 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReturn-to-Go Is More Than a Number: Q-Guided Alignment for Return-Conditioned Supervised Learning
May 27, 2026Conditioned Sequence Models (CSMs) learn policies by treating return-to-go (RTG) as a control signal. However, existing CSMs often treat the RTGs as simple numerical inputs rather than aligning them with the performance of their policies. In this paper, we propose Q-ALIGN DT, a framework that enforces this alignment by ensuring the $Q$-value of the output policy is consistent with the input RTG. By leveraging a $Q$ function to provide dense guidance to CSMs and further fine-tuning it using an RTG-perturbation technique with the CSM, our method ensures that higher RTGs are consistently mapped to trajectories with higher expected returns. Theoretically, we show that Q-ALIGN DT can efficiently learn the desired policy and output a near-optimal one when the RTG is sufficiently high. Empirically, we demonstrate through extensive experiments that Q-ALIGN DT achieves superior controllability and performance across the D4RL benchmark. Remarkably, our model effectively learns a structured family of policies that maintains precise alignment and generalizes to tasks like velocity-tracking where prior methods fail.
OGLS-SD: On-Policy Self-Distillation with Outcome-Guided Logit Steering for LLM Reasoning
May 12, 2026We study {on-policy self-distillation} (OPSD), where a language model improves its reasoning ability by distilling privileged teacher distributions along its own on-policy trajectories. Despite the performance gains of OPSD, we identify a common but often overlooked mismatch between teacher and student responses: self-reflected teacher responses can be shifted by reflection-induced bias and response templates, leading to miscalibrated token-level supervision. To mitigate this issue, we propose \methodname, an outcome-guided logit-steering framework that leverages verifiable outcome rewards to contrast successful and failed on-policy trajectories and calibrate teacher logits. By combining outcome-level correctness with dense token-level guidance through logit steering, \methodname stabilizes self-distillation and improves reasoning performance over standard OPSD and other variants across diverse benchmarks.
AnyID: Ultra-Fidelity Universal Identity-Preserving Video Generation from Any Visual References
Mar 26, 2026Identity-preserving video generation offers powerful tools for creative expression, allowing users to customize videos featuring their beloved characters. However, prevailing methods are typically designed and optimized for a single identity reference. This underlying assumption restricts creative flexibility by inadequately accommodating diverse real-world input formats. Relying on a single source also constitutes an ill-posed scenario, causing an inherently ambiguous setting that makes it difficult for the model to faithfully reproduce an identity across novel contexts. To address these issues, we present AnyID, an ultra-fidelity identity-preservation video generation framework that features two core contributions. First, we introduce a scalable omni-referenced architecture that effectively unifies heterogeneous identity inputs (e.g., faces, portraits, and videos) into a cohesive representation. Second, we propose a primary-referenced generation paradigm, which designates one reference as a canonical anchor and uses a novel differential prompt to enable precise, attribute-level controllability. We conduct training on a large-scale, meticulously curated dataset to ensure robustness and high fidelity, and then perform a final fine-tuning stage using reinforcement learning. This process leverages a preference dataset constructed from human evaluations, where annotators performed pairwise comparisons of videos based on two key criteria: identity fidelity and prompt controllability. Extensive evaluations validate that AnyID achieves ultra-high identity fidelity as well as superior attribute-level controllability across different task settings.
SARe: Structure-Aware Large-Scale 3D Fragment Reassembly
Mar 23, 20263D fragment reassembly aims to recover the rigid poses of unordered fragment point clouds or meshes in a common object coordinate system to reconstruct the complete shape. The problem becomes particularly challenging as the number of fragments grows, since the target shape is unknown and fragments provide weak semantic cues. Existing end-to-end approaches are prone to cascading failures due to unreliable contact reasoning, most notably inaccurate fragment adjacencies. To address this, we propose Structure-Aware Reassembly (SARe), a generative framework with SARe-Gen for Euclidean-space assembly generation and SARe-Refine for inference-time refinement, with explicit contact modeling. SARe-Gen jointly predicts fracture-surface token probabilities and an inter-fragment contact graph to localize contact regions and infer candidate adjacencies. It adopts a query-point-based conditioning scheme and extracts aligned local geometric tokens at query locations from a frozen geometry encoder, yielding queryable structural representations without additional structural pretraining. We further introduce an inference-time refinement stage, SARe-Refine. By verifying candidate contact edges with geometric-consistency checks, it selects reliable substructures and resamples the remaining uncertain regions while keeping verified parts fixed, leading to more stable and consistent assemblies in the many-fragment regime. We evaluate SARe across three settings, including synthetic fractures, simulated fractures from scanned real objects, and real physically fractured scans. The results demonstrate state-of-the-art performance, with more graceful degradation and higher success rates as the fragment count increases in challenging large-scale reassembly.
