 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimatable 3D Gaussian: Fast and High-Quality Reconstruction of Multiple Human Avatars
Paper and Code


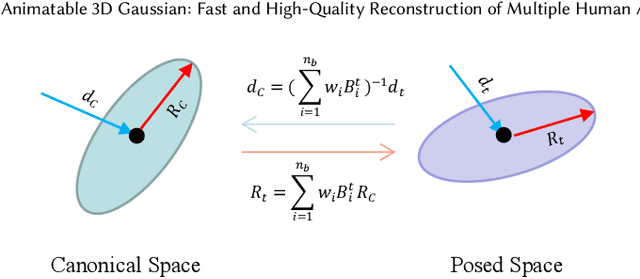

Neural radiance fields are capable of reconstructing high-quality drivable human avatars but are expensive to train and render. To reduce consumption, we propose Animatable 3D Gaussian, which learns human avatars from input images and poses. We extend 3D Gaussians to dynamic human scenes by modeling a set of skinned 3D Gaussians and a corresponding skeleton in canonical space and deforming 3D Gaussians to posed space according to the input poses. We introduce hash-encoded shape and appearance to speed up training and propose time-dependent ambient occlusion to achieve high-quality reconstructions in scenes containing complex motions and dynamic shadows. On both novel view synthesis and novel pose synthesis tasks, our method outperforms existing methods in terms of training time, rendering speed, and reconstruction quality. Our method can be easily extended to multi-human scenes and achieve comparable novel view synthesis results on a scene with ten people in only 25 seconds of training.