 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncidental Scene Text Understanding: Recent Progresses on ICDAR 2015 Robust Reading Competition Challenge 4
Feb 03, 2016

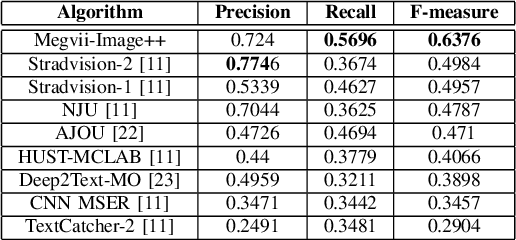
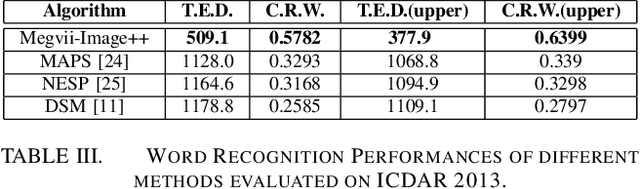
Different from focused texts present in natural images, which are captured with user's intention and intervention, incidental texts usually exhibit much more diversity, variability and complexity, thus posing significant difficulties and challenges for scene text detection and recognition algorithms. The ICDAR 2015 Robust Reading Competition Challenge 4 was launched to assess the performance of existing scene text detection and recognition methods on incidental texts as well as to stimulate novel ideas and solutions. This report is dedicated to briefly introduce our strategies for this challenging problem and compare them with prior arts in this field.
ICDAR 2015 Text Reading in the Wild Competition
Jun 10, 2015

Recently, text detection and recognition in natural scenes are becoming increasing popular in the computer vision community as well as the document analysis community. However, majority of the existing ideas, algorithms and systems are specifically designed for English. This technical report presents the final results of the ICDAR 2015 Text Reading in the Wild (TRW 2015) competition, which aims at establishing a benchmark for assessing detection and recognition algorithms devised for both Chinese and English scripts and providing a playground for researchers from the community. In this article, we describe in detail the dataset, tasks, evaluation protocols and participants of this competition, and report the performance of the participating methods. Moreover, promising directions for future research are discussed.
Naive-Deep Face Recognition: Touching the Limit of LFW Benchmark or Not?
Jan 20, 2015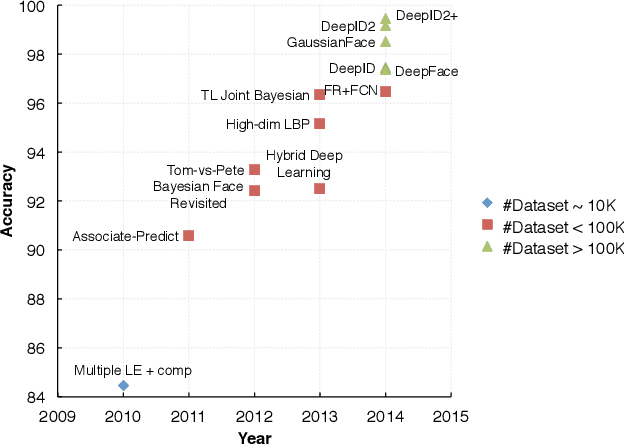
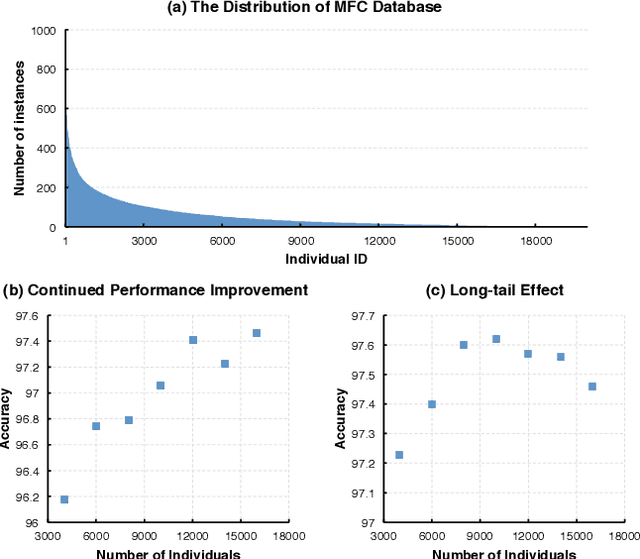
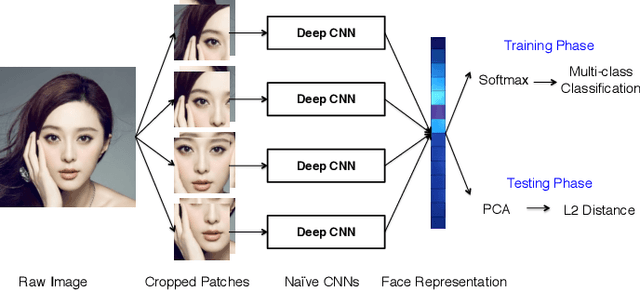
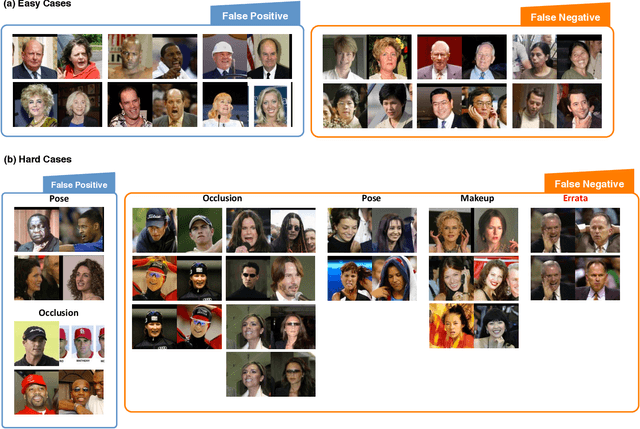
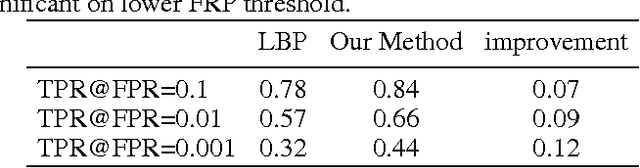