UniPR: Unified Object-level Real-to-Sim Perception and Reconstruction from a Single Stereo Pair
Mar 20, 2026Perceiving and reconstructing objects from images are critical for real-to-sim transfer tasks, which are widely used in the robotics community. Existing methods rely on multiple submodules such as detection, segmentation, shape reconstruction, and pose estimation to complete the pipeline. However, such modular pipelines suffer from inefficiency and cumulative error, as each stage operates on only partial or locally refined information while discarding global context. To address these limitations, we propose UniPR, the first end-to-end object-level real-to-sim perception and reconstruction framework. Operating directly on a single stereo image pair, UniPR leverages geometric constraints to resolve the scale ambiguity. We introduce Pose-Aware Shape Representation to eliminate the need for per-category canonical definitions and to bridge the gap between reconstruction and pose estimation tasks. Furthermore, we construct a large-vocabulary stereo dataset, LVS6D, comprising over 6,300 objects, to facilitate large-scale research in this area. Extensive experiments demonstrate that UniPR reconstructs all objects in a scene in parallel within a single forward pass, achieving significant efficiency gains and preserves true physical proportions across diverse object types, highlighting its potential for practical robotic applications.
Provable and Practical In-Context Policy Optimization for Self-Improvement
Mar 02, 2026We study test-time scaling, where a model improves its answer through multi-round self-reflection at inference. We introduce In-Context Policy Optimization (ICPO), in which an agent optimizes its response in context using self-assessed or externally observed rewards without modifying its parameters. To explain this ICPO process, we theoretically show that with sufficient pretraining under a novel Fisher-weighted logit-matching objective, a single-layer linear self-attention model can provably imitate policy-optimization algorithm for linear bandits. Building on this theory, we propose Minimum-Entropy ICPO (ME-ICPO), a practical algorithm that iteratively uses its response and self-assessed reward to refine its response in-context at inference time. By selecting the responses and their rewards with minimum entropy, ME-ICPO ensures the robustness of the self-assessed rewards via majority voting. Across standard mathematical reasoning tasks, ME-ICPO attains competitive, top-tier performance while keeping inference costs affordable compared with other inference-time algorithms. Overall, ICPO provides a principled understanding of self-reflection in LLMs and yields practical benefits for test-time scaling for mathematical reasoning.
EchoMotion: Unified Human Video and Motion Generation via Dual-Modality Diffusion Transformer
Dec 21, 2025Video generation models have advanced significantly, yet they still struggle to synthesize complex human movements due to the high degrees of freedom in human articulation. This limitation stems from the intrinsic constraints of pixel-only training objectives, which inherently bias models toward appearance fidelity at the expense of learning underlying kinematic principles. To address this, we introduce EchoMotion, a framework designed to model the joint distribution of appearance and human motion, thereby improving the quality of complex human action video generation. EchoMotion extends the DiT (Diffusion Transformer) framework with a dual-branch architecture that jointly processes tokens concatenated from different modalities. Furthermore, we propose MVS-RoPE (Motion-Video Syncronized RoPE), which offers unified 3D positional encoding for both video and motion tokens. By providing a synchronized coordinate system for the dual-modal latent sequence, MVS-RoPE establishes an inductive bias that fosters temporal alignment between the two modalities. We also propose a Motion-Video Two-Stage Training Strategy. This strategy enables the model to perform both the joint generation of complex human action videos and their corresponding motion sequences, as well as versatile cross-modal conditional generation tasks. To facilitate the training of a model with these capabilities, we construct HuMoVe, a large-scale dataset of approximately 80,000 high-quality, human-centric video-motion pairs. Our findings reveal that explicitly representing human motion is complementary to appearance, significantly boosting the coherence and plausibility of human-centric video generation.
