 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-tailored Pre-processing: Fair Downstream Supervised Learning
Jan 17, 2026Fairness-aware machine learning has recently attracted various communities to mitigate discrimination against certain societal groups in data-driven tasks. For fair supervised learning, particularly in pre-processing, there have been two main categories: data fairness and task-tailored fairness. The former directly finds an intermediate distribution among the groups, independent of the type of the downstream model, so a learned downstream classification/regression model returns similar predictive scores to individuals inputting the same covariates irrespective of their sensitive attributes. The latter explicitly takes the supervised learning task into account when constructing the pre-processing map. In this work, we study algorithmic fairness for supervised learning and argue that the data fairness approaches impose overly strong regularization from the perspective of the HGR correlation. This motivates us to devise a novel pre-processing approach tailored to supervised learning. We account for the trade-off between fairness and utility in obtaining the pre-processing map. Then we study the behavior of arbitrary downstream supervised models learned on the transformed data to find sufficient conditions to guarantee their fairness improvement and utility preservation. To our knowledge, no prior work in the branch of task-tailored methods has theoretically investigated downstream guarantees when using pre-processed data. We further evaluate our framework through comparison studies based on tabular and image data sets, showing the superiority of our framework which preserves consistent trade-offs among multiple downstream models compared to recent competing models. Particularly for computer vision data, we see our method alters only necessary semantic features related to the central machine learning task to achieve fairness.
Monotone Curve Estimation via Convex Duality
Jan 14, 2025A principal curve serves as a powerful tool for uncovering underlying structures of data through 1-dimensional smooth and continuous representations. On the basis of optimal transport theories, this paper introduces a novel principal curve framework constrained by monotonicity with rigorous theoretical justifications. We establish statistical guarantees for our monotone curve estimate, including expected empirical and generalized mean squared errors, while proving the existence of such estimates. These statistical foundations justify adopting the popular early stopping procedure in machine learning to implement our numeric algorithm with neural networks. Comprehensive simulation studies reveal that the proposed monotone curve estimate outperforms competing methods in terms of accuracy when the data exhibits a monotonic structure. Moreover, through two real-world applications on future prices of copper, gold, and silver, and avocado prices and sales volume, we underline the robustness of our curve estimate against variable transformation, further confirming its effective applicability for noisy and complex data sets. We believe that this monotone curve-fitting framework offers significant potential for numerous applications where monotonic relationships are intrinsic or need to be imposed.
Parallelly Tempered Generative Adversarial Networks
Nov 18, 2024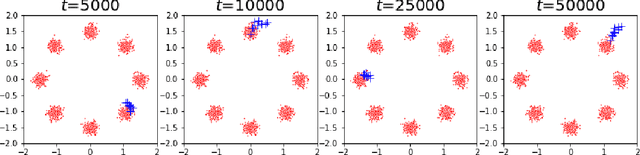



A generative adversarial network (GAN) has been a representative backbone model in generative artificial intelligence (AI) because of its powerful performance in capturing intricate data-generating processes. However, the GAN training is well-known for its notorious training instability, usually characterized by the occurrence of mode collapse. Through the lens of gradients' variance, this work particularly analyzes the training instability and inefficiency in the presence of mode collapse by linking it to multimodality in the target distribution. To ease the raised training issues from severe multimodality, we introduce a novel GAN training framework that leverages a series of tempered distributions produced via convex interpolation. With our newly developed GAN objective function, the generator can learn all the tempered distributions simultaneously, conceptually resonating with the parallel tempering in Statistics. Our simulation studies demonstrate the superiority of our approach over existing popular training strategies in both image and tabular data synthesis. We theoretically analyze that such significant improvement can arise from reducing the variance of gradient estimates by using the tempered distributions. Finally, we further develop a variant of the proposed framework aimed at generating fair synthetic data which is one of the growing interests in the field of trustworthy AI.
Fair Supervised Learning with A Simple Random Sampler of Sensitive Attributes
Nov 10, 2023



As the data-driven decision process becomes dominating for industrial applications, fairness-aware machine learning arouses great attention in various areas. This work proposes fairness penalties learned by neural networks with a simple random sampler of sensitive attributes for non-discriminatory supervised learning. In contrast to many existing works that critically rely on the discreteness of sensitive attributes and response variables, the proposed penalty is able to handle versatile formats of the sensitive attributes, so it is more extensively applicable in practice than many existing algorithms. This penalty enables us to build a computationally efficient group-level in-processing fairness-aware training framework. Empirical evidence shows that our framework enjoys better utility and fairness measures on popular benchmark data sets than competing methods. We also theoretically characterize estimation errors and loss of utility of the proposed neural-penalized risk minimization problem.
Differentially Private Topological Data Analysis
May 05, 2023This paper is the first to attempt differentially private (DP) topological data analysis (TDA), producing near-optimal private persistence diagrams. We analyze the sensitivity of persistence diagrams in terms of the bottleneck distance, and we show that the commonly used \v{C}ech complex has sensitivity that does not decrease as the sample size $n$ increases. This makes it challenging for the persistence diagrams of \v{C}ech complexes to be privatized. As an alternative, we show that the persistence diagram obtained by the $L^1$-distance to measure (DTM) has sensitivity $O(1/n)$. Based on the sensitivity analysis, we propose using the exponential mechanism whose utility function is defined in terms of the bottleneck distance of the $L^1$-DTM persistence diagrams. We also derive upper and lower bounds of the accuracy of our privacy mechanism; the obtained bounds indicate that the privacy error of our mechanism is near-optimal. We demonstrate the performance of our privatized persistence diagrams through simulations as well as on a real dataset tracking human movement.