 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGridFace: Face Rectification via Learning Local Homography Transformations
Aug 19, 2018
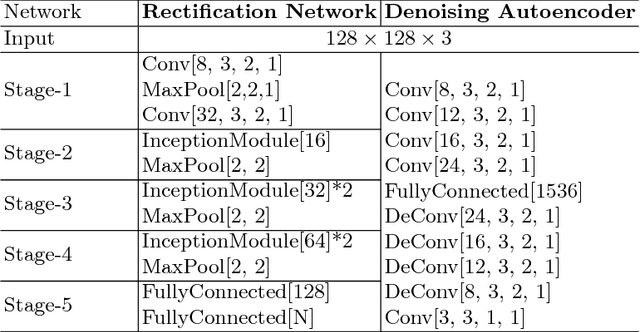
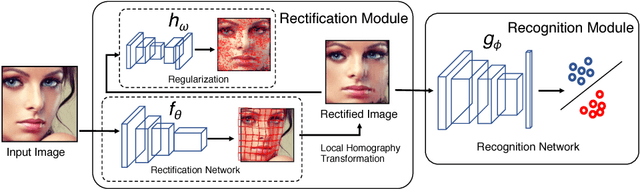
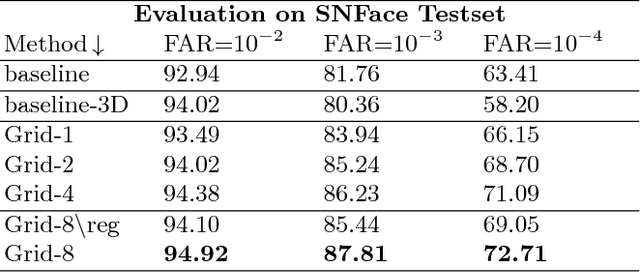
In this paper, we propose a method, called GridFace, to reduce facial geometric variations and improve the recognition performance. Our method rectifies the face by local homography transformations, which are estimated by a face rectification network. To encourage the image generation with canonical views, we apply a regularization based on the natural face distribution. We learn the rectification network and recognition network in an end-to-end manner. Extensive experiments show our method greatly reduces geometric variations, and gains significant improvements in unconstrained face recognition scenarios.
What Can Help Pedestrian Detection?
May 08, 2017
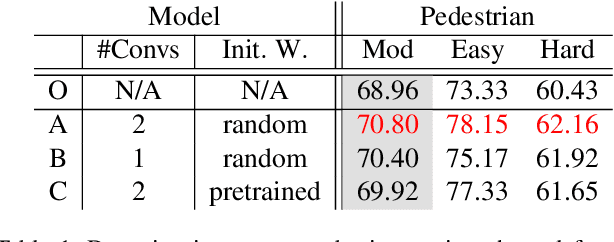

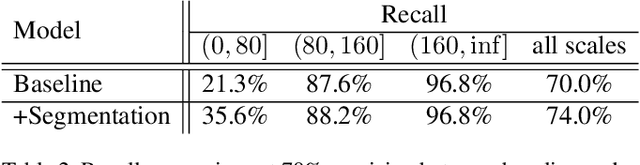
Aggregating extra features has been considered as an effective approach to boost traditional pedestrian detection methods. However, there is still a lack of studies on whether and how CNN-based pedestrian detectors can benefit from these extra features. The first contribution of this paper is exploring this issue by aggregating extra features into CNN-based pedestrian detection framework. Through extensive experiments, we evaluate the effects of different kinds of extra features quantitatively. Moreover, we propose a novel network architecture, namely HyperLearner, to jointly learn pedestrian detection as well as the given extra feature. By multi-task training, HyperLearner is able to utilize the information of given features and improve detection performance without extra inputs in inference. The experimental results on multiple pedestrian benchmarks validate the effectiveness of the proposed HyperLearner.
FastMask: Segment Multi-scale Object Candidates in One Shot
Apr 11, 2017

