 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIFT: Interpretable truck driving risk prediction with literature-informed fine-tuned LLMs
Oct 25, 2025This study proposes an interpretable prediction framework with literature-informed fine-tuned (LIFT) LLMs for truck driving risk prediction. The framework integrates an LLM-driven Inference Core that predicts and explains truck driving risk, a Literature Processing Pipeline that filters and summarizes domain-specific literature into a literature knowledge base, and a Result Evaluator that evaluates the prediction performance as well as the interpretability of the LIFT LLM. After fine-tuning on a real-world truck driving risk dataset, the LIFT LLM achieved accurate risk prediction, outperforming benchmark models by 26.7% in recall and 10.1% in F1-score. Furthermore, guided by the literature knowledge base automatically constructed from 299 domain papers, the LIFT LLM produced variable importance ranking consistent with that derived from the benchmark model, while demonstrating robustness in interpretation results to various data sampling conditions. The LIFT LLM also identified potential risky scenarios by detecting key combination of variables in truck driving risk, which were verified by PERMANOVA tests. Finally, we demonstrated the contribution of the literature knowledge base and the fine-tuning process in the interpretability of the LIFT LLM, and discussed the potential of the LIFT LLM in data-driven knowledge discovery.
Beyond Markovian: Reflective Exploration via Bayes-Adaptive RL for LLM Reasoning
May 26, 2025Large Language Models (LLMs) trained via Reinforcement Learning (RL) have exhibited strong reasoning capabilities and emergent reflective behaviors, such as backtracking and error correction. However, conventional Markovian RL confines exploration to the training phase to learn an optimal deterministic policy and depends on the history contexts only through the current state. Therefore, it remains unclear whether reflective reasoning will emerge during Markovian RL training, or why they are beneficial at test time. To remedy this, we recast reflective exploration within the Bayes-Adaptive RL framework, which explicitly optimizes the expected return under a posterior distribution over Markov decision processes. This Bayesian formulation inherently incentivizes both reward-maximizing exploitation and information-gathering exploration via belief updates. Our resulting algorithm, BARL, instructs the LLM to stitch and switch strategies based on the observed outcomes, offering principled guidance on when and how the model should reflectively explore. Empirical results on both synthetic and mathematical reasoning tasks demonstrate that BARL outperforms standard Markovian RL approaches at test time, achieving superior token efficiency with improved exploration effectiveness. Our code is available at https://github.com/shenao-zhang/BARL.
Conditioned Language Policy: A General Framework for Steerable Multi-Objective Finetuning
Jul 22, 2024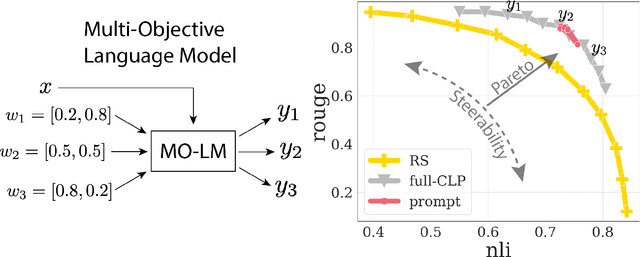
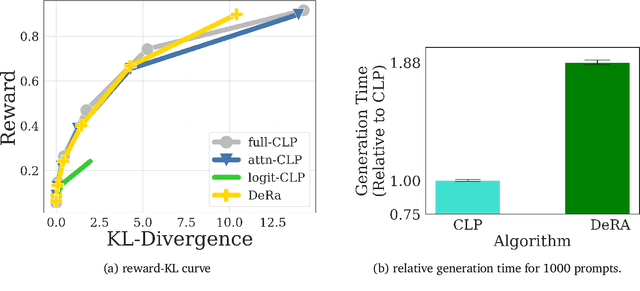
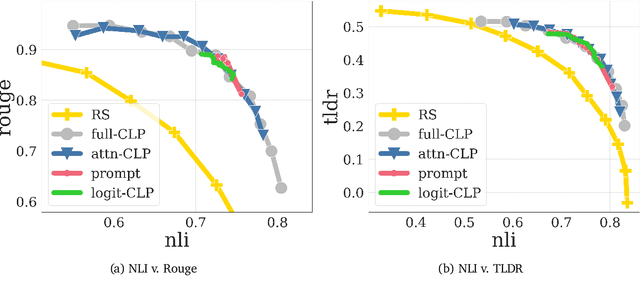
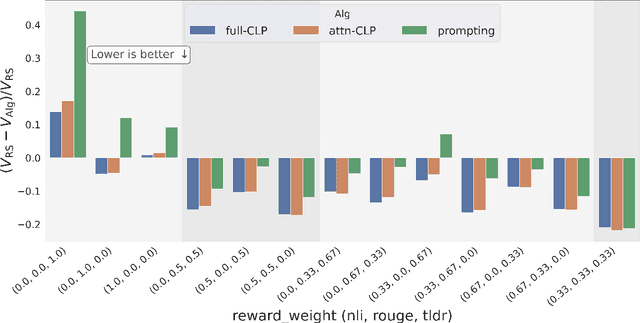
Reward-based finetuning is crucial for aligning language policies with intended behaviors (e.g., creativity and safety). A key challenge here is to develop steerable language models that trade-off multiple (conflicting) objectives in a flexible and efficient manner. This paper presents Conditioned Language Policy (CLP), a general framework for finetuning language models on multiple objectives. Building on techniques from multi-task training and parameter-efficient finetuning, CLP can learn steerable models that effectively trade-off conflicting objectives at inference time. Notably, this does not require training or maintaining multiple models to achieve different trade-offs between the objectives. Through an extensive set of experiments and ablations, we show that the CLP framework learns steerable models that outperform and Pareto-dominate the current state-of-the-art approaches for multi-objective finetuning.
