traditional and batch-normalized neural networks.