 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiST-4D: Disentangled Spatiotemporal Diffusion with Metric Depth for 4D Driving Scene Generation
Mar 19, 2025



Current generative models struggle to synthesize dynamic 4D driving scenes that simultaneously support temporal extrapolation and spatial novel view synthesis (NVS) without per-scene optimization. A key challenge lies in finding an efficient and generalizable geometric representation that seamlessly connects temporal and spatial synthesis. To address this, we propose DiST-4D, the first disentangled spatiotemporal diffusion framework for 4D driving scene generation, which leverages metric depth as the core geometric representation. DiST-4D decomposes the problem into two diffusion processes: DiST-T, which predicts future metric depth and multi-view RGB sequences directly from past observations, and DiST-S, which enables spatial NVS by training only on existing viewpoints while enforcing cycle consistency. This cycle consistency mechanism introduces a forward-backward rendering constraint, reducing the generalization gap between observed and unseen viewpoints. Metric depth is essential for both accurate reliable forecasting and accurate spatial NVS, as it provides a view-consistent geometric representation that generalizes well to unseen perspectives. Experiments demonstrate that DiST-4D achieves state-of-the-art performance in both temporal prediction and NVS tasks, while also delivering competitive performance in planning-related evaluations.
MuDG: Taming Multi-modal Diffusion with Gaussian Splatting for Urban Scene Reconstruction
Mar 13, 2025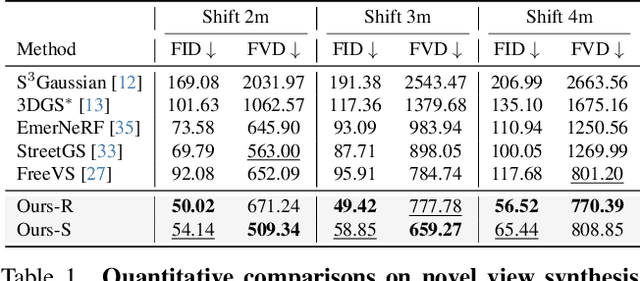
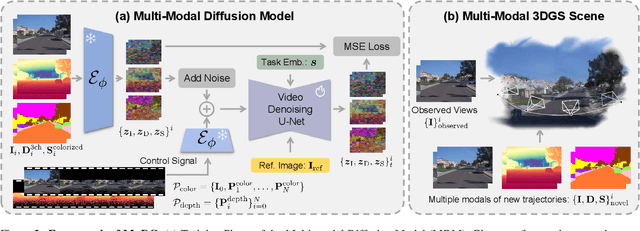
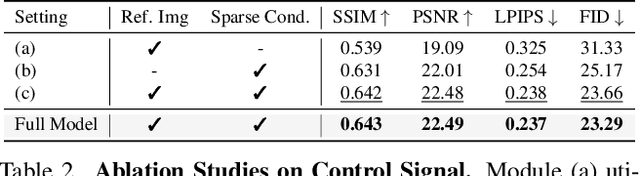
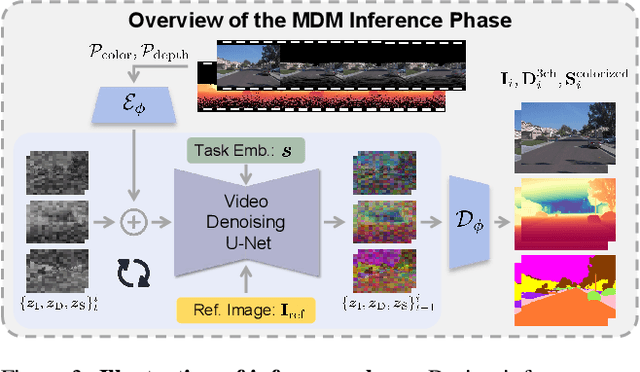
Recent breakthroughs in radiance fields have significantly advanced 3D scene reconstruction and novel view synthesis (NVS) in autonomous driving. Nevertheless, critical limitations persist: reconstruction-based methods exhibit substantial performance deterioration under significant viewpoint deviations from training trajectories, while generation-based techniques struggle with temporal coherence and precise scene controllability. To overcome these challenges, we present MuDG, an innovative framework that integrates Multi-modal Diffusion model with Gaussian Splatting (GS) for Urban Scene Reconstruction. MuDG leverages aggregated LiDAR point clouds with RGB and geometric priors to condition a multi-modal video diffusion model, synthesizing photorealistic RGB, depth, and semantic outputs for novel viewpoints. This synthesis pipeline enables feed-forward NVS without computationally intensive per-scene optimization, providing comprehensive supervision signals to refine 3DGS representations for rendering robustness enhancement under extreme viewpoint changes. Experiments on the Open Waymo Dataset demonstrate that MuDG outperforms existing methods in both reconstruction and synthesis quality.
SLGaussian: Fast Language Gaussian Splatting in Sparse Views
Dec 11, 20243D semantic field learning is crucial for applications like autonomous navigation, AR/VR, and robotics, where accurate comprehension of 3D scenes from limited viewpoints is essential. Existing methods struggle under sparse view conditions, relying on inefficient per-scene multi-view optimizations, which are impractical for many real-world tasks. To address this, we propose SLGaussian, a feed-forward method for constructing 3D semantic fields from sparse viewpoints, allowing direct inference of 3DGS-based scenes. By ensuring consistent SAM segmentations through video tracking and using low-dimensional indexing for high-dimensional CLIP features, SLGaussian efficiently embeds language information in 3D space, offering a robust solution for accurate 3D scene understanding under sparse view conditions. In experiments on two-view sparse 3D object querying and segmentation in the LERF and 3D-OVS datasets, SLGaussian outperforms existing methods in chosen IoU, Localization Accuracy, and mIoU. Moreover, our model achieves scene inference in under 30 seconds and open-vocabulary querying in just 0.011 seconds per query.
UniScene: Unified Occupancy-centric Driving Scene Generation
Dec 06, 2024Generating high-fidelity, controllable, and annotated training data is critical for autonomous driving. Existing methods typically generate a single data form directly from a coarse scene layout, which not only fails to output rich data forms required for diverse downstream tasks but also struggles to model the direct layout-to-data distribution. In this paper, we introduce UniScene, the first unified framework for generating three key data forms - semantic occupancy, video, and LiDAR - in driving scenes. UniScene employs a progressive generation process that decomposes the complex task of scene generation into two hierarchical steps: (a) first generating semantic occupancy from a customized scene layout as a meta scene representation rich in both semantic and geometric information, and then (b) conditioned on occupancy, generating video and LiDAR data, respectively, with two novel transfer strategies of Gaussian-based Joint Rendering and Prior-guided Sparse Modeling. This occupancy-centric approach reduces the generation burden, especially for intricate scenes, while providing detailed intermediate representations for the subsequent generation stages. Extensive experiments demonstrate that UniScene outperforms previous SOTAs in the occupancy, video, and LiDAR generation, which also indeed benefits downstream driving tasks.
TranSplat: Generalizable 3D Gaussian Splatting from Sparse Multi-View Images with Transformers
Aug 25, 2024



