 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Future Temporal Knowledge with Masked Feature Reconstruction for 3D Object Detection
Dec 09, 2025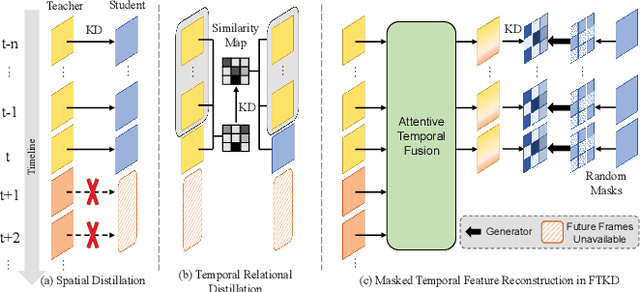
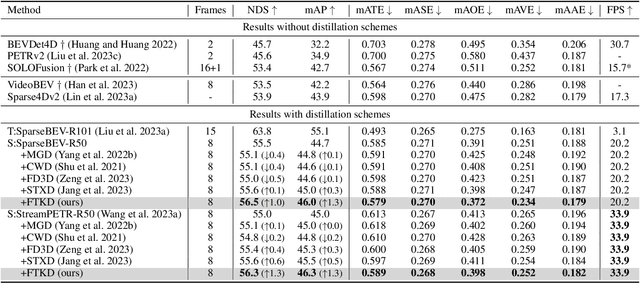
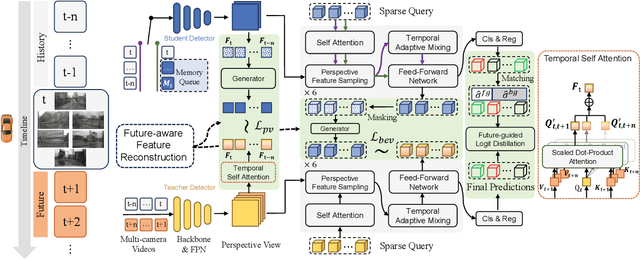
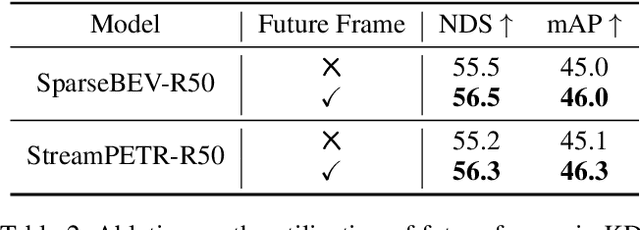
Camera-based temporal 3D object detection has shown impressive results in autonomous driving, with offline models improving accuracy by using future frames. Knowledge distillation (KD) can be an appealing framework for transferring rich information from offline models to online models. However, existing KD methods overlook future frames, as they mainly focus on spatial feature distillation under strict frame alignment or on temporal relational distillation, thereby making it challenging for online models to effectively learn future knowledge. To this end, we propose a sparse query-based approach, Future Temporal Knowledge Distillation (FTKD), which effectively transfers future frame knowledge from an offline teacher model to an online student model. Specifically, we present a future-aware feature reconstruction strategy to encourage the student model to capture future features without strict frame alignment. In addition, we further introduce future-guided logit distillation to leverage the teacher's stable foreground and background context. FTKD is applied to two high-performing 3D object detection baselines, achieving up to 1.3 mAP and 1.3 NDS gains on the nuScenes dataset, as well as the most accurate velocity estimation, without increasing inference cost.
