 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Talking to Singing: A New Challenge for Audio-Visual Deepfake Detection
May 27, 2026With rapid advances in audio-visual generative models, reliable forgery detection becomes increasingly critical. Existing methods for audio-visual deepfake detection typically rely on cross-modal inconsistencies. In singing, rhythmic vocalization weakens this coupling and introduces a nontrivial domain shift, substantially degrading detection performance. We construct the Singing Head DeepFake (SHDF) dataset using rhythm-aware generative models to fill the gap in singing benchmarks. To cope with cross-scenario domain shifts, we propose a Text-guided Audio-Visual Forgery Detection (T-AVFD) framework that generalizes across both talking and singing scenarios. T-AVFD comprises a facial authenticity pattern learner and a multi-modal differential weight learning module. The pattern learner aligns facial features with multi-granularity textual descriptions to learn generalizable authenticity patterns. The weight learning module preserves intrinsic audio-visual consistency and adaptively integrates it with authenticity patterns via differential weighting. Extensive experiments on multiple talking head deepfake datasets and SHDF show consistent improvements over existing baselines and strong robustness under diverse perturbations.
LEGO: LoRA-Enabled Generator-Oriented Framework for Synthetic Image Detection
May 06, 2026The rapid advancement of generative technologies has made synthetic images nearly indistinguishable from real ones, thereby creating an urgent need for robust detectors to counter misinformation. However, existing methods mainly rely on universal artifact features that are shared across multiple generators. We observe that as the diversity of generators increases, the overlap of these common features gradually decreases. This severely undermines model generalization. In contrast, focusing only on unique artifacts tends to cause overfitting to specific forgery patterns. To address this challenge, we propose LEGO (LoRA-Enabled Generator-Oriented Framework). The core mechanism of LEGO employs an MLP to modulate multiple LoRA (Low-Rank Adaptation) blocks, each pretrained to capture the unique artifacts of a specific generator, followed by attention-based feature fusion. Unlike conventional methods that seek a single universal solution, LEGO delegates unique artifact extraction to specialized LoRA modules by dividing its training procedure into two stages. Each LoRA module is individually trained on a single-generator dataset to learn generator-specific representations, then MLP and attention layers are trained on mixed datasets to dynamically regulate the contribution of each module. Benefiting from its modular yet robust design, LEGO can be naturally extended by incorporating new LoRA modules for adaptation to newly emerging next-generation datasets, while still achieving substantially better performance than prior SOTA methods with fewer than 30,000 training images, less than 10% of their training data, and only 5 epochs in each training stage.
Enhancing Self-Supervised Talking Head Forgery Detection via a Training-Free Dual-System Framework
May 05, 2026Supervised talking head forgery detection faces severe generalization challenges due to the continuous evolution of generators. By reducing reliance on generator-specific forgery patterns, self-supervised detectors offer stronger cross-generator robustness. However, existing research has mainly focused on building stronger detectors, while the discriminative capacity of trained detectors remains insufficiently exploited. In particular, for score-based self-supervised detectors, the limited discriminative ability on hard cases is often reflected in unreliable anomaly ordering, leaving room for further refinement. Motivated by this observation, we draw inspiration from the dual-system theory of human cognition and propose a Training-Free Dual-System (TFDS) framework to further exploit the latent discriminative capacity of existing score-based self-supervised detectors. TFDS treats anomaly-like scores as the basis of System-1, using lightweight threshold-based routing to partition samples into confident and uncertain subsets. System-2 then revisits only the uncertain subset, performing fine-grained evidence-guided reasoning to refine the relative ordering of ambiguous samples within the original score distribution. Extensive experiments demonstrate consistent improvements across datasets and perturbation settings, with the gains arising mainly from corrected ordering within the uncertain subset. These findings show that existing self-supervised talking head forgery detectors still contain underexploited discriminative cues that can be effectively unlocked through training-free dual-system reasoning.
