 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoMotion: Unified Human Video and Motion Generation via Dual-Modality Diffusion Transformer
Dec 21, 2025Video generation models have advanced significantly, yet they still struggle to synthesize complex human movements due to the high degrees of freedom in human articulation. This limitation stems from the intrinsic constraints of pixel-only training objectives, which inherently bias models toward appearance fidelity at the expense of learning underlying kinematic principles. To address this, we introduce EchoMotion, a framework designed to model the joint distribution of appearance and human motion, thereby improving the quality of complex human action video generation. EchoMotion extends the DiT (Diffusion Transformer) framework with a dual-branch architecture that jointly processes tokens concatenated from different modalities. Furthermore, we propose MVS-RoPE (Motion-Video Syncronized RoPE), which offers unified 3D positional encoding for both video and motion tokens. By providing a synchronized coordinate system for the dual-modal latent sequence, MVS-RoPE establishes an inductive bias that fosters temporal alignment between the two modalities. We also propose a Motion-Video Two-Stage Training Strategy. This strategy enables the model to perform both the joint generation of complex human action videos and their corresponding motion sequences, as well as versatile cross-modal conditional generation tasks. To facilitate the training of a model with these capabilities, we construct HuMoVe, a large-scale dataset of approximately 80,000 high-quality, human-centric video-motion pairs. Our findings reveal that explicitly representing human motion is complementary to appearance, significantly boosting the coherence and plausibility of human-centric video generation.
The Quest for Generalizable Motion Generation: Data, Model, and Evaluation
Oct 30, 2025Despite recent advances in 3D human motion generation (MoGen) on standard benchmarks, existing models still face a fundamental bottleneck in their generalization capability. In contrast, adjacent generative fields, most notably video generation (ViGen), have demonstrated remarkable generalization in modeling human behaviors, highlighting transferable insights that MoGen can leverage. Motivated by this observation, we present a comprehensive framework that systematically transfers knowledge from ViGen to MoGen across three key pillars: data, modeling, and evaluation. First, we introduce ViMoGen-228K, a large-scale dataset comprising 228,000 high-quality motion samples that integrates high-fidelity optical MoCap data with semantically annotated motions from web videos and synthesized samples generated by state-of-the-art ViGen models. The dataset includes both text-motion pairs and text-video-motion triplets, substantially expanding semantic diversity. Second, we propose ViMoGen, a flow-matching-based diffusion transformer that unifies priors from MoCap data and ViGen models through gated multimodal conditioning. To enhance efficiency, we further develop ViMoGen-light, a distilled variant that eliminates video generation dependencies while preserving strong generalization. Finally, we present MBench, a hierarchical benchmark designed for fine-grained evaluation across motion quality, prompt fidelity, and generalization ability. Extensive experiments show that our framework significantly outperforms existing approaches in both automatic and human evaluations. The code, data, and benchmark will be made publicly available.
DPoser-X: Diffusion Model as Robust 3D Whole-body Human Pose Prior
Aug 01, 2025We present DPoser-X, a diffusion-based prior model for 3D whole-body human poses. Building a versatile and robust full-body human pose prior remains challenging due to the inherent complexity of articulated human poses and the scarcity of high-quality whole-body pose datasets. To address these limitations, we introduce a Diffusion model as body Pose prior (DPoser) and extend it to DPoser-X for expressive whole-body human pose modeling. Our approach unifies various pose-centric tasks as inverse problems, solving them through variational diffusion sampling. To enhance performance on downstream applications, we introduce a novel truncated timestep scheduling method specifically designed for pose data characteristics. We also propose a masked training mechanism that effectively combines whole-body and part-specific datasets, enabling our model to capture interdependencies between body parts while avoiding overfitting to specific actions. Extensive experiments demonstrate DPoser-X's robustness and versatility across multiple benchmarks for body, hand, face, and full-body pose modeling. Our model consistently outperforms state-of-the-art alternatives, establishing a new benchmark for whole-body human pose prior modeling.
NOVA3D: Normal Aligned Video Diffusion Model for Single Image to 3D Generation
Jun 09, 2025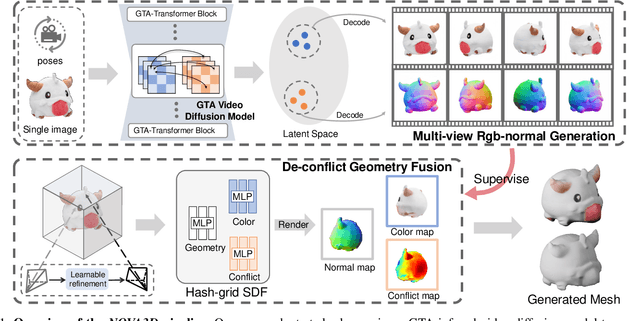
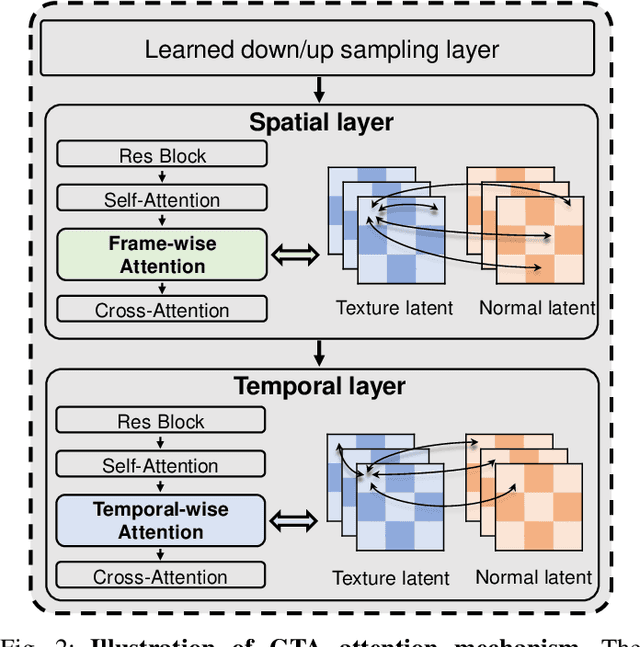