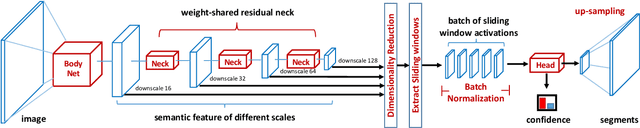

Objects appear to scale differently in natural images. This fact requires methods dealing with object-centric tasks (e.g. object proposal) to have robust performance over variances in object scales. In the paper, we present a novel segment proposal framework, namely FastMask, which takes advantage of hierarchical features in deep convolutional neural networks to segment multi-scale objects in one shot. Innovatively, we adapt segment proposal network into three different functional components (body, neck and head). We further propose a weight-shared residual neck module as well as a scale-tolerant attentional head module for efficient one-shot inference. On MS COCO benchmark, the proposed FastMask outperforms all state-of-the-art segment proposal methods in average recall being 2~5 times faster. Moreover, with a slight trade-off in accuracy, FastMask can segment objects in near real time (~13 fps) with 800*600 resolution images, demonstrating its potential in practical applications. Our implementation is available on https://github.com/voidrank/FastMask.
UnitBox: An Advanced Object Detection Network
Aug 04, 2016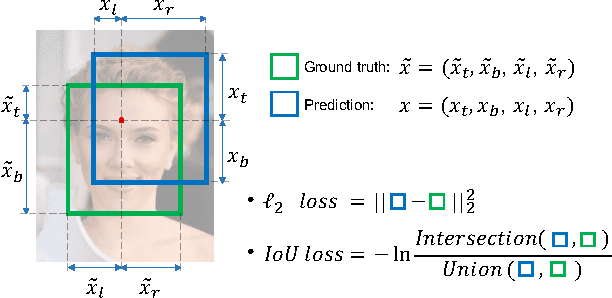
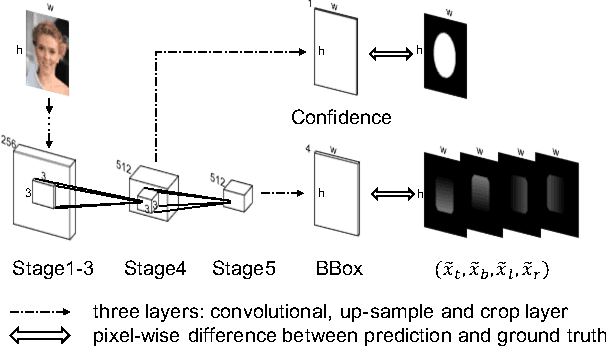

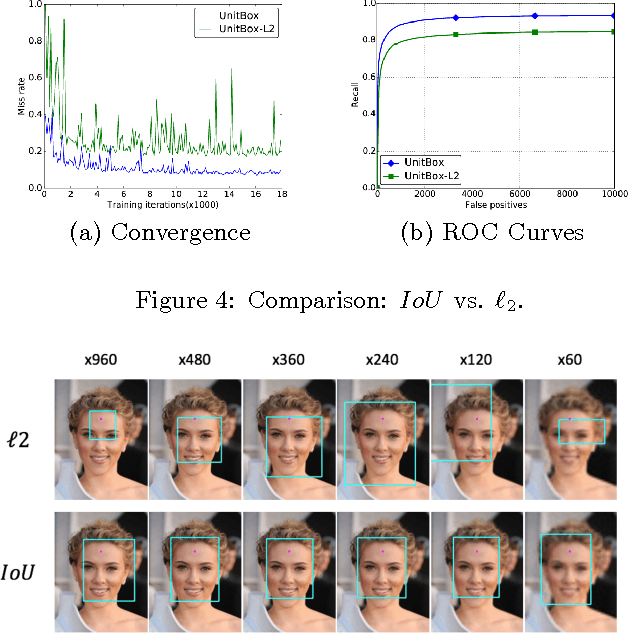
In present object detection systems, the deep convolutional neural networks (CNNs) are utilized to predict bounding boxes of object candidates, and have gained performance advantages over the traditional region proposal methods. However, existing deep CNN methods assume the object bounds to be four independent variables, which could be regressed by the $\ell_2$ loss separately. Such an oversimplified assumption is contrary to the well-received observation, that those variables are correlated, resulting to less accurate localization. To address the issue, we firstly introduce a novel Intersection over Union ($IoU$) loss function for bounding box prediction, which regresses the four bounds of a predicted box as a whole unit. By taking the advantages of $IoU$ loss and deep fully convolutional networks, the UnitBox is introduced, which performs accurate and efficient localization, shows robust to objects of varied shapes and scales, and converges fast. We apply UnitBox on face detection task and achieve the best performance among all published methods on the FDDB benchmark.
Scene Text Detection via Holistic, Multi-Channel Prediction
Jul 05, 2016


