 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinocular Mutual Learning for Improving Few-shot Classification
Aug 27, 2021
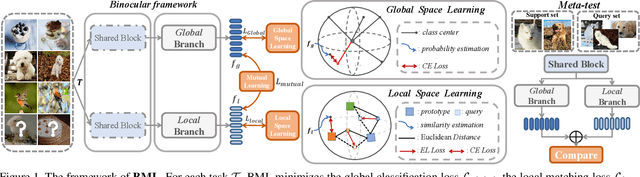
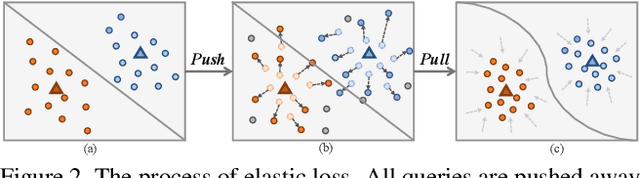
Most of the few-shot learning methods learn to transfer knowledge from datasets with abundant labeled data (i.e., the base set). From the perspective of class space on base set, existing methods either focus on utilizing all classes under a global view by normal pretraining, or pay more attention to adopt an episodic manner to train meta-tasks within few classes in a local view. However, the interaction of the two views is rarely explored. As the two views capture complementary information, we naturally think of the compatibility of them for achieving further performance gains. Inspired by the mutual learning paradigm and binocular parallax, we propose a unified framework, namely Binocular Mutual Learning (BML), which achieves the compatibility of the global view and the local view through both intra-view and cross-view modeling. Concretely, the global view learns in the whole class space to capture rich inter-class relationships. Meanwhile, the local view learns in the local class space within each episode, focusing on matching positive pairs correctly. In addition, cross-view mutual interaction further promotes the collaborative learning and the implicit exploration of useful knowledge from each other. During meta-test, binocular embeddings are aggregated together to support decision-making, which greatly improve the accuracy of classification. Extensive experiments conducted on multiple benchmarks including cross-domain validation confirm the effectiveness of our method.
DeFRCN: Decoupled Faster R-CNN for Few-Shot Object Detection
Aug 20, 2021

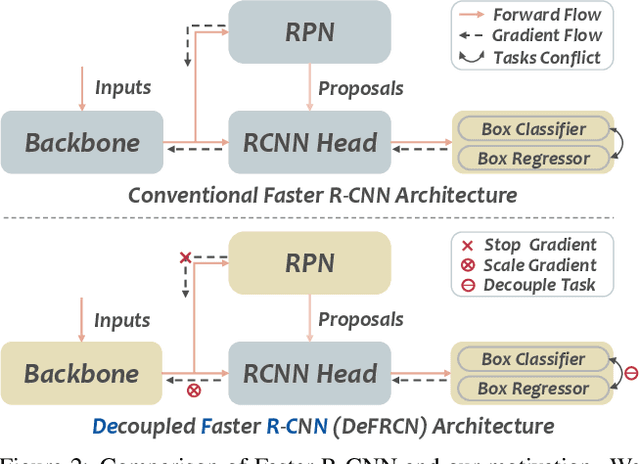
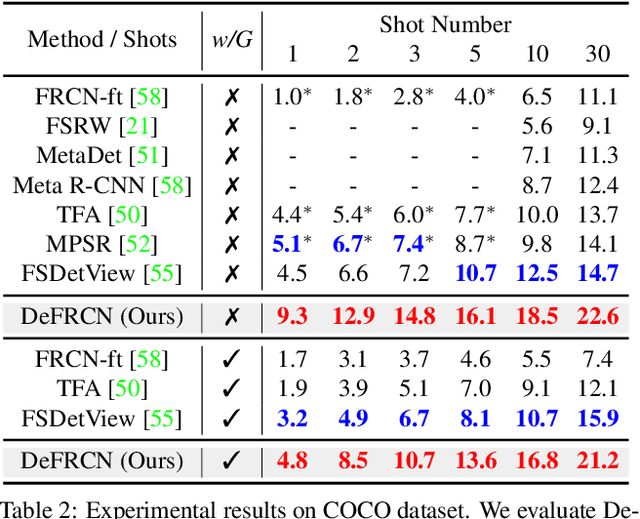
Few-shot object detection, which aims at detecting novel objects rapidly from extremely few annotated examples of previously unseen classes, has attracted significant research interest in the community. Most existing approaches employ the Faster R-CNN as basic detection framework, yet, due to the lack of tailored considerations for data-scarce scenario, their performance is often not satisfactory. In this paper, we look closely into the conventional Faster R-CNN and analyze its contradictions from two orthogonal perspectives, namely multi-stage (RPN vs. RCNN) and multi-task (classification vs. localization). To resolve these issues, we propose a simple yet effective architecture, named Decoupled Faster R-CNN (DeFRCN). To be concrete, we extend Faster R-CNN by introducing Gradient Decoupled Layer for multi-stage decoupling and Prototypical Calibration Block for multi-task decoupling. The former is a novel deep layer with redefining the feature-forward operation and gradient-backward operation for decoupling its subsequent layer and preceding layer, and the latter is an offline prototype-based classification model with taking the proposals from detector as input and boosting the original classification scores with additional pairwise scores for calibration. Extensive experiments on multiple benchmarks show our framework is remarkably superior to other existing approaches and establishes a new state-of-the-art in few-shot literature.
