 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshCoder: LLM-Powered Structured Mesh Code Generation from Point Clouds
Aug 20, 2025Reconstructing 3D objects into editable programs is pivotal for applications like reverse engineering and shape editing. However, existing methods often rely on limited domain-specific languages (DSLs) and small-scale datasets, restricting their ability to model complex geometries and structures. To address these challenges, we introduce MeshCoder, a novel framework that reconstructs complex 3D objects from point clouds into editable Blender Python scripts. We develop a comprehensive set of expressive Blender Python APIs capable of synthesizing intricate geometries. Leveraging these APIs, we construct a large-scale paired object-code dataset, where the code for each object is decomposed into distinct semantic parts. Subsequently, we train a multimodal large language model (LLM) that translates 3D point cloud into executable Blender Python scripts. Our approach not only achieves superior performance in shape-to-code reconstruction tasks but also facilitates intuitive geometric and topological editing through convenient code modifications. Furthermore, our code-based representation enhances the reasoning capabilities of LLMs in 3D shape understanding tasks. Together, these contributions establish MeshCoder as a powerful and flexible solution for programmatic 3D shape reconstruction and understanding.
NOVA3D: Normal Aligned Video Diffusion Model for Single Image to 3D Generation
Jun 09, 2025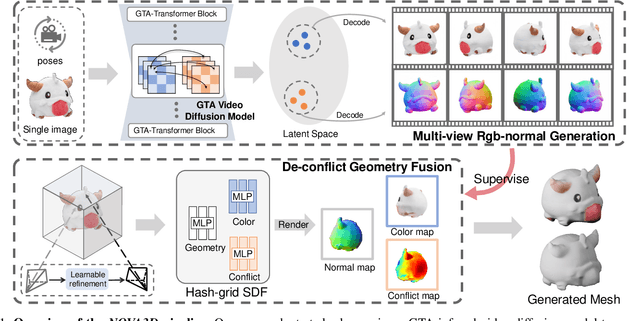
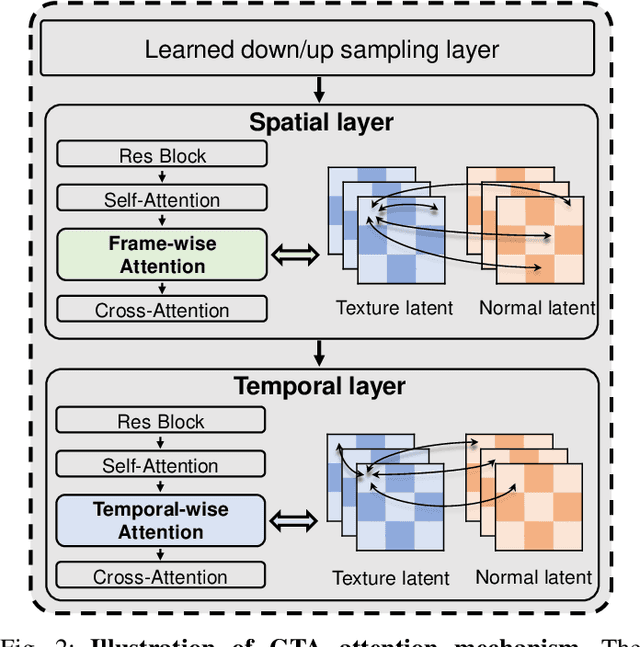


3D AI-generated content (AIGC) has made it increasingly accessible for anyone to become a 3D content creator. While recent methods leverage Score Distillation Sampling to distill 3D objects from pretrained image diffusion models, they often suffer from inadequate 3D priors, leading to insufficient multi-view consistency. In this work, we introduce NOVA3D, an innovative single-image-to-3D generation framework. Our key insight lies in leveraging strong 3D priors from a pretrained video diffusion model and integrating geometric information during multi-view video fine-tuning. To facilitate information exchange between color and geometric domains, we propose the Geometry-Temporal Alignment (GTA) attention mechanism, thereby improving generalization and multi-view consistency. Moreover, we introduce the de-conflict geometry fusion algorithm, which improves texture fidelity by addressing multi-view inaccuracies and resolving discrepancies in pose alignment. Extensive experiments validate the superiority of NOVA3D over existing baselines.