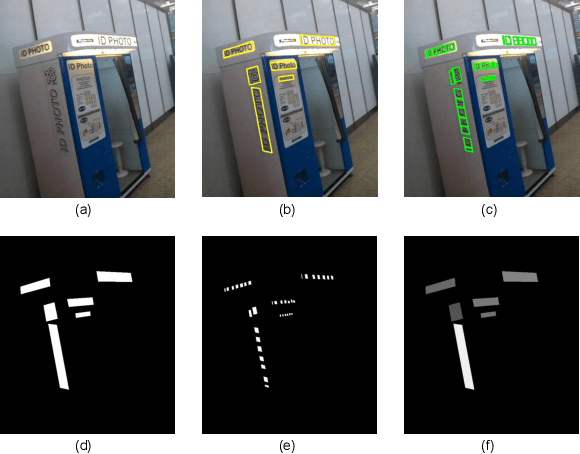
Recently, scene text detection has become an active research topic in computer vision and document analysis, because of its great importance and significant challenge. However, vast majority of the existing methods detect text within local regions, typically through extracting character, word or line level candidates followed by candidate aggregation and false positive elimination, which potentially exclude the effect of wide-scope and long-range contextual cues in the scene. To take full advantage of the rich information available in the whole natural image, we propose to localize text in a holistic manner, by casting scene text detection as a semantic segmentation problem. The proposed algorithm directly runs on full images and produces global, pixel-wise prediction maps, in which detections are subsequently formed. To better make use of the properties of text, three types of information regarding text region, individual characters and their relationship are estimated, with a single Fully Convolutional Network (FCN) model. With such predictions of text properties, the proposed algorithm can simultaneously handle horizontal, multi-oriented and curved text in real-world natural images. The experiments on standard benchmarks, including ICDAR 2013, ICDAR 2015 and MSRA-TD500, demonstrate that the proposed algorithm substantially outperforms previous state-of-the-art approaches. Moreover, we report the first baseline result on the recently-released, large-scale dataset COCO-Text.
Incidental Scene Text Understanding: Recent Progresses on ICDAR 2015 Robust Reading Competition Challenge 4
Feb 03, 2016

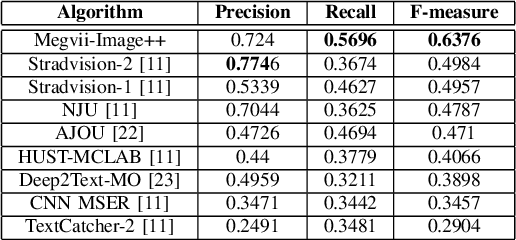
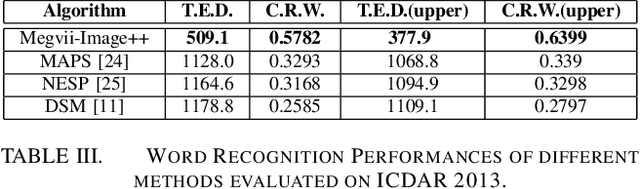
Different from focused texts present in natural images, which are captured with user's intention and intervention, incidental texts usually exhibit much more diversity, variability and complexity, thus posing significant difficulties and challenges for scene text detection and recognition algorithms. The ICDAR 2015 Robust Reading Competition Challenge 4 was launched to assess the performance of existing scene text detection and recognition methods on incidental texts as well as to stimulate novel ideas and solutions. This report is dedicated to briefly introduce our strategies for this challenging problem and compare them with prior arts in this field.
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression
Nov 16, 2015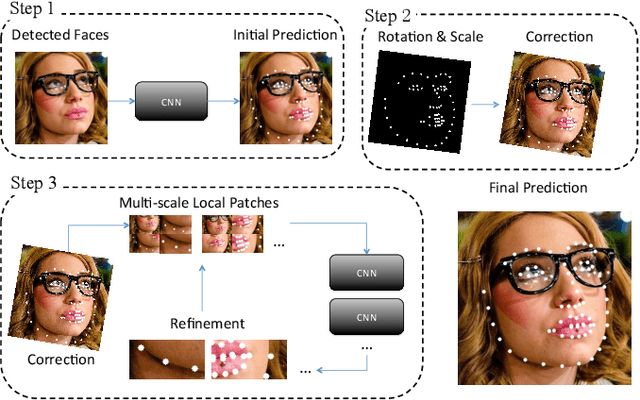

