 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReWorld: Multi-Dimensional Reward Modeling for Embodied World Models
Jan 18, 2026Recently, video-based world models that learn to simulate the dynamics have gained increasing attention in robot learning. However, current approaches primarily emphasize visual generative quality while overlooking physical fidelity, dynamic consistency, and task logic, especially for contact-rich manipulation tasks, which limits their applicability to downstream tasks. To this end, we introduce ReWorld, a framework aimed to employ reinforcement learning to align the video-based embodied world models with physical realism, task completion capability, embodiment plausibility and visual quality. Specifically, we first construct a large-scale (~235K) video preference dataset and employ it to train a hierarchical reward model designed to capture multi-dimensional reward consistent with human preferences. We further propose a practical alignment algorithm that post-trains flow-based world models using this reward through a computationally efficient PPO-style algorithm. Comprehensive experiments and theoretical analysis demonstrate that ReWorld significantly improves the physical fidelity, logical coherence, embodiment and visual quality of generated rollouts, outperforming previous methods.
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Dec 11, 2025Generative world models are reshaping embodied AI, enabling agents to synthesize realistic 4D driving environments that look convincing but often fail physically or behaviorally. Despite rapid progress, the field still lacks a unified way to assess whether generated worlds preserve geometry, obey physics, or support reliable control. We introduce WorldLens, a full-spectrum benchmark evaluating how well a model builds, understands, and behaves within its generated world. It spans five aspects -- Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference -- jointly covering visual realism, geometric consistency, physical plausibility, and functional reliability. Across these dimensions, no existing world model excels universally: those with strong textures often violate physics, while geometry-stable ones lack behavioral fidelity. To align objective metrics with human judgment, we further construct WorldLens-26K, a large-scale dataset of human-annotated videos with numerical scores and textual rationales, and develop WorldLens-Agent, an evaluation model distilled from these annotations to enable scalable, explainable scoring. Together, the benchmark, dataset, and agent form a unified ecosystem for measuring world fidelity -- standardizing how future models are judged not only by how real they look, but by how real they behave.
Scaling Up Occupancy-centric Driving Scene Generation: Dataset and Method
Oct 27, 2025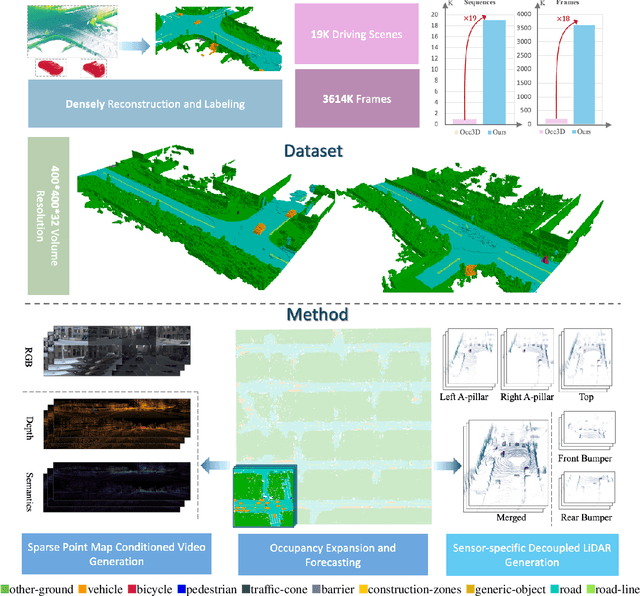
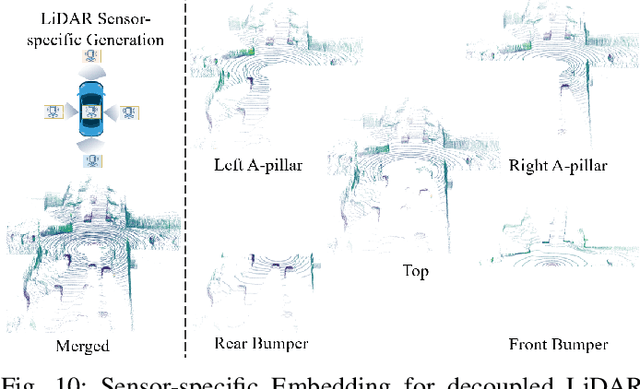

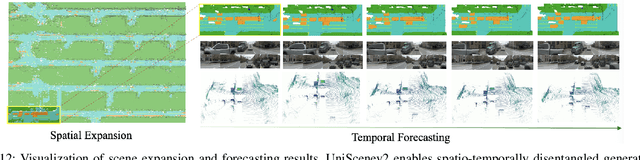
Driving scene generation is a critical domain for autonomous driving, enabling downstream applications, including perception and planning evaluation. Occupancy-centric methods have recently achieved state-of-the-art results by offering consistent conditioning across frames and modalities; however, their performance heavily depends on annotated occupancy data, which still remains scarce. To overcome this limitation, we curate Nuplan-Occ, the largest semantic occupancy dataset to date, constructed from the widely used Nuplan benchmark. Its scale and diversity facilitate not only large-scale generative modeling but also autonomous driving downstream applications. Based on this dataset, we develop a unified framework that jointly synthesizes high-quality semantic occupancy, multi-view videos, and LiDAR point clouds. Our approach incorporates a spatio-temporal disentangled architecture to support high-fidelity spatial expansion and temporal forecasting of 4D dynamic occupancy. To bridge modal gaps, we further propose two novel techniques: a Gaussian splatting-based sparse point map rendering strategy that enhances multi-view video generation, and a sensor-aware embedding strategy that explicitly models LiDAR sensor properties for realistic multi-LiDAR simulation. Extensive experiments demonstrate that our method achieves superior generation fidelity and scalability compared to existing approaches, and validates its practical value in downstream tasks. Repo: https://github.com/Arlo0o/UniScene-Unified-Occupancy-centric-Driving-Scene-Generation/tree/v2
UniScene: Unified Occupancy-centric Driving Scene Generation
Dec 06, 2024Generating high-fidelity, controllable, and annotated training data is critical for autonomous driving. Existing methods typically generate a single data form directly from a coarse scene layout, which not only fails to output rich data forms required for diverse downstream tasks but also struggles to model the direct layout-to-data distribution. In this paper, we introduce UniScene, the first unified framework for generating three key data forms - semantic occupancy, video, and LiDAR - in driving scenes. UniScene employs a progressive generation process that decomposes the complex task of scene generation into two hierarchical steps: (a) first generating semantic occupancy from a customized scene layout as a meta scene representation rich in both semantic and geometric information, and then (b) conditioned on occupancy, generating video and LiDAR data, respectively, with two novel transfer strategies of Gaussian-based Joint Rendering and Prior-guided Sparse Modeling. This occupancy-centric approach reduces the generation burden, especially for intricate scenes, while providing detailed intermediate representations for the subsequent generation stages. Extensive experiments demonstrate that UniScene outperforms previous SOTAs in the occupancy, video, and LiDAR generation, which also indeed benefits downstream driving tasks.
MSSF: A 4D Radar and Camera Fusion Framework With Multi-Stage Sampling for 3D Object Detection in Autonomous Driving
Nov 22, 2024

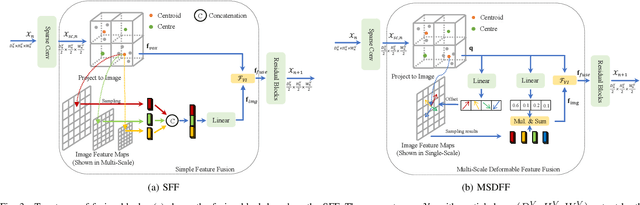

As one of the automotive sensors that have emerged in recent years, 4D millimeter-wave radar has a higher resolution than conventional 3D radar and provides precise elevation measurements. But its point clouds are still sparse and noisy, making it challenging to meet the requirements of autonomous driving. Camera, as another commonly used sensor, can capture rich semantic information. As a result, the fusion of 4D radar and camera can provide an affordable and robust perception solution for autonomous driving systems. However, previous radar-camera fusion methods have not yet been thoroughly investigated, resulting in a large performance gap compared to LiDAR-based methods. Specifically, they ignore the feature-blurring problem and do not deeply interact with image semantic information. To this end, we present a simple but effective multi-stage sampling fusion (MSSF) network based on 4D radar and camera. On the one hand, we design a fusion block that can deeply interact point cloud features with image features, and can be applied to commonly used single-modal backbones in a plug-and-play manner. The fusion block encompasses two types, namely, simple feature fusion (SFF) and multiscale deformable feature fusion (MSDFF). The SFF is easy to implement, while the MSDFF has stronger fusion abilities. On the other hand, we propose a semantic-guided head to perform foreground-background segmentation on voxels with voxel feature re-weighting, further alleviating the problem of feature blurring. Extensive experiments on the View-of-Delft (VoD) and TJ4DRadset datasets demonstrate the effectiveness of our MSSF. Notably, compared to state-of-the-art methods, MSSF achieves a 7.0% and 4.0% improvement in 3D mean average precision on the VoD and TJ4DRadSet datasets, respectively. It even surpasses classical LiDAR-based methods on the VoD dataset.