GUAVA: Generalizable Upper Body 3D Gaussian Avatar
May 06, 2025Reconstructing a high-quality, animatable 3D human avatar with expressive facial and hand motions from a single image has gained significant attention due to its broad application potential. 3D human avatar reconstruction typically requires multi-view or monocular videos and training on individual IDs, which is both complex and time-consuming. Furthermore, limited by SMPLX's expressiveness, these methods often focus on body motion but struggle with facial expressions. To address these challenges, we first introduce an expressive human model (EHM) to enhance facial expression capabilities and develop an accurate tracking method. Based on this template model, we propose GUAVA, the first framework for fast animatable upper-body 3D Gaussian avatar reconstruction. We leverage inverse texture mapping and projection sampling techniques to infer Ubody (upper-body) Gaussians from a single image. The rendered images are refined through a neural refiner. Experimental results demonstrate that GUAVA significantly outperforms previous methods in rendering quality and offers significant speed improvements, with reconstruction times in the sub-second range (0.1s), and supports real-time animation and rendering.
4D LangSplat: 4D Language Gaussian Splatting via Multimodal Large Language Models
Mar 13, 2025Learning 4D language fields to enable time-sensitive, open-ended language queries in dynamic scenes is essential for many real-world applications. While LangSplat successfully grounds CLIP features into 3D Gaussian representations, achieving precision and efficiency in 3D static scenes, it lacks the ability to handle dynamic 4D fields as CLIP, designed for static image-text tasks, cannot capture temporal dynamics in videos. Real-world environments are inherently dynamic, with object semantics evolving over time. Building a precise 4D language field necessitates obtaining pixel-aligned, object-wise video features, which current vision models struggle to achieve. To address these challenges, we propose 4D LangSplat, which learns 4D language fields to handle time-agnostic or time-sensitive open-vocabulary queries in dynamic scenes efficiently. 4D LangSplat bypasses learning the language field from vision features and instead learns directly from text generated from object-wise video captions via Multimodal Large Language Models (MLLMs). Specifically, we propose a multimodal object-wise video prompting method, consisting of visual and text prompts that guide MLLMs to generate detailed, temporally consistent, high-quality captions for objects throughout a video. These captions are encoded using a Large Language Model into high-quality sentence embeddings, which then serve as pixel-aligned, object-specific feature supervision, facilitating open-vocabulary text queries through shared embedding spaces. Recognizing that objects in 4D scenes exhibit smooth transitions across states, we further propose a status deformable network to model these continuous changes over time effectively. Our results across multiple benchmarks demonstrate that 4D LangSplat attains precise and efficient results for both time-sensitive and time-agnostic open-vocabulary queries.
HRAvatar: High-Quality and Relightable Gaussian Head Avatar
Mar 11, 2025Reconstructing animatable and high-quality 3D head avatars from monocular videos, especially with realistic relighting, is a valuable task. However, the limited information from single-view input, combined with the complex head poses and facial movements, makes this challenging. Previous methods achieve real-time performance by combining 3D Gaussian Splatting with a parametric head model, but the resulting head quality suffers from inaccurate face tracking and limited expressiveness of the deformation model. These methods also fail to produce realistic effects under novel lighting conditions. To address these issues, we propose HRAvatar, a 3DGS-based method that reconstructs high-fidelity, relightable 3D head avatars. HRAvatar reduces tracking errors through end-to-end optimization and better captures individual facial deformations using learnable blendshapes and learnable linear blend skinning. Additionally, it decomposes head appearance into several physical properties and incorporates physically-based shading to account for environmental lighting. Extensive experiments demonstrate that HRAvatar not only reconstructs superior-quality heads but also achieves realistic visual effects under varying lighting conditions.
