 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Markovian: Reflective Exploration via Bayes-Adaptive RL for LLM Reasoning
May 26, 2025Large Language Models (LLMs) trained via Reinforcement Learning (RL) have exhibited strong reasoning capabilities and emergent reflective behaviors, such as backtracking and error correction. However, conventional Markovian RL confines exploration to the training phase to learn an optimal deterministic policy and depends on the history contexts only through the current state. Therefore, it remains unclear whether reflective reasoning will emerge during Markovian RL training, or why they are beneficial at test time. To remedy this, we recast reflective exploration within the Bayes-Adaptive RL framework, which explicitly optimizes the expected return under a posterior distribution over Markov decision processes. This Bayesian formulation inherently incentivizes both reward-maximizing exploitation and information-gathering exploration via belief updates. Our resulting algorithm, BARL, instructs the LLM to stitch and switch strategies based on the observed outcomes, offering principled guidance on when and how the model should reflectively explore. Empirical results on both synthetic and mathematical reasoning tasks demonstrate that BARL outperforms standard Markovian RL approaches at test time, achieving superior token efficiency with improved exploration effectiveness. Our code is available at https://github.com/shenao-zhang/BARL.
BRiTE: Bootstrapping Reinforced Thinking Process to Enhance Language Model Reasoning
Jan 31, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, yet generating reliable reasoning processes remains a significant challenge. We present a unified probabilistic framework that formalizes LLM reasoning through a novel graphical model incorporating latent thinking processes and evaluation signals. Within this framework, we introduce the Bootstrapping Reinforced Thinking Process (BRiTE) algorithm, which works in two steps. First, it generates high-quality rationales by approximating the optimal thinking process through reinforcement learning, using a novel reward shaping mechanism. Second, it enhances the base LLM by maximizing the joint probability of rationale generation with respect to the model's parameters. Theoretically, we demonstrate BRiTE's convergence at a rate of $1/T$ with $T$ representing the number of iterations. Empirical evaluations on math and coding benchmarks demonstrate that our approach consistently improves performance across different base models without requiring human-annotated thinking processes. In addition, BRiTE demonstrates superior performance compared to existing algorithms that bootstrap thinking processes use alternative methods such as rejection sampling, and can even match or exceed the results achieved through supervised fine-tuning with human-annotated data.
Hindsight Planner: A Closed-Loop Few-Shot Planner for Embodied Instruction Following
Dec 27, 2024



This work focuses on building a task planner for Embodied Instruction Following (EIF) using Large Language Models (LLMs). Previous works typically train a planner to imitate expert trajectories, treating this as a supervised task. While these methods achieve competitive performance, they often lack sufficient robustness. When a suboptimal action is taken, the planner may encounter an out-of-distribution state, which can lead to task failure. In contrast, we frame the task as a Partially Observable Markov Decision Process (POMDP) and aim to develop a robust planner under a few-shot assumption. Thus, we propose a closed-loop planner with an adaptation module and a novel hindsight method, aiming to use as much information as possible to assist the planner. Our experiments on the ALFRED dataset indicate that our planner achieves competitive performance under a few-shot assumption. For the first time, our few-shot agent's performance approaches and even surpasses that of the full-shot supervised agent.
Offline Reinforcement Learning for LLM Multi-Step Reasoning
Dec 20, 2024



Improving the multi-step reasoning ability of large language models (LLMs) with offline reinforcement learning (RL) is essential for quickly adapting them to complex tasks. While Direct Preference Optimization (DPO) has shown promise in aligning LLMs with human preferences, it is less suitable for multi-step reasoning tasks because (1) DPO relies on paired preference data, which is not readily available for multi-step reasoning tasks, and (2) it treats all tokens uniformly, making it ineffective for credit assignment in multi-step reasoning tasks, which often come with sparse reward. In this work, we propose OREO (Offline Reasoning Optimization), an offline RL method for enhancing LLM multi-step reasoning. Building on insights from previous works of maximum entropy reinforcement learning, it jointly learns a policy model and value function by optimizing the soft Bellman Equation. We show in principle that it reduces the need to collect pairwise data and enables better credit assignment. Empirically, OREO surpasses existing offline learning methods on multi-step reasoning benchmarks, including mathematical reasoning tasks (GSM8K, MATH) and embodied agent control (ALFWorld). The approach can be extended to a multi-iteration framework when additional resources are available. Furthermore, the learned value function can be leveraged to guide the tree search for free, which can further boost performance during test time.
DSTC: Direct Preference Learning with Only Self-Generated Tests and Code to Improve Code LMs
Nov 20, 2024