Scaling Up Occupancy-centric Driving Scene Generation: Dataset and Method
Oct 27, 2025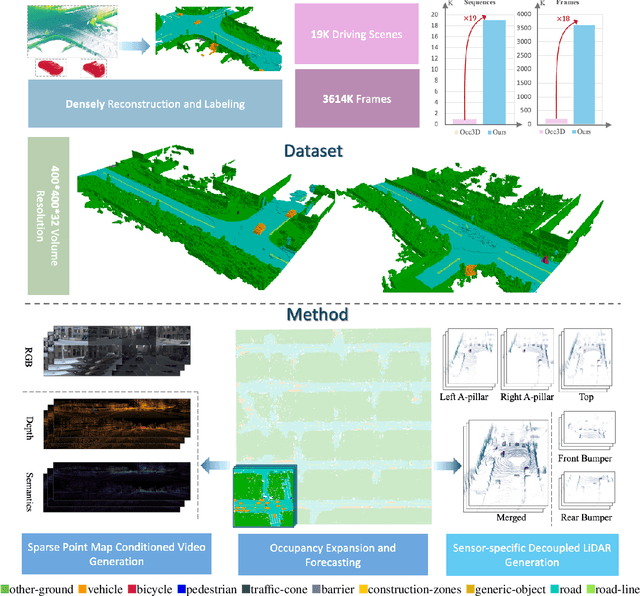
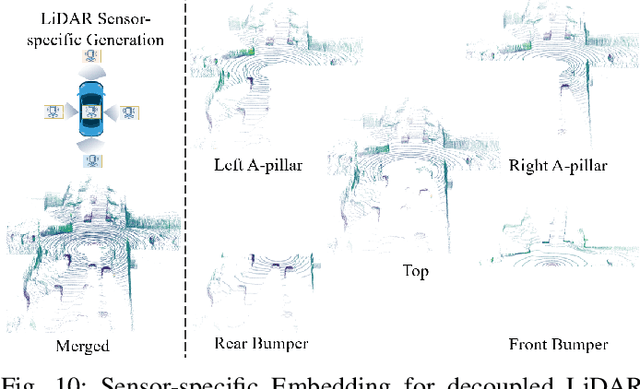

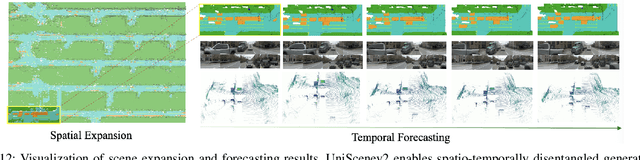
Driving scene generation is a critical domain for autonomous driving, enabling downstream applications, including perception and planning evaluation. Occupancy-centric methods have recently achieved state-of-the-art results by offering consistent conditioning across frames and modalities; however, their performance heavily depends on annotated occupancy data, which still remains scarce. To overcome this limitation, we curate Nuplan-Occ, the largest semantic occupancy dataset to date, constructed from the widely used Nuplan benchmark. Its scale and diversity facilitate not only large-scale generative modeling but also autonomous driving downstream applications. Based on this dataset, we develop a unified framework that jointly synthesizes high-quality semantic occupancy, multi-view videos, and LiDAR point clouds. Our approach incorporates a spatio-temporal disentangled architecture to support high-fidelity spatial expansion and temporal forecasting of 4D dynamic occupancy. To bridge modal gaps, we further propose two novel techniques: a Gaussian splatting-based sparse point map rendering strategy that enhances multi-view video generation, and a sensor-aware embedding strategy that explicitly models LiDAR sensor properties for realistic multi-LiDAR simulation. Extensive experiments demonstrate that our method achieves superior generation fidelity and scalability compared to existing approaches, and validates its practical value in downstream tasks. Repo: https://github.com/Arlo0o/UniScene-Unified-Occupancy-centric-Driving-Scene-Generation/tree/v2
Interpretable Single-View 3D Gaussian Splatting using Unsupervised Hierarchical Disentangled Representation Learning
Apr 05, 2025Gaussian Splatting (GS) has recently marked a significant advancement in 3D reconstruction, delivering both rapid rendering and high-quality results. However, existing 3DGS methods pose challenges in understanding underlying 3D semantics, which hinders model controllability and interpretability. To address it, we propose an interpretable single-view 3DGS framework, termed 3DisGS, to discover both coarse- and fine-grained 3D semantics via hierarchical disentangled representation learning (DRL). Specifically, the model employs a dual-branch architecture, consisting of a point cloud initialization branch and a triplane-Gaussian generation branch, to achieve coarse-grained disentanglement by separating 3D geometry and visual appearance features. Subsequently, fine-grained semantic representations within each modality are further discovered through DRL-based encoder-adapters. To our knowledge, this is the first work to achieve unsupervised interpretable 3DGS. Evaluations indicate that our model achieves 3D disentanglement while preserving high-quality and rapid reconstruction.