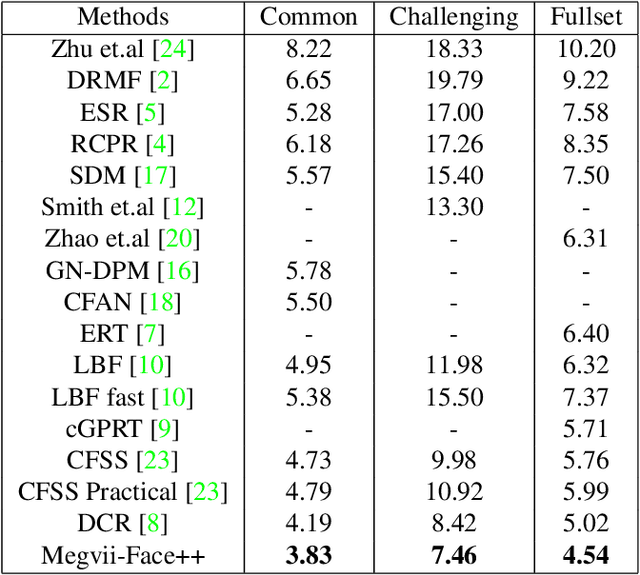

Facial landmark localization plays an important role in face recognition and analysis applications. In this paper, we give a brief introduction to a coarse-to-fine pipeline with neural networks and sequential regression. First, a global convolutional network is applied to the holistic facial image to give an initial landmark prediction. A pyramid of multi-scale local image patches is then cropped to feed to a new network for each landmark to refine the prediction. As the refinement network outputs a more accurate position estimation than the input, such procedure could be repeated several times until the estimation converges. We evaluate our system on the 300-W dataset [11] and it outperforms the recent state-of-the-arts.
ICDAR 2015 Text Reading in the Wild Competition
Jun 10, 2015