Direct preference learning offers a promising and computation-efficient beyond supervised fine-tuning (SFT) for improving code generation in coding large language models (LMs). However, the scarcity of reliable preference data is a bottleneck for the performance of direct preference learning to improve the coding accuracy of code LMs. In this paper, we introduce \underline{\textbf{D}}irect Preference Learning with Only \underline{\textbf{S}}elf-Generated \underline{\textbf{T}}ests and \underline{\textbf{C}}ode (DSTC), a framework that leverages only self-generated code snippets and tests to construct reliable preference pairs such that direct preference learning can improve LM coding accuracy without external annotations. DSTC combines a minimax selection process and test-code concatenation to improve preference pair quality, reducing the influence of incorrect self-generated tests and enhancing model performance without the need for costly reward models. When applied with direct preference learning methods such as Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO), DSTC yields stable improvements in coding accuracy (pass@1 score) across diverse coding benchmarks, including HumanEval, MBPP, and BigCodeBench, demonstrating both its effectiveness and scalability for models of various sizes. This approach autonomously enhances code generation accuracy across LLMs of varying sizes, reducing reliance on expensive annotated coding datasets.
Reward-Augmented Data Enhances Direct Preference Alignment of LLMs
Oct 10, 2024



Preference alignment in Large Language Models (LLMs) has significantly improved their ability to adhere to human instructions and intentions. However, existing direct alignment algorithms primarily focus on relative preferences and often overlook the qualitative aspects of responses. Striving to maximize the implicit reward gap between the chosen and the slightly inferior rejected responses can cause overfitting and unnecessary unlearning of the high-quality rejected responses. The unawareness of the reward scores also drives the LLM to indiscriminately favor the low-quality chosen responses and fail to generalize to responses with the highest rewards, which are sparse in data. To overcome these shortcomings, our study introduces reward-conditioned LLM policies that discern and learn from the entire spectrum of response quality within the dataset, helping extrapolate to more optimal regions. We propose an effective yet simple data relabeling method that conditions the preference pairs on quality scores to construct a reward-augmented dataset. This dataset is easily integrated with existing direct alignment algorithms and is applicable to any preference dataset. The experimental results across instruction-following benchmarks including AlpacaEval, MT-Bench, and Arena-Hard-Auto demonstrate that our approach consistently boosts the performance of DPO by a considerable margin across diverse models. Additionally, our method improves the average accuracy on various academic benchmarks. When applying our method to on-policy data, the resulting DPO model achieves SOTA results on AlpacaEval. Through ablation studies, we demonstrate that our method not only maximizes the utility of preference data but also mitigates the issue of unlearning, demonstrating its broad effectiveness beyond mere dataset expansion. Our code is available at https://github.com/shenao-zhang/reward-augmented-preference.
Self-Exploring Language Models: Active Preference Elicitation for Online Alignment
May 29, 2024



Preference optimization, particularly through Reinforcement Learning from Human Feedback (RLHF), has achieved significant success in aligning Large Language Models (LLMs) to adhere to human intentions. Unlike offline alignment with a fixed dataset, online feedback collection from humans or AI on model generations typically leads to more capable reward models and better-aligned LLMs through an iterative process. However, achieving a globally accurate reward model requires systematic exploration to generate diverse responses that span the vast space of natural language. Random sampling from standard reward-maximizing LLMs alone is insufficient to fulfill this requirement. To address this issue, we propose a bilevel objective optimistically biased towards potentially high-reward responses to actively explore out-of-distribution regions. By solving the inner-level problem with the reparameterized reward function, the resulting algorithm, named Self-Exploring Language Models (SELM), eliminates the need for a separate RM and iteratively updates the LLM with a straightforward objective. Compared to Direct Preference Optimization (DPO), the SELM objective reduces indiscriminate favor of unseen extrapolations and enhances exploration efficiency. Our experimental results demonstrate that when finetuned on Zephyr-7B-SFT and Llama-3-8B-Instruct models, SELM significantly boosts the performance on instruction-following benchmarks such as MT-Bench and AlpacaEval 2.0, as well as various standard academic benchmarks in different settings. Our code and models are available at https://github.com/shenao-zhang/SELM.
Provably Mitigating Overoptimization in RLHF: Your SFT Loss is Implicitly an Adversarial Regularizer
May 26, 2024



