 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASR: Timestep-Aware Diffusion Model for Image Super-Resolution
Dec 04, 2024Diffusion models have recently achieved outstanding results in the field of image super-resolution. These methods typically inject low-resolution (LR) images via ControlNet.In this paper, we first explore the temporal dynamics of information infusion through ControlNet, revealing that the input from LR images predominantly influences the initial stages of the denoising process. Leveraging this insight, we introduce a novel timestep-aware diffusion model that adaptively integrates features from both ControlNet and the pre-trained Stable Diffusion (SD). Our method enhances the transmission of LR information in the early stages of diffusion to guarantee image fidelity and stimulates the generation ability of the SD model itself more in the later stages to enhance the detail of generated images. To train this method, we propose a timestep-aware training strategy that adopts distinct losses at varying timesteps and acts on disparate modules. Experiments on benchmark datasets demonstrate the effectiveness of our method. Code: https://github.com/SleepyLin/TASR
RFSR: Improving ISR Diffusion Models via Reward Feedback Learning
Dec 04, 2024Generative diffusion models (DM) have been extensively utilized in image super-resolution (ISR). Most of the existing methods adopt the denoising loss from DDPMs for model optimization. We posit that introducing reward feedback learning to finetune the existing models can further improve the quality of the generated images. In this paper, we propose a timestep-aware training strategy with reward feedback learning. Specifically, in the initial denoising stages of ISR diffusion, we apply low-frequency constraints to super-resolution (SR) images to maintain structural stability. In the later denoising stages, we use reward feedback learning to improve the perceptual and aesthetic quality of the SR images. In addition, we incorporate Gram-KL regularization to alleviate stylization caused by reward hacking. Our method can be integrated into any diffusion-based ISR model in a plug-and-play manner. Experiments show that ISR diffusion models, when fine-tuned with our method, significantly improve the perceptual and aesthetic quality of SR images, achieving excellent subjective results. Code: https://github.com/sxpro/RFSR
Monocular Gaussian SLAM with Language Extended Loop Closure
May 22, 2024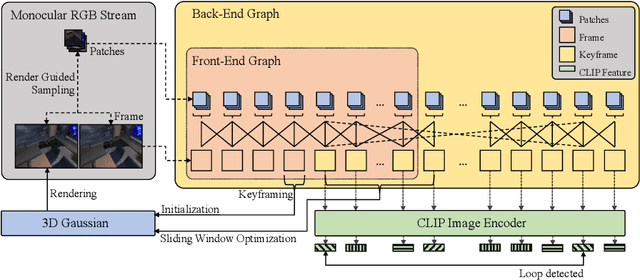



Recently,3DGaussianSplattinghasshowngreatpotentialin visual Simultaneous Localization And Mapping (SLAM). Existing methods have achieved encouraging results on RGB-D SLAM, but studies of the monocular case are still scarce. Moreover, they also fail to correct drift errors due to the lack of loop closure and global optimization. In this paper, we present MG-SLAM, a monocular Gaussian SLAM with a language-extended loop closure module capable of performing drift-corrected tracking and high-fidelity reconstruction while achieving a high-level understanding of the environment. Our key idea is to represent the global map as 3D Gaussian and use it to guide the estimation of the scene geometry, thus mitigating the efforts of missing depth information. Further, an additional language-extended loop closure module which is based on CLIP feature is designed to continually perform global optimization to correct drift errors accumulated as the system runs. Our system shows promising results on multiple challenging datasets in both tracking and mapping and even surpasses some existing RGB-D methods.
Animatable 3D Gaussian: Fast and High-Quality Reconstruction of Multiple Human Avatars
Nov 29, 2023