SLGaussian: Fast Language Gaussian Splatting in Sparse Views
Dec 11, 20243D semantic field learning is crucial for applications like autonomous navigation, AR/VR, and robotics, where accurate comprehension of 3D scenes from limited viewpoints is essential. Existing methods struggle under sparse view conditions, relying on inefficient per-scene multi-view optimizations, which are impractical for many real-world tasks. To address this, we propose SLGaussian, a feed-forward method for constructing 3D semantic fields from sparse viewpoints, allowing direct inference of 3DGS-based scenes. By ensuring consistent SAM segmentations through video tracking and using low-dimensional indexing for high-dimensional CLIP features, SLGaussian efficiently embeds language information in 3D space, offering a robust solution for accurate 3D scene understanding under sparse view conditions. In experiments on two-view sparse 3D object querying and segmentation in the LERF and 3D-OVS datasets, SLGaussian outperforms existing methods in chosen IoU, Localization Accuracy, and mIoU. Moreover, our model achieves scene inference in under 30 seconds and open-vocabulary querying in just 0.011 seconds per query.
Category-level Object Detection, Pose Estimation and Reconstruction from Stereo Images
Jul 09, 2024We study the 3D object understanding task for manipulating everyday objects with different material properties (diffuse, specular, transparent and mixed). Existing monocular and RGB-D methods suffer from scale ambiguity due to missing or imprecise depth measurements. We present CODERS, a one-stage approach for Category-level Object Detection, pose Estimation and Reconstruction from Stereo images. The base of our pipeline is an implicit stereo matching module that combines stereo image features with 3D position information. Concatenating this presented module and the following transform-decoder architecture leads to end-to-end learning of multiple tasks required by robot manipulation. Our approach significantly outperforms all competing methods in the public TOD dataset. Furthermore, trained on simulated data, CODERS generalize well to unseen category-level object instances in real-world robot manipulation experiments. Our dataset, code, and demos will be available on our project page.
HDR-GS: Efficient High Dynamic Range Novel View Synthesis at 1000x Speed via Gaussian Splatting
May 27, 2024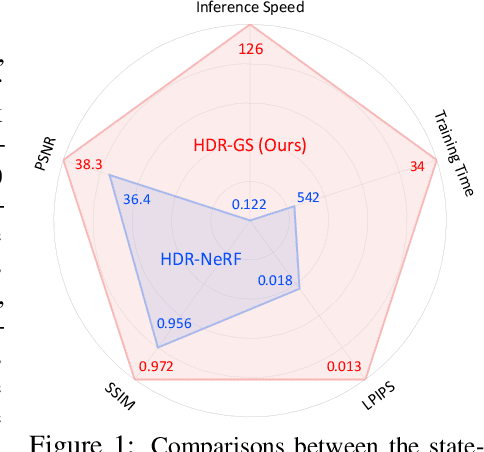
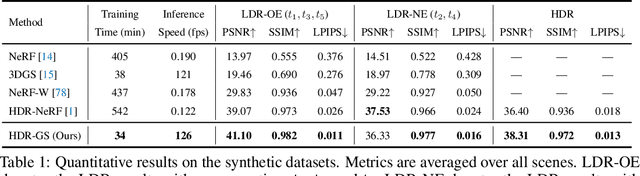

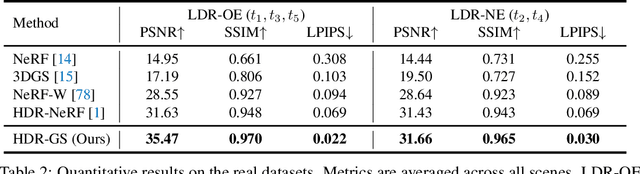
High dynamic range (HDR) novel view synthesis (NVS) aims to create photorealistic images from novel viewpoints using HDR imaging techniques. The rendered HDR images capture a wider range of brightness levels containing more details of the scene than normal low dynamic range (LDR) images. Existing HDR NVS methods are mainly based on NeRF. They suffer from long training time and slow inference speed. In this paper, we propose a new framework, High Dynamic Range Gaussian Splatting (HDR-GS), which can efficiently render novel HDR views and reconstruct LDR images with a user input exposure time. Specifically, we design a Dual Dynamic Range (DDR) Gaussian point cloud model that uses spherical harmonics to fit HDR color and employs an MLP-based tone-mapper to render LDR color. The HDR and LDR colors are then fed into two Parallel Differentiable Rasterization (PDR) processes to reconstruct HDR and LDR views. To establish the data foundation for the research of 3D Gaussian splatting-based methods in HDR NVS, we recalibrate the camera parameters and compute the initial positions for Gaussian point clouds. Experiments demonstrate that our HDR-GS surpasses the state-of-the-art NeRF-based method by 3.84 and 1.91 dB on LDR and HDR NVS while enjoying 1000x inference speed and only requiring 6.3% training time. Code, models, and recalibrated data will be publicly available at https://github.com/caiyuanhao1998/HDR-GS