Improving Multi-Agent Debate with Sparse Communication Topology
Jun 17, 2024Multi-agent debate has proven effective in improving large language models quality for reasoning and factuality tasks. While various role-playing strategies in multi-agent debates have been explored, in terms of the communication among agents, existing approaches adopt a brute force algorithm -- each agent can communicate with all other agents. In this paper, we systematically investigate the effect of communication connectivity in multi-agent systems. Our experiments on GPT and Mistral models reveal that multi-agent debates leveraging sparse communication topology can achieve comparable or superior performance while significantly reducing computational costs. Furthermore, we extend the multi-agent debate framework to multimodal reasoning and alignment labeling tasks, showcasing its broad applicability and effectiveness. Our findings underscore the importance of communication connectivity on enhancing the efficiency and effectiveness of the "society of minds" approach.
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Jun 05, 2024

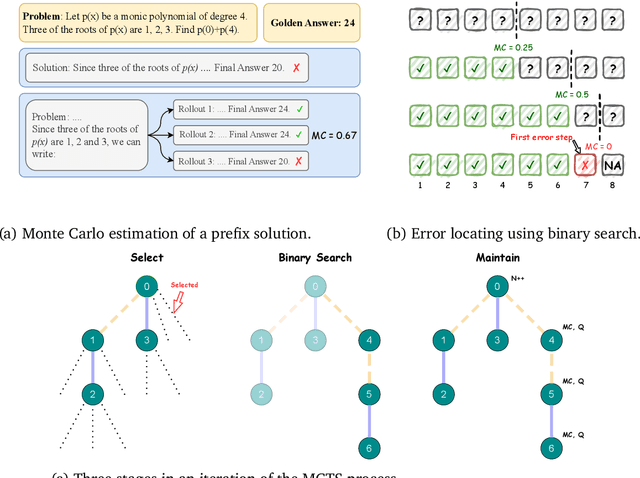
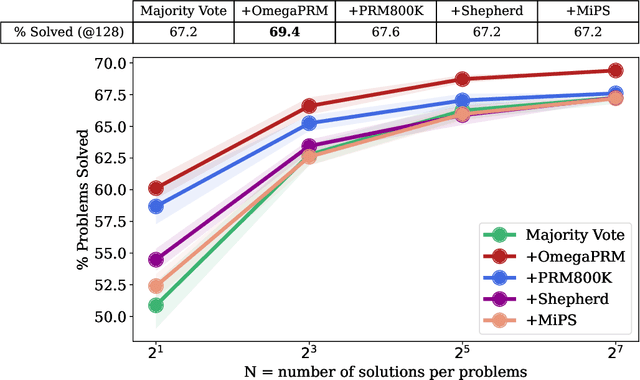
Complex multi-step reasoning tasks, such as solving mathematical problems or generating code, remain a significant hurdle for even the most advanced large language models (LLMs). Verifying LLM outputs with an Outcome Reward Model (ORM) is a standard inference-time technique aimed at enhancing the reasoning performance of LLMs. However, this still proves insufficient for reasoning tasks with a lengthy or multi-hop reasoning chain, where the intermediate outcomes are neither properly rewarded nor penalized. Process supervision addresses this limitation by assigning intermediate rewards during the reasoning process. To date, the methods used to collect process supervision data have relied on either human annotation or per-step Monte Carlo estimation, both prohibitively expensive to scale, thus hindering the broad application of this technique. In response to this challenge, we propose a novel divide-and-conquer style Monte Carlo Tree Search (MCTS) algorithm named \textit{OmegaPRM} for the efficient collection of high-quality process supervision data. This algorithm swiftly identifies the first error in the Chain of Thought (CoT) with binary search and balances the positive and negative examples, thereby ensuring both efficiency and quality. As a result, we are able to collect over 1.5 million process supervision annotations to train a Process Reward Model (PRM). Utilizing this fully automated process supervision alongside the weighted self-consistency algorithm, we have enhanced the instruction tuned Gemini Pro model's math reasoning performance, achieving a 69.4\% success rate on the MATH benchmark, a 36\% relative improvement from the 51\% base model performance. Additionally, the entire process operates without any human intervention, making our method both financially and computationally cost-effective compared to existing methods.