MASRA: MLLM-Assisted Semantic-Relational Consistent Alignment for Video Temporal Grounding
May 05, 2026Video Temporal Grounding (VTG) faces a cross-modal semantic gap that often leads to background features being incorrectly aligned with the query, while directly matching the query to moments results in insufficient discriminability and consistency of temporal semantics. To address this issue, we propose MLLM-Assisted Semantic-Relational Consistent Alignment (MASRA), a training-time MLLM-based optimization framework for VTG. MASRA leverages an MLLM during training to produce two forms of textual priors, namely event-level descriptions with temporal spans and clip-level captions, and instantiates two MLLM-assisted alignments. Event Semantic Temporal Alignment (ESTA) aligns temporal context with event semantics to explicitly strengthen the correspondence between semantics and temporal events and improve span-level separability. Local Relational Consistency Alignment (LRCA) constructs a textual relation matrix derived from clip-level captions and aligns it with the temporal feature similarity matrix in the model, enhancing temporal consistency while capturing local structural information. MASRA includes two simple supporting modules, semantic-guided enhancement and second-order relational attention, to better utilize the learned semantic context and relational structure. Moreover, we introduce Decoupled Alignment Interaction (DAI) with a context-aware codebook to adaptively absorb query-irrelevant semantics and alleviate the cross-modal gap. The MLLM is only invoked during training and is not used at inference. Extensive experiments show that MASRA outperforms existing methods, and ablation studies validate its effectiveness.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025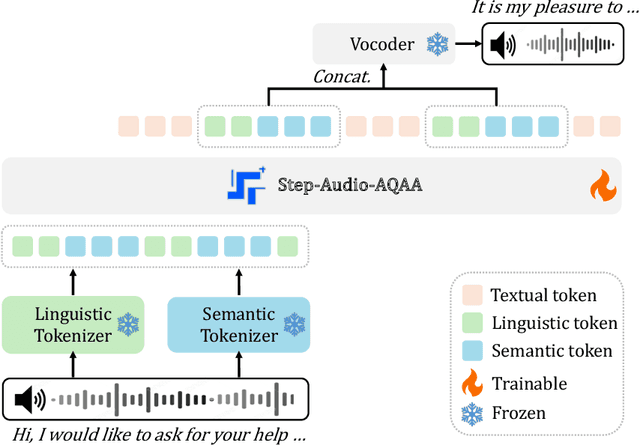
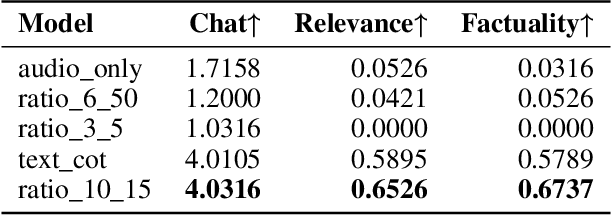
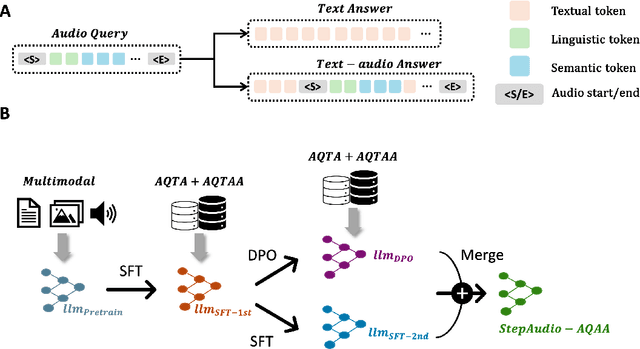

Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
DialogueReason: Rule-Based RL Sparks Dialogue Reasoning in LLMs
May 11, 2025We propose DialogueReason, a reasoning paradigm that uncovers the lost roles in monologue-style reasoning models, aiming to boost diversity and coherency of the reasoning process. Recent advances in RL-based large reasoning models have led to impressive long CoT capabilities and high performance on math and science benchmarks. However, these reasoning models rely mainly on monologue-style reasoning, which often limits reasoning diversity and coherency, frequently recycling fixed strategies or exhibiting unnecessary shifts in attention. Our work consists of an analysis of monologue reasoning patterns and the development of a dialogue-based reasoning approach. We first introduce the Compound-QA task, which concatenates multiple problems into a single prompt to assess both diversity and coherency of reasoning. Our analysis shows that Compound-QA exposes weaknesses in monologue reasoning, evidenced by both quantitative metrics and qualitative reasoning traces. Building on the analysis, we propose a dialogue-based reasoning, named DialogueReason, structured around agents, environment, and interactions. Using PPO with rule-based rewards, we train open-source LLMs (Qwen-QWQ and Qwen-Base) to adopt dialogue reasoning. We evaluate trained models on MATH, AIME, and GPQA datasets, showing that the dialogue reasoning model outperforms monologue models under more complex compound questions. Additionally, we discuss how dialogue-based reasoning helps enhance interpretability, facilitate more intuitive human interaction, and inspire advances in multi-agent system design.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