Target-Balanced Score Distillation
Nov 12, 2025Score Distillation Sampling (SDS) enables 3D asset generation by distilling priors from pretrained 2D text-to-image diffusion models, but vanilla SDS suffers from over-saturation and over-smoothing. To mitigate this issue, recent variants have incorporated negative prompts. However, these methods face a critical trade-off: limited texture optimization, or significant texture gains with shape distortion. In this work, we first conduct a systematic analysis and reveal that this trade-off is fundamentally governed by the utilization of the negative prompts, where Target Negative Prompts (TNP) that embed target information in the negative prompts dramatically enhancing texture realism and fidelity but inducing shape distortions. Informed by this key insight, we introduce the Target-Balanced Score Distillation (TBSD). It formulates generation as a multi-objective optimization problem and introduces an adaptive strategy that effectively resolves the aforementioned trade-off. Extensive experiments demonstrate that TBSD significantly outperforms existing state-of-the-art methods, yielding 3D assets with high-fidelity textures and geometrically accurate shape.
Multimodal LLMs for Visualization Reconstruction and Understanding
Jun 26, 2025Visualizations are crucial for data communication, yet understanding them requires comprehension of both visual elements and their underlying data relationships. Current multimodal large models, while effective in natural image understanding, struggle with visualization due to their inability to decode the data-to-visual mapping rules and extract structured information. To address these challenges, we present a novel dataset and train multimodal visualization LLMs specifically designed for understanding. Our approach combines chart images with their corresponding vectorized representations, encoding schemes, and data features. The proposed vector format enables compact and accurate reconstruction of visualization content. Experimental results demonstrate significant improvements in both data extraction accuracy and chart reconstruction quality.
NOVA3D: Normal Aligned Video Diffusion Model for Single Image to 3D Generation
Jun 09, 2025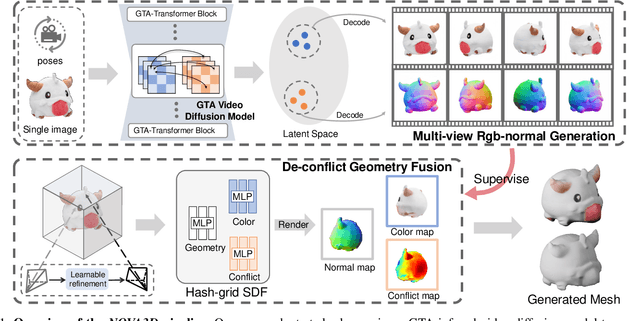
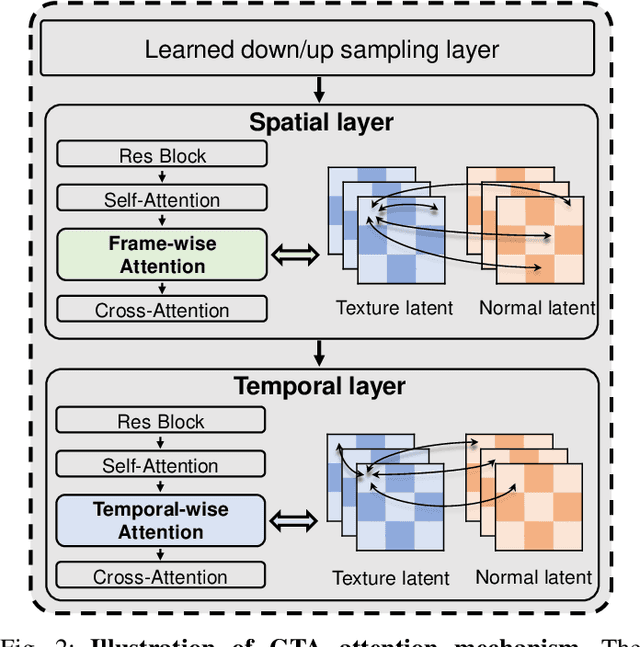


3D AI-generated content (AIGC) has made it increasingly accessible for anyone to become a 3D content creator. While recent methods leverage Score Distillation Sampling to distill 3D objects from pretrained image diffusion models, they often suffer from inadequate 3D priors, leading to insufficient multi-view consistency. In this work, we introduce NOVA3D, an innovative single-image-to-3D generation framework. Our key insight lies in leveraging strong 3D priors from a pretrained video diffusion model and integrating geometric information during multi-view video fine-tuning. To facilitate information exchange between color and geometric domains, we propose the Geometry-Temporal Alignment (GTA) attention mechanism, thereby improving generalization and multi-view consistency. Moreover, we introduce the de-conflict geometry fusion algorithm, which improves texture fidelity by addressing multi-view inaccuracies and resolving discrepancies in pose alignment. Extensive experiments validate the superiority of NOVA3D over existing baselines.