Multi-step Problem Solving Through a Verifier: An Empirical Analysis on Model-induced Process Supervision
Feb 05, 2024



Process supervision, using a trained verifier to evaluate the intermediate steps generated by reasoner, has demonstrated significant improvements in multi-step problem solving. In this paper, to avoid expensive human annotation effort on the verifier training data, we introduce Model-induced Process Supervision (MiPS), a novel method for automating data curation. MiPS annotates an intermediate step by sampling completions of this solution through the reasoning model, and obtaining an accuracy defined as the proportion of correct completions. Errors in the reasoner would cause MiPS to underestimate the accuracy of intermediate steps, therefore, we suggest and empirically show that verification focusing on high predicted scores of the verifier shall be preferred over that of low predicted scores, contrary to prior work. Our approach significantly improves the performance of PaLM 2 on math and coding tasks (accuracy +0.67% on GSM8K, +4.16% on MATH, +0.92% on MBPP compared with an output supervision trained verifier). Additionally, our study demonstrates that the verifier exhibits strong generalization ability across different reasoning models.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Evidential Active Recognition: Intelligent and Prudent Open-World Embodied Perception
Nov 23, 2023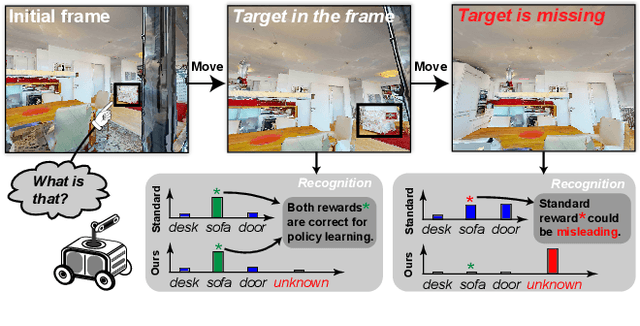
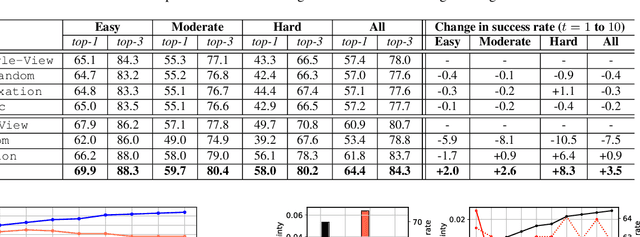
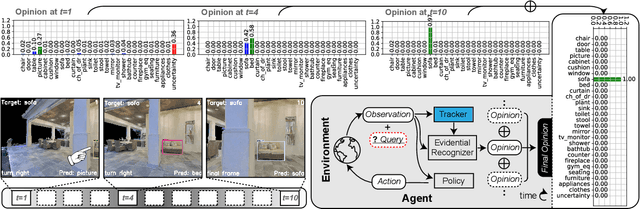
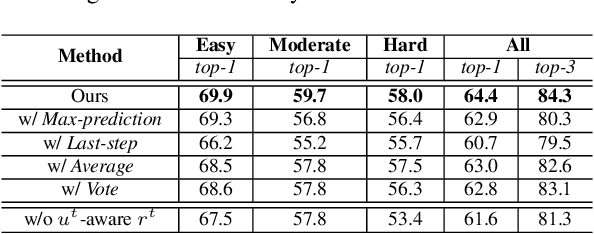
Active recognition enables robots to intelligently explore novel observations, thereby acquiring more information while circumventing undesired viewing conditions. Recent approaches favor learning policies from simulated or collected data, wherein appropriate actions are more frequently selected when the recognition is accurate. However, most recognition modules are developed under the closed-world assumption, which makes them ill-equipped to handle unexpected inputs, such as the absence of the target object in the current observation. To address this issue, we propose treating active recognition as a sequential evidence-gathering process, providing by-step uncertainty quantification and reliable prediction under the evidence combination theory. Additionally, the reward function developed in this paper effectively characterizes the merit of actions when operating in open-world environments. To evaluate the performance, we collect a dataset from an indoor simulator, encompassing various recognition challenges such as distance, occlusion levels, and visibility. Through a series of experiments on recognition and robustness analysis, we demonstrate the necessity of introducing uncertainties to active recognition and the superior performance of the proposed method.