3D AI-generated content (AIGC) has made it increasingly accessible for anyone to become a 3D content creator. While recent methods leverage Score Distillation Sampling to distill 3D objects from pretrained image diffusion models, they often suffer from inadequate 3D priors, leading to insufficient multi-view consistency. In this work, we introduce NOVA3D, an innovative single-image-to-3D generation framework. Our key insight lies in leveraging strong 3D priors from a pretrained video diffusion model and integrating geometric information during multi-view video fine-tuning. To facilitate information exchange between color and geometric domains, we propose the Geometry-Temporal Alignment (GTA) attention mechanism, thereby improving generalization and multi-view consistency. Moreover, we introduce the de-conflict geometry fusion algorithm, which improves texture fidelity by addressing multi-view inaccuracies and resolving discrepancies in pose alignment. Extensive experiments validate the superiority of NOVA3D over existing baselines.
Aquatic-GS: A Hybrid 3D Representation for Underwater Scenes
Oct 31, 2024



Representing underwater 3D scenes is a valuable yet complex task, as attenuation and scattering effects during underwater imaging significantly couple the information of the objects and the water. This coupling presents a significant challenge for existing methods in effectively representing both the objects and the water medium simultaneously. To address this challenge, we propose Aquatic-GS, a hybrid 3D representation approach for underwater scenes that effectively represents both the objects and the water medium. Specifically, we construct a Neural Water Field (NWF) to implicitly model the water parameters, while extending the latest 3D Gaussian Splatting (3DGS) to model the objects explicitly. Both components are integrated through a physics-based underwater image formation model to represent complex underwater scenes. Moreover, to construct more precise scene geometry and details, we design a Depth-Guided Optimization (DGO) mechanism that uses a pseudo-depth map as auxiliary guidance. After optimization, Aquatic-GS enables the rendering of novel underwater viewpoints and supports restoring the true appearance of underwater scenes, as if the water medium were absent. Extensive experiments on both simulated and real-world datasets demonstrate that Aquatic-GS surpasses state-of-the-art underwater 3D representation methods, achieving better rendering quality and real-time rendering performance with a 410x increase in speed. Furthermore, regarding underwater image restoration, Aquatic-GS outperforms representative dewatering methods in color correction, detail recovery, and stability. Our models, code, and datasets can be accessed at https://aquaticgs.github.io.
DPoser: Diffusion Model as Robust 3D Human Pose Prior
Dec 09, 2023

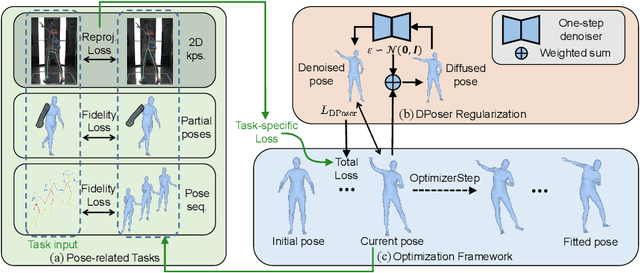

Modeling human pose is a cornerstone in applications from human-robot interaction to augmented reality, yet crafting a robust human pose prior remains a challenge due to biomechanical constraints and diverse human movements. Traditional priors like VAEs and NDFs often fall short in realism and generalization, especially in extreme conditions such as unseen noisy poses. To address these issues, we introduce DPoser, a robust and versatile human pose prior built upon diffusion models. Designed with optimization frameworks, DPoser seamlessly integrates into various pose-centric applications, including human mesh recovery, pose completion, and motion denoising. Specifically, by formulating these tasks as inverse problems, we employ variational diffusion sampling for efficient solving. Furthermore, acknowledging the disparity between the articulated poses we focus on and structured images in previous research, we propose a truncated timestep scheduling to boost performance on downstream tasks. Our exhaustive experiments demonstrate DPoser's superiority over existing state-of-the-art pose priors across multiple tasks.