Gaussian in the Wild: 3D Gaussian Splatting for Unconstrained Image Collections
Mar 23, 2024Novel view synthesis from unconstrained in-the-wild images remains a meaningful but challenging task. The photometric variation and transient occluders in those unconstrained images make it difficult to reconstruct the original scene accurately. Previous approaches tackle the problem by introducing a global appearance feature in Neural Radiance Fields (NeRF). However, in the real world, the unique appearance of each tiny point in a scene is determined by its independent intrinsic material attributes and the varying environmental impacts it receives. Inspired by this fact, we propose Gaussian in the wild (GS-W), a method that uses 3D Gaussian points to reconstruct the scene and introduces separated intrinsic and dynamic appearance feature for each point, capturing the unchanged scene appearance along with dynamic variation like illumination and weather. Additionally, an adaptive sampling strategy is presented to allow each Gaussian point to focus on the local and detailed information more effectively. We also reduce the impact of transient occluders using a 2D visibility map. More experiments have demonstrated better reconstruction quality and details of GS-W compared to previous methods, with a $1000\times$ increase in rendering speed.
LangSplat: 3D Language Gaussian Splatting
Dec 26, 2023Human lives in a 3D world and commonly uses natural language to interact with a 3D scene. Modeling a 3D language field to support open-ended language queries in 3D has gained increasing attention recently. This paper introduces LangSplat, which constructs a 3D language field that enables precise and efficient open-vocabulary querying within 3D spaces. Unlike existing methods that ground CLIP language embeddings in a NeRF model, LangSplat advances the field by utilizing a collection of 3D Gaussians, each encoding language features distilled from CLIP, to represent the language field. By employing a tile-based splatting technique for rendering language features, we circumvent the costly rendering process inherent in NeRF. Instead of directly learning CLIP embeddings, LangSplat first trains a scene-wise language autoencoder and then learns language features on the scene-specific latent space, thereby alleviating substantial memory demands imposed by explicit modeling. Existing methods struggle with imprecise and vague 3D language fields, which fail to discern clear boundaries between objects. We delve into this issue and propose to learn hierarchical semantics using SAM, thereby eliminating the need for extensively querying the language field across various scales and the regularization of DINO features. Extensive experiments on open-vocabulary 3D object localization and semantic segmentation demonstrate that LangSplat significantly outperforms the previous state-of-the-art method LERF by a large margin. Notably, LangSplat is extremely efficient, achieving a {\speed} $\times$ speedup compared to LERF at the resolution of 1440 $\times$ 1080. We strongly recommend readers to check out our video results at https://langsplat.github.io