 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-Following Evaluation for Large Language Models
Nov 14, 2023
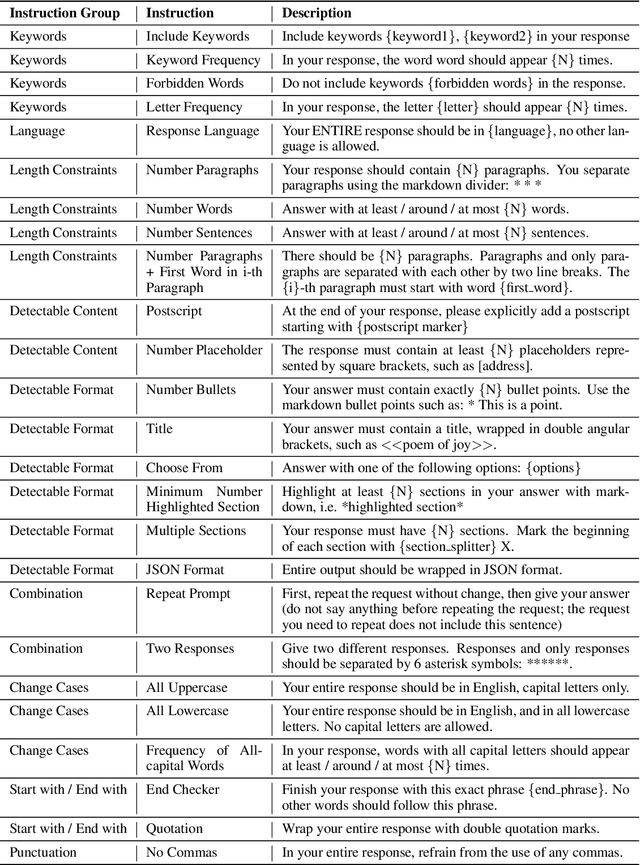
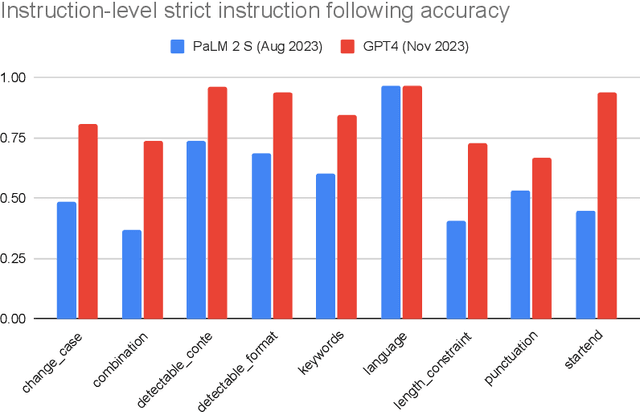

One core capability of Large Language Models (LLMs) is to follow natural language instructions. However, the evaluation of such abilities is not standardized: Human evaluations are expensive, slow, and not objectively reproducible, while LLM-based auto-evaluation is potentially biased or limited by the ability of the evaluator LLM. To overcome these issues, we introduce Instruction-Following Eval (IFEval) for large language models. IFEval is a straightforward and easy-to-reproduce evaluation benchmark. It focuses on a set of "verifiable instructions" such as "write in more than 400 words" and "mention the keyword of AI at least 3 times". We identified 25 types of those verifiable instructions and constructed around 500 prompts, with each prompt containing one or more verifiable instructions. We show evaluation results of two widely available LLMs on the market. Our code and data can be found at https://github.com/google-research/google-research/tree/master/instruction_following_eval
Enable Language Models to Implicitly Learn Self-Improvement From Data
Oct 05, 2023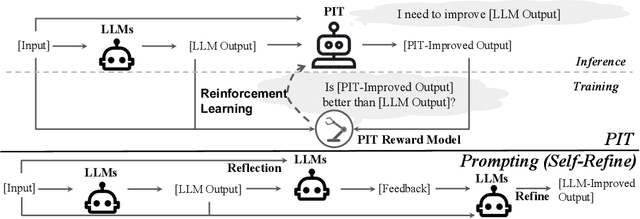
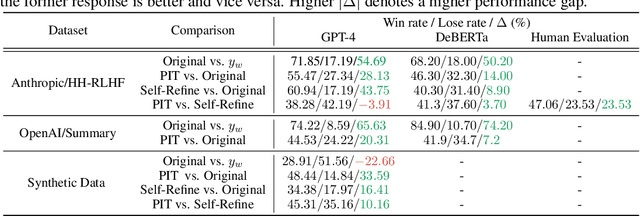
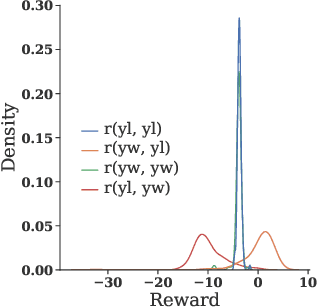

Large Language Models (LLMs) have demonstrated remarkable capabilities in open-ended text generation tasks. However, the inherent open-ended nature of these tasks implies that there is always room for improvement in the quality of model responses. To address this challenge, various approaches have been proposed to enhance the performance of LLMs. There has been a growing focus on enabling LLMs to self-improve their response quality, thereby reducing the reliance on extensive human annotation efforts for collecting diverse and high-quality training data. Recently, prompting-based methods have been widely explored among self-improvement methods owing to their effectiveness, efficiency, and convenience. However, those methods usually require explicitly and thoroughly written rubrics as inputs to LLMs. It is expensive and challenging to manually derive and provide