 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint CNN and Transformer Network via weakly supervised Learning for efficient crowd counting
Mar 12, 2022

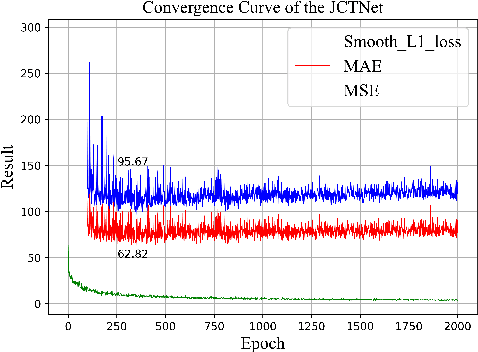
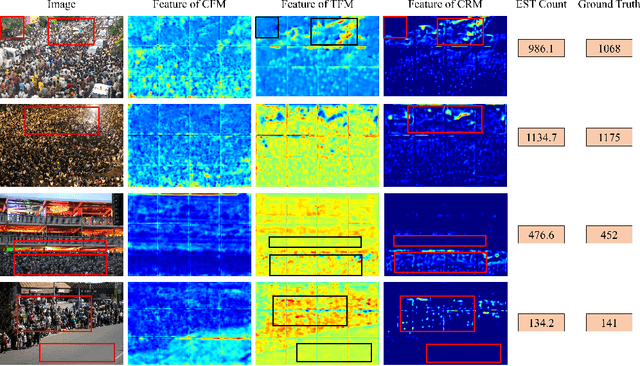
Currently, for crowd counting, the fully supervised methods via density map estimation are the mainstream research directions. However, such methods need location-level annotation of persons in an image, which is time-consuming and laborious. Therefore, the weakly supervised method just relying upon the count-level annotation is urgently needed. Since CNN is not suitable for modeling the global context and the interactions between image patches, crowd counting with weakly supervised learning via CNN generally can not show good performance. The weakly supervised model via Transformer was sequentially proposed to model the global context and learn contrast features. However, the transformer directly partitions the crowd images into a series of tokens, which may not be a good choice due to each pedestrian being an independent individual, and the parameter number of the network is very large. Hence, we propose a Joint CNN and Transformer Network (JCTNet) via weakly supervised learning for crowd counting in this paper. JCTNet consists of three parts: CNN feature extraction module (CFM), Transformer feature extraction module (TFM), and counting regression module (CRM). In particular, the CFM extracts crowd semantic information features, then sends their patch partitions to TRM for modeling global context, and CRM is used to predict the number of people. Extensive experiments and visualizations demonstrate that JCTNet can effectively focus on the crowd regions and obtain superior weakly supervised counting performance on five mainstream datasets. The number of parameters of the model can be reduced by about 67%~73% compared with the pure Transformer works. We also tried to explain the phenomenon that a model constrained only by count-level annotations can still focus on the crowd regions. We believe our work can promote further research in this field.