Compared with previous 3D reconstruction methods like Nerf, recent Generalizable 3D Gaussian Splatting (G-3DGS) methods demonstrate impressive efficiency even in the sparse-view setting. However, the promising reconstruction performance of existing G-3DGS methods relies heavily on accurate multi-view feature matching, which is quite challenging. Especially for the scenes that have many non-overlapping areas between various views and contain numerous similar regions, the matching performance of existing methods is poor and the reconstruction precision is limited. To address this problem, we develop a strategy that utilizes a predicted depth confidence map to guide accurate local feature matching. In addition, we propose to utilize the knowledge of existing monocular depth estimation models as prior to boost the depth estimation precision in non-overlapping areas between views. Combining the proposed strategies, we present a novel G-3DGS method named TranSplat, which obtains the best performance on both the RealEstate10K and ACID benchmarks while maintaining competitive speed and presenting strong cross-dataset generalization ability. Our code, and demos will be available at: https://xingyoujun.github.io/transplat.
M${^2}$Depth: Self-supervised Two-Frame Multi-camera Metric Depth Estimation
May 03, 2024
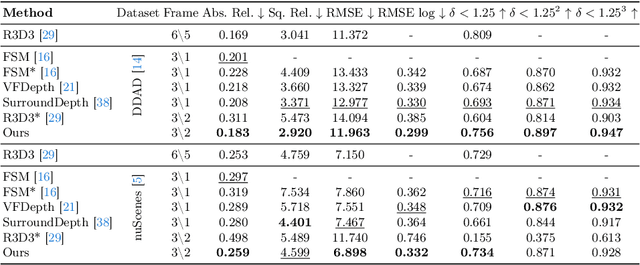
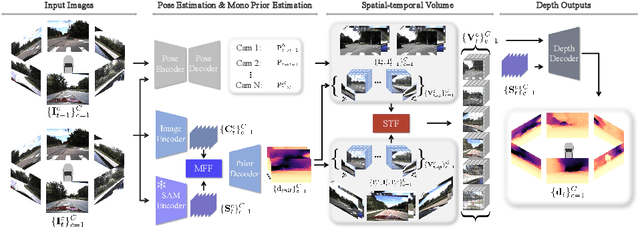
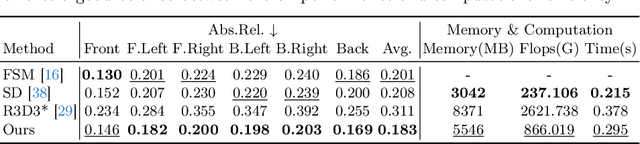
This paper presents a novel self-supervised two-frame multi-camera metric depth estimation network, termed M${^2}$Depth, which is designed to predict reliable scale-aware surrounding depth in autonomous driving. Unlike the previous works that use multi-view images from a single time-step or multiple time-step images from a single camera, M${^2}$Depth takes temporally adjacent two-frame images from multiple cameras as inputs and produces high-quality surrounding depth. We first construct cost volumes in spatial and temporal domains individually and propose a spatial-temporal fusion module that integrates the spatial-temporal information to yield a strong volume presentation. We additionally combine the neural prior from SAM features with internal features to reduce the ambiguity between foreground and background and strengthen the depth edges. Extensive experimental results on nuScenes and DDAD benchmarks show M${^2}$Depth achieves state-of-the-art performance. More results can be found in https://heiheishuang.xyz/M2Depth .
3D Face Arbitrary Style Transfer
Mar 14, 2023



Style transfer of 3D faces has gained more and more attention. However, previous methods mainly use images of artistic faces for style transfer while ignoring arbitrary style images such as abstract paintings. To solve this problem, we propose a novel method, namely Face-guided Dual Style Transfer (FDST). To begin with, FDST employs a 3D decoupling module to separate facial geometry and texture. Then we propose a style fusion strategy for facial geometry. Subsequently, we design an optimization-based DDSG mechanism for textures that can guide the style transfer by two style images. Besides the normal style image input, DDSG can utilize the original face input as another style input as the face prior. By this means, high-quality face arbitrary style transfer results can be obtained. Furthermore, FDST can be applied in many downstream tasks, including region-controllable style transfer, high-fidelity face texture reconstruction, large-pose face reconstruction, and artistic face reconstruction. Comprehensive quantitative and qualitative results show that our method can achieve comparable performance. All source codes and pre-trained weights will be released to the public.