Aligning generative models with human preference via RLHF typically suffers from overoptimization, where an imperfectly learned reward model can misguide the generative model to output undesired responses. We investigate this problem in a principled manner by identifying the source of the misalignment as a form of distributional shift and uncertainty in learning human preferences. To mitigate overoptimization, we first propose a theoretical algorithm that chooses the best policy for an adversarially chosen reward model; one that simultaneously minimizes the maximum likelihood estimation of the loss and a reward penalty term. Here, the reward penalty term is introduced to prevent the policy from choosing actions with spurious high proxy rewards, resulting in provable sample efficiency of the algorithm under a partial coverage style condition. Moving from theory to practice, the proposed algorithm further enjoys an equivalent but surprisingly easy-to-implement reformulation. Using the equivalence between reward models and the corresponding optimal policy, the algorithm features a simple objective that combines: (i) a preference optimization loss that directly aligns the policy with human preference, and (ii) a supervised learning loss that explicitly imitates the policy with a (suitable) baseline distribution. In the context of aligning large language models (LLM), this objective fuses the direct preference optimization (DPO) loss with the supervised fune-tuning (SFT) loss to help mitigate the overoptimization towards undesired responses, for which we name the algorithm Regularized Preference Optimization (RPO). Experiments of aligning LLMs demonstrate the improved performance of RPO compared with DPO baselines. Our work sheds light on the interplay between preference optimization and SFT in tuning LLMs with both theoretical guarantees and empirical evidence.
How Can LLM Guide RL? A Value-Based Approach
Feb 25, 2024
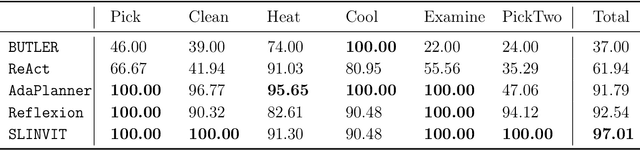

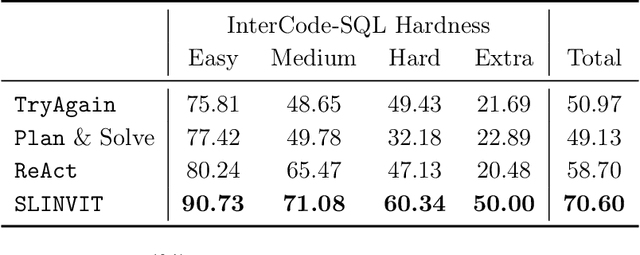
Reinforcement learning (RL) has become the de facto standard practice for sequential decision-making problems by improving future acting policies with feedback. However, RL algorithms may require extensive trial-and-error interactions to collect useful feedback for improvement. On the other hand, recent developments in large language models (LLMs) have showcased impressive capabilities in language understanding and generation, yet they fall short in exploration and self-improvement capabilities for planning tasks, lacking the ability to autonomously refine their responses based on feedback. Therefore, in this paper, we study how the policy prior provided by the LLM can enhance the sample efficiency of RL algorithms. Specifically, we develop an algorithm named LINVIT that incorporates LLM guidance as a regularization factor in value-based RL, leading to significant reductions in the amount of data needed for learning, particularly when the difference between the ideal policy and the LLM-informed policy is small, which suggests that the initial policy is close to optimal, reducing the need for further exploration. Additionally, we present a practical algorithm SLINVIT that simplifies the construction of the value function and employs subgoals to reduce the search complexity. Our experiments across three interactive environments ALFWorld, InterCode, and BlocksWorld demonstrate that our method achieves state-of-the-art success rates and also surpasses previous RL and LLM approaches in terms of sample efficiency. Our code is available at https://github.com/agentification/Language-Integrated-VI.
Model-Based Reparameterization Policy Gradient Methods: Theory and Practical Algorithms
Oct 30, 2023

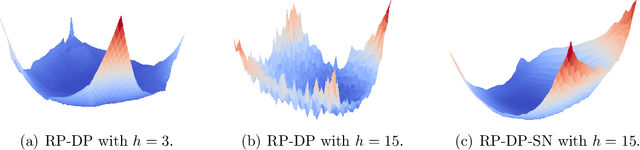

ReParameterization (RP) Policy Gradient Methods (PGMs) have been widely adopted for continuous control tasks in robotics and computer graphics. However, recent studies have revealed that, when applied to long-term reinforcement learning problems, model-based RP PGMs may experience chaotic and non-smooth optimization landscapes with exploding gradient variance, which leads to slow convergence. This is in contrast to the conventional belief that reparameterization methods have low gradient estimation variance in problems such as training deep generative models. To comprehend this phenomenon, we conduct a theoretical examination of model-based RP PGMs and search for solutions to the optimization difficulties. Specifically, we analyze the convergence of the model-based RP PGMs and pinpoint the smoothness of function approximators as a major factor that affects the quality of gradient estimation. Based on our analysis, we propose a spectral normalization method to mitigate the exploding variance issue caused by long model unrolls. Our experimental results demonstrate that proper normalization significantly reduces the gradient variance of model-based RP PGMs. As a result, the performance of the proposed method is comparable or superior to other gradient estimators, such as the Likelihood Ratio (LR) gradient estimator. Our code is available at https://github.com/agentification/RP_PGM.