 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIR-Net: Cross-modality Interaction and Refinement for RGB-D Salient Object Detection
Paper and Code



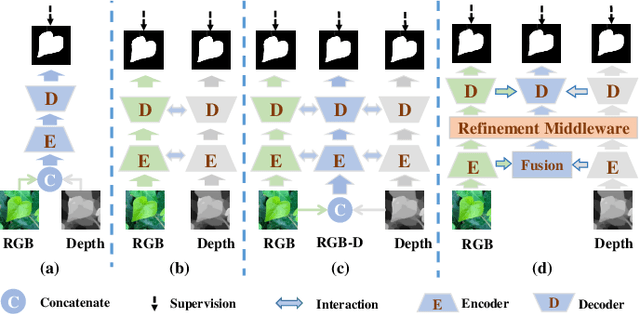
Focusing on the issue of how to effectively capture and utilize cross-modality information in RGB-D salient object detection (SOD) task, we present a convolutional neural network (CNN) model, named CIR-Net, based on the novel cross-modality interaction and refinement. For the cross-modality interaction, 1) a progressive attention guided integration unit is proposed to sufficiently integrate RGB-D feature representations in the encoder stage, and 2) a convergence aggregation structure is proposed, which flows the RGB and depth decoding features into the corresponding RGB-D decoding streams via an importance gated fusion unit in the decoder stage. For the cross-modality refinement, we insert a refinement middleware structure between the encoder and the decoder, in which the RGB, depth, and RGB-D encoder features are further refined by successively using a self-modality attention refinement unit and a cross-modality weighting refinement unit. At last, with the gradually refined features, we predict the saliency map in the decoder stage. Extensive experiments on six popular RGB-D SOD benchmarks demonstrate that our network outperforms the state-of-the-art saliency detectors both qualitatively and quantitatively.