SQE: a Self Quality Evaluation Metric for Parameters Optimization in Multi-Object Tracking
Apr 16, 2020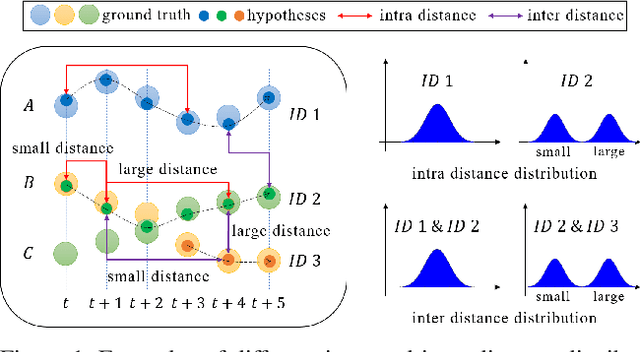
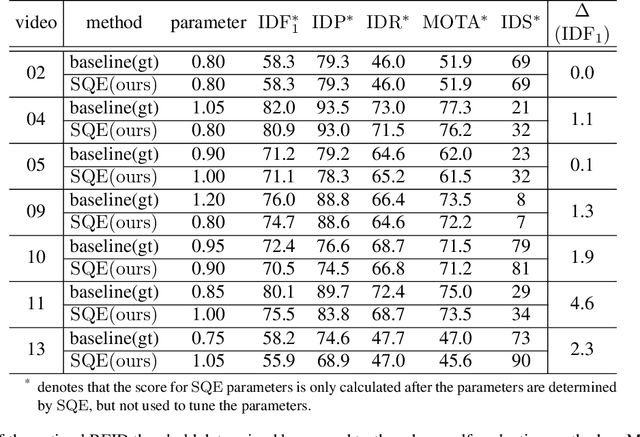
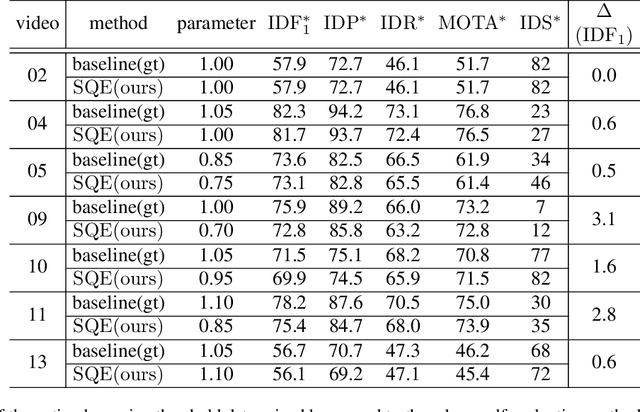
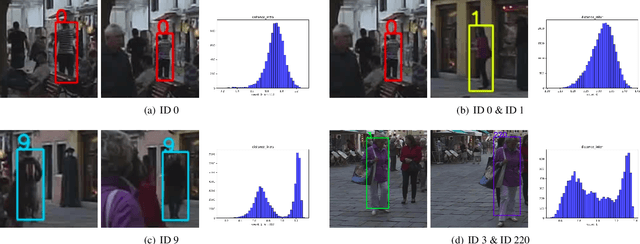
We present a novel self quality evaluation metric SQE for parameters optimization in the challenging yet critical multi-object tracking task. Current evaluation metrics all require annotated ground truth, thus will fail in the test environment and realistic circumstances prohibiting further optimization after training. By contrast, our metric reflects the internal characteristics of trajectory hypotheses and measures tracking performance without ground truth. We demonstrate that trajectories with different qualities exhibit different single or multiple peaks over feature distance distribution, inspiring us to design a simple yet effective method to assess the quality of trajectories using a two-class Gaussian mixture model. Experiments mainly on MOT16 Challenge data sets verify the effectiveness of our method in both correlating with existing metrics and enabling parameters self-optimization to achieve better performance. We believe that our conclusions and method are inspiring for future multi-object tracking in practice.