Face recognition performance improves rapidly with the recent deep learning technique developing and underlying large training dataset accumulating. In this paper, we report our observations on how big data impacts the recognition performance. According to these observations, we build our Megvii Face Recognition System, which achieves 99.50% accuracy on the LFW benchmark, outperforming the previous state-of-the-art. Furthermore, we report the performance in a real-world security certification scenario. There still exists a clear gap between machine recognition and human performance. We summarize our experiments and present three challenges lying ahead in recent face recognition. And we indicate several possible solutions towards these challenges. We hope our work will stimulate the community's discussion of the difference between research benchmark and real-world applications.
Learning Deep Face Representation
Mar 12, 2014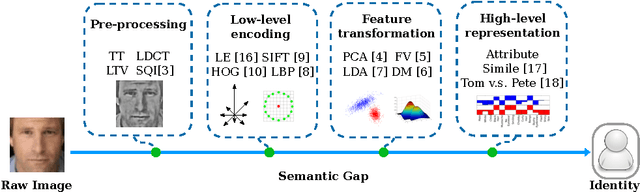
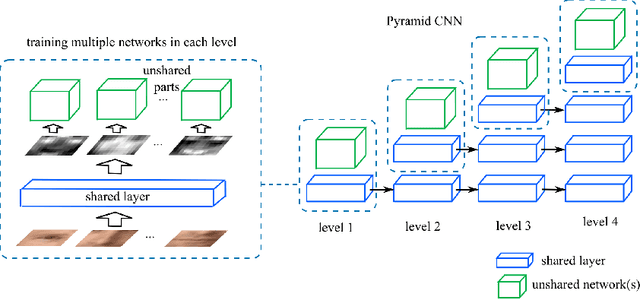
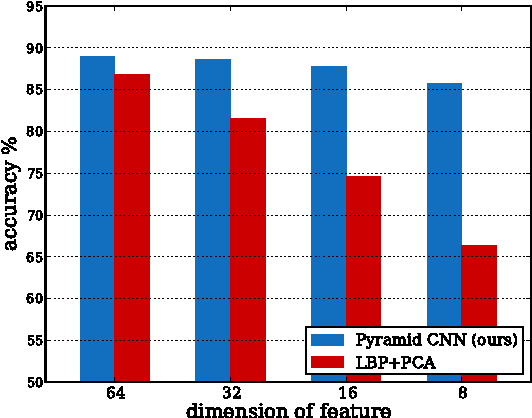
Face representation is a crucial step of face recognition systems. An optimal face representation should be discriminative, robust, compact, and very easy-to-implement. While numerous hand-crafted and learning-based representations have been proposed, considerable room for improvement is still present. In this paper, we present a very easy-to-implement deep learning framework for face representation. Our method bases on a new structure of deep network (called Pyramid CNN). The proposed Pyramid CNN adopts a greedy-filter-and-down-sample operation, which enables the training procedure to be very fast and computation-efficient. In addition, the structure of Pyramid CNN can naturally incorporate feature sharing across multi-scale face representations, increasing the discriminative ability of resulting representation. Our basic network is capable of achieving high recognition accuracy ($85.8\%$ on LFW benchmark) with only 8 dimension representation. When extended to feature-sharing Pyramid CNN, our system achieves the state-of-the-art performance ($97.3\%$) on LFW benchmark. We also introduce a new benchmark of realistic face images on social network and validate our proposed representation has a good ability of generalization.