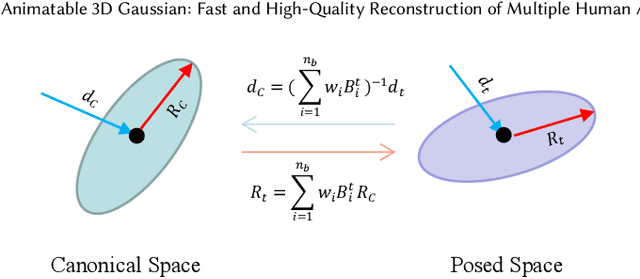

Neural radiance fields are capable of reconstructing high-quality drivable human avatars but are expensive to train and render. To reduce consumption, we propose Animatable 3D Gaussian, which learns human avatars from input images and poses. We extend 3D Gaussians to dynamic human scenes by modeling a set of skinned 3D Gaussians and a corresponding skeleton in canonical space and deforming 3D Gaussians to posed space according to the input poses. We introduce hash-encoded shape and appearance to speed up training and propose time-dependent ambient occlusion to achieve high-quality reconstructions in scenes containing complex motions and dynamic shadows. On both novel view synthesis and novel pose synthesis tasks, our method outperforms existing methods in terms of training time, rendering speed, and reconstruction quality. Our method can be easily extended to multi-human scenes and achieve comparable novel view synthesis results on a scene with ten people in only 25 seconds of training.
CIR-Net: Cross-modality Interaction and Refinement for RGB-D Salient Object Detection
Oct 06, 2022


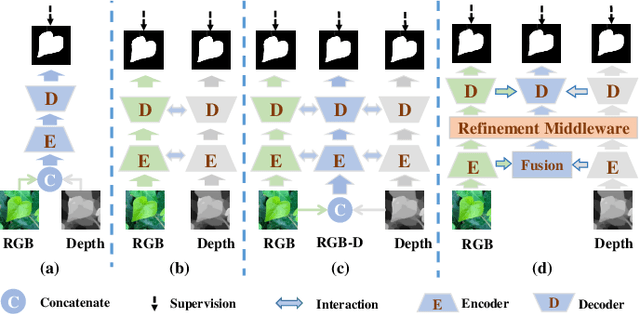
Focusing on the issue of how to effectively capture and utilize cross-modality information in RGB-D salient object detection (SOD) task, we present a convolutional neural network (CNN) model, named CIR-Net, based on the novel cross-modality interaction and refinement. For the cross-modality interaction, 1) a progressive attention guided integration unit is proposed to sufficiently integrate RGB-D feature representations in the encoder stage, and 2) a convergence aggregation structure is proposed, which flows the RGB and depth decoding features into the corresponding RGB-D decoding streams via an importance gated fusion unit in the decoder stage. For the cross-modality refinement, we insert a refinement middleware structure between the encoder and the decoder, in which the RGB, depth, and RGB-D encoder features are further refined by successively using a self-modality attention refinement unit and a cross-modality weighting refinement unit. At last, with the gradually refined features, we predict the saliency map in the decoder stage. Extensive experiments on six popular RGB-D SOD benchmarks demonstrate that our network outperforms the state-of-the-art saliency detectors both qualitatively and quantitatively.
Cross-modality Discrepant Interaction Network for RGB-D Salient Object Detection
Aug 04, 2021



The popularity and promotion of depth maps have brought new vigor and vitality into salient object detection (SOD), and a mass of RGB-D SOD algorithms have been proposed, mainly concentrating on how to better integrate cross-modality features from RGB image and depth map. For the cross-modality interaction in feature encoder, existing methods either indiscriminately treat RGB and depth modalities, or only habitually utilize depth cues as auxiliary information of the RGB branch. Different from them, we reconsider the status of two modalities and propose a novel Cross-modality Discrepant Interaction Network (CDINet) for RGB-D SOD, which differentially models the dependence of two modalities according to the feature representations of different layers. To this end, two components are designed to implement the effective cross-modality interaction: 1) the RGB-induced Detail Enhancement (RDE) module leverages RGB modality to enhance the details of the depth features in low-level encoder stage. 2) the Depth-induced Semantic Enhancement (DSE) module transfers the object positioning and internal consistency of depth features to the RGB branch in high-level encoder stage. Furthermore, we also design a Dense Decoding Reconstruction (DDR) structure, which constructs a semantic block by combining multi-level encoder features to upgrade the skip connection in the feature decoding. Extensive experiments on five benchmark datasets demonstrate that our network outperforms $15$ state-of-the-art methods both quantitatively and qualitatively. Our code is publicly available at: https://rmcong.github.io/proj_CDINet.html.