Recently, text detection and recognition in natural scenes are becoming increasing popular in the computer vision community as well as the document analysis community. However, majority of the existing ideas, algorithms and systems are specifically designed for English. This technical report presents the final results of the ICDAR 2015 Text Reading in the Wild (TRW 2015) competition, which aims at establishing a benchmark for assessing detection and recognition algorithms devised for both Chinese and English scripts and providing a playground for researchers from the community. In this article, we describe in detail the dataset, tasks, evaluation protocols and participants of this competition, and report the performance of the participating methods. Moreover, promising directions for future research are discussed.
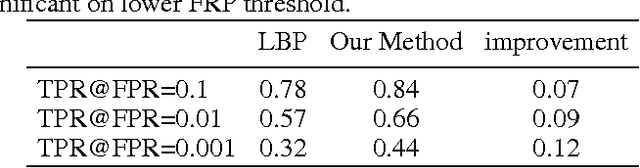
Naive-Deep Face Recognition: Touching the Limit of LFW Benchmark or Not?
Jan 20, 2015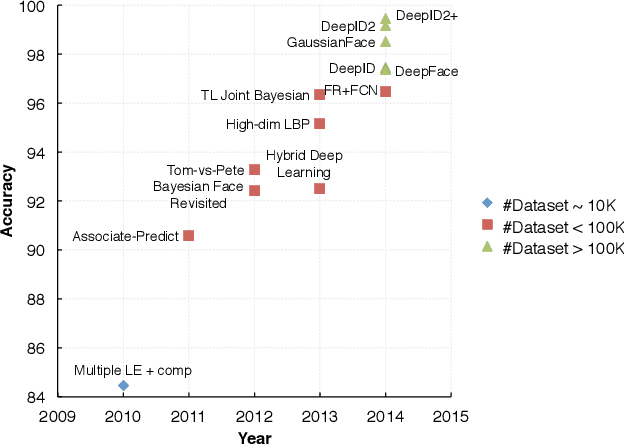
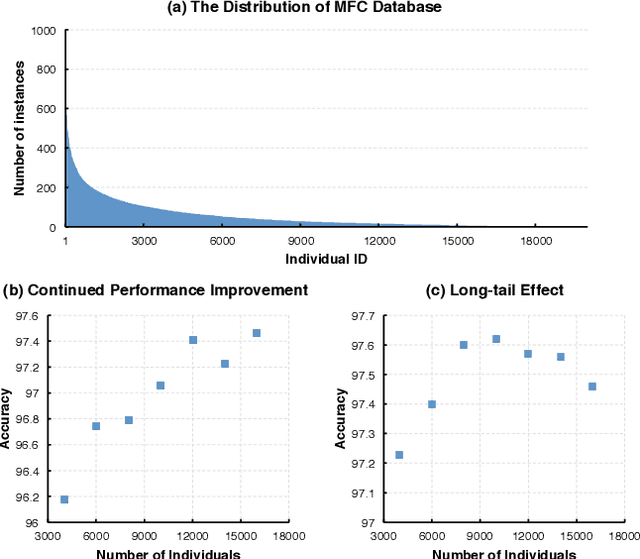
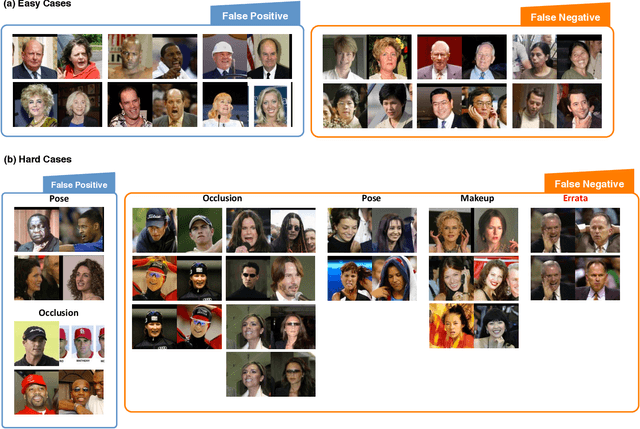
Face recognition performance improves rapidly with the recent deep learning technique developing and underlying large training dataset accumulating. In this paper, we report our observations on how big data impacts the recognition performance. According to these observations, we build our Megvii Face Recognition System, which achieves 99.50% accuracy on the LFW benchmark, outperforming the previous state-of-the-art. Furthermore, we report the performance in a real-world security certification scenario. There still exists a clear gap between machine recognition and human performance. We summarize our experiments and present three challenges lying ahead in recent face recognition. And we indicate several possible solutions towards these challenges. We hope our work will stimulate the community's discussion of the difference between research benchmark and real-world applications.
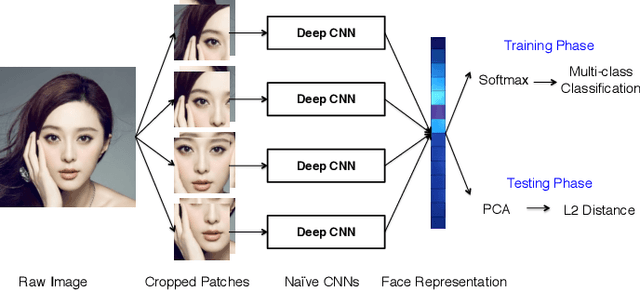
Learning Deep Face Representation
Mar 12, 2014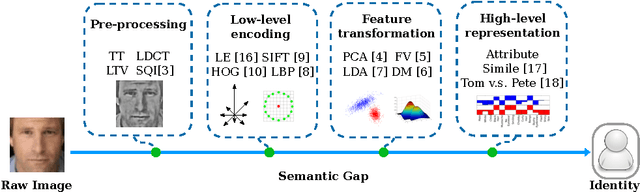
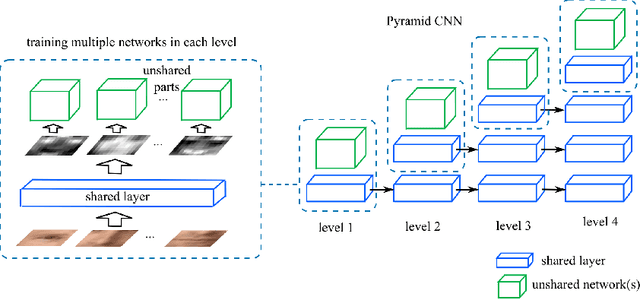
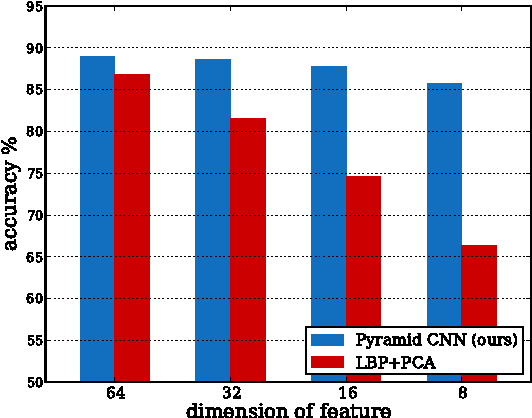
Face representation is a crucial step of face recognition systems. An optimal face representation should be discriminative, robust, compact, and very easy-to-implement. While numerous hand-crafted and learning-based representations have been proposed, considerable room for improvement is still present. In this paper, we present a very easy-to-implement deep learning framework for face representation. Our method bases on a new structure of deep network (called Pyramid CNN). The proposed Pyramid CNN adopts a greedy-filter-and-down-sample operation, which enables the training procedure to be very fast and computation-efficient. In addition, the structure of Pyramid CNN can naturally incorporate feature sharing across multi-scale face representations, increasing the discriminative ability of resulting representation. Our basic network is capable of achieving high recognition accuracy ($85.8\%$ on LFW benchmark) with only 8 dimension representation. When extended to feature-sharing Pyramid CNN, our system achieves the state-of-the-art performance ($97.3\%$) on LFW benchmark. We also introduce a new benchmark of realistic face images on social network and validate our proposed representation has a good ability of generalization.