InPK: Infusing Prior Knowledge into Prompt for Vision-Language Models
Feb 27, 2025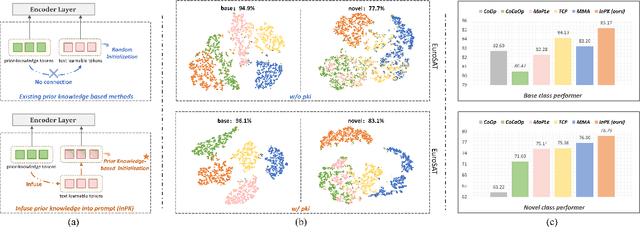



Prompt tuning has become a popular strategy for adapting Vision-Language Models (VLMs) to zero/few-shot visual recognition tasks. Some prompting techniques introduce prior knowledge due to its richness, but when learnable tokens are randomly initialized and disconnected from prior knowledge, they tend to overfit on seen classes and struggle with domain shifts for unseen ones. To address this issue, we propose the InPK model, which infuses class-specific prior knowledge into the learnable tokens during initialization, thus enabling the model to explicitly focus on class-relevant information. Furthermore, to mitigate the weakening of class information by multi-layer encoders, we continuously reinforce the interaction between learnable tokens and prior knowledge across multiple feature levels. This progressive interaction allows the learnable tokens to better capture the fine-grained differences and universal visual concepts within prior knowledge, enabling the model to extract more discriminative and generalized text features. Even for unseen classes, the learned interaction allows the model to capture their common representations and infer their appropriate positions within the existing semantic structure. Moreover, we introduce a learnable text-to-vision projection layer to accommodate the text adjustments, ensuring better alignment of visual-text semantics. Extensive experiments on 11 recognition datasets show that InPK significantly outperforms state-of-the-art methods in multiple zero/few-shot image classification tasks.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
CoSER: Coordinating LLM-Based Persona Simulation of Established Roles
Feb 13, 2025Role-playing language agents (RPLAs) have emerged as promising applications of large language models (LLMs). However, simulating established characters presents a challenging task for RPLAs, due to the lack of authentic character datasets and nuanced evaluation methods using such data. In this paper, we present CoSER, a collection of a high-quality dataset, open models, and an evaluation protocol towards effective RPLAs of established characters. The CoSER dataset covers 17,966 characters from 771 renowned books. It provides authentic dialogues with real-world intricacies, as well as diverse data types such as conversation setups, character experiences and internal thoughts. Drawing from acting methodology, we introduce given-circumstance acting for training and evaluating role-playing LLMs, where LLMs sequentially portray multiple characters in book scenes. Using our dataset, we develop CoSER 8B and CoSER 70B, i.e., advanced open role-playing LLMs built on LLaMA-3.1 models. Extensive experiments demonstrate the value of the CoSER dataset for RPLA training, evaluation and retrieval. Moreover, CoSER 70B exhibits state-of-the-art performance surpassing or matching GPT-4o on our evaluation and three existing benchmarks, i.e., achieving 75.80% and 93.47% accuracy on the InCharacter and LifeChoice benchmarks respectively.