Enable Language Models to Implicitly Learn Self-Improvement From Data
Oct 05, 2023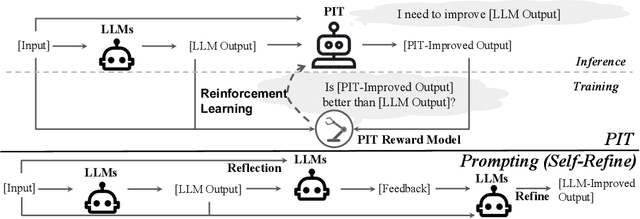
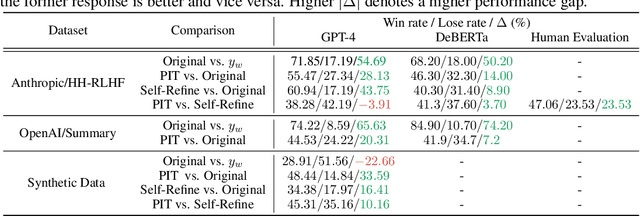
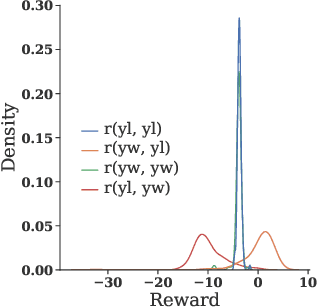

Large Language Models (LLMs) have demonstrated remarkable capabilities in open-ended text generation tasks. However, the inherent open-ended nature of these tasks implies that there is always room for improvement in the quality of model responses. To address this challenge, various approaches have been proposed to enhance the performance of LLMs. There has been a growing focus on enabling LLMs to self-improve their response quality, thereby reducing the reliance on extensive human annotation efforts for collecting diverse and high-quality training data. Recently, prompting-based methods have been widely explored among self-improvement methods owing to their effectiveness, efficiency, and convenience. However, those methods usually require explicitly and thoroughly written rubrics as inputs to LLMs. It is expensive and challenging to manually derive and provide all necessary rubrics with a real-world complex goal for improvement (e.g., being more helpful and less harmful). To this end, we propose an ImPlicit Self-ImprovemenT (PIT) framework that implicitly learns the improvement goal from human preference data. PIT only requires preference data that are used to train reward models without extra human efforts. Specifically, we reformulate the training objective of reinforcement learning from human feedback (RLHF) -- instead of maximizing response quality for a given input, we maximize the quality gap of the response conditioned on a reference response. In this way, PIT is implicitly trained with the improvement goal of better aligning with human preferences. Experiments on two real-world datasets and one synthetic dataset show that our method significantly outperforms prompting-based methods.
Flan-MoE: Scaling Instruction-Finetuned Language Models with Sparse Mixture of Experts
May 24, 2023The explosive growth of language models and their applications have led to an increased demand for efficient and scalable methods. In this paper, we introduce Flan-MoE, a set of Instruction-Finetuned Sparse Mixture-of-Expert (MoE) models. We show that naively finetuning MoE models on a task-specific dataset (in other words, no instruction-finetuning) often yield worse performance compared to dense models of the same computational complexity. However, our Flan-MoE outperforms dense models under multiple experiment settings: instruction-finetuning only and instruction-finetuning followed by task-specific finetuning. This shows that instruction-finetuning is an essential stage for MoE models. Specifically, our largest model, Flan-MoE-32B, surpasses the performance of Flan-PaLM-62B on four benchmarks, while utilizing only one-third of the FLOPs. The success of Flan-MoE encourages rethinking the design of large-scale, high-performance language models, under the setting of task-agnostic learning.