Multi-Target, Multi-Camera Tracking by Hierarchical Clustering: Recent Progress on DukeMTMC Project
Dec 27, 2017Although many methods perform well in single camera tracking, multi-camera tracking remains a challenging problem with less attention. DukeMTMC is a large-scale, well-annotated multi-camera tracking benchmark which makes great progress in this field. This report is dedicated to briefly introduce our method on DukeMTMC and show that simple hierarchical clustering with well-trained person re-identification features can get good results on this dataset.
SOT for MOT
Dec 04, 2017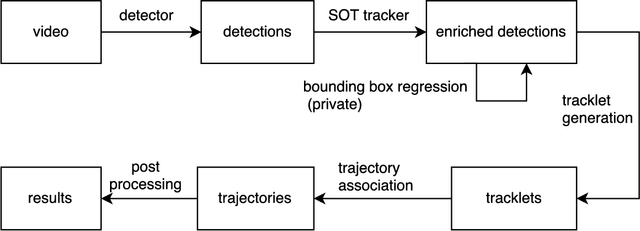


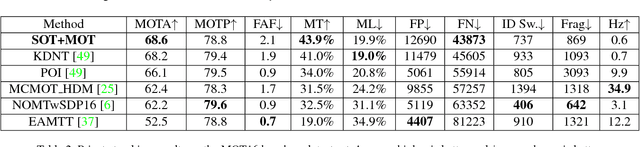
In this paper we present a robust tracker to solve the multiple object tracking (MOT) problem, under the framework of tracking-by-detection. As the first contribution, we innovatively combine single object tracking (SOT) algorithms with multiple object tracking algorithms, and our results show that SOT is a general way to strongly reduce the number of false negatives, regardless of the quality of detection. Another contribution is that we show with a deep learning based appearance model, it is easy to associate detections of the same object efficiently and also with high accuracy. This appearance model plays an important role in our MOT algorithm to correctly associate detections into long trajectories, and also in our SOT algorithm to discover new detections mistakenly missed by the detector. The deep neural network based model ensures the robustness of our tracking algorithm, which can perform data association in a wide variety of scenes. We ran comprehensive experiments on a large-scale and challenging dataset, the MOT16 benchmark, and results showed that our tracker achieved state-of-the-art performance based on both public and private detections.
Incidental Scene Text Understanding: Recent Progresses on ICDAR 2015 Robust Reading Competition Challenge 4
Feb 03, 2016

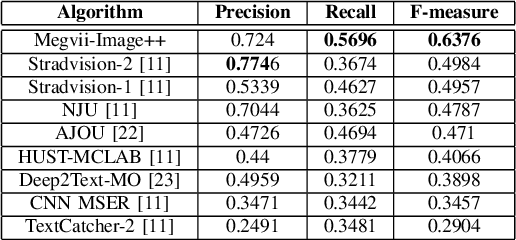
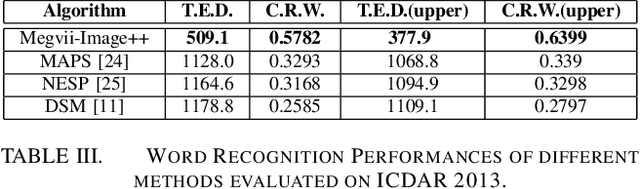
Different from focused texts present in natural images, which are captured with user's intention and intervention, incidental texts usually exhibit much more diversity, variability and complexity, thus posing significant difficulties and challenges for scene text detection and recognition algorithms. The ICDAR 2015 Robust Reading Competition Challenge 4 was launched to assess the performance of existing scene text detection and recognition methods on incidental texts as well as to stimulate novel ideas and solutions. This report is dedicated to briefly introduce our strategies for this challenging problem and compare them with prior arts in this field.