UniScene: Unified Occupancy-centric Driving Scene Generation
Dec 06, 2024Generating high-fidelity, controllable, and annotated training data is critical for autonomous driving. Existing methods typically generate a single data form directly from a coarse scene layout, which not only fails to output rich data forms required for diverse downstream tasks but also struggles to model the direct layout-to-data distribution. In this paper, we introduce UniScene, the first unified framework for generating three key data forms - semantic occupancy, video, and LiDAR - in driving scenes. UniScene employs a progressive generation process that decomposes the complex task of scene generation into two hierarchical steps: (a) first generating semantic occupancy from a customized scene layout as a meta scene representation rich in both semantic and geometric information, and then (b) conditioned on occupancy, generating video and LiDAR data, respectively, with two novel transfer strategies of Gaussian-based Joint Rendering and Prior-guided Sparse Modeling. This occupancy-centric approach reduces the generation burden, especially for intricate scenes, while providing detailed intermediate representations for the subsequent generation stages. Extensive experiments demonstrate that UniScene outperforms previous SOTAs in the occupancy, video, and LiDAR generation, which also indeed benefits downstream driving tasks.
Bridge the Domain Gap Between Ultra-wide-field and Traditional Fundus Images via Adversarial Domain Adaptation
Mar 24, 2020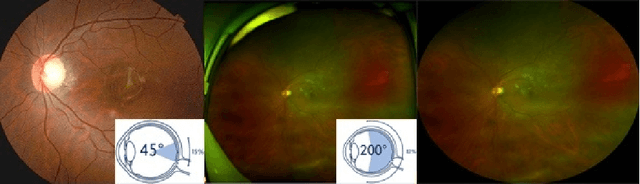

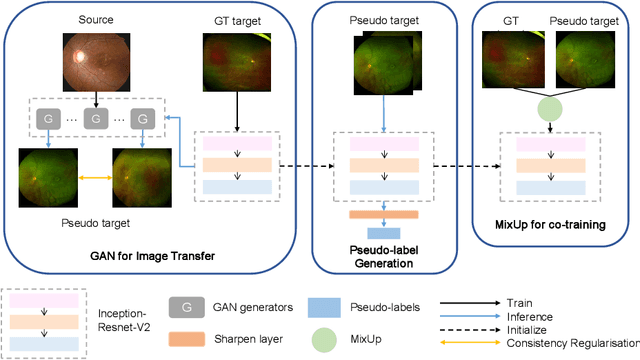
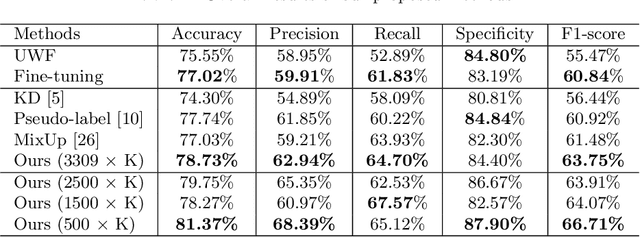
For decades, advances in retinal imaging technology have enabled effective diagnosis and management of retinal disease using fundus cameras. Recently, ultra-wide-field (UWF) fundus imaging by Optos camera is gradually put into use because of its broader insights on fundus for some lesions that are not typically seen in traditional fundus images. Research on traditional fundus images is an active topic but studies on UWF fundus images are few. One of the most important reasons is that UWF fundus images are hard to obtain. In this paper, for the first time, we explore domain adaptation from the traditional fundus to UWF fundus images. We propose a flexible framework to bridge the domain gap between two domains and co-train a UWF fundus diagnosis model by pseudo-labelling and adversarial learning. We design a regularisation technique to regulate the domain adaptation. Also, we apply MixUp to overcome the over-fitting issue from incorrect generated pseudo-labels. Our experimental results on either single or both domains demonstrate that the proposed method can well adapt and transfer the knowledge from traditional fundus images to UWF fundus images and improve the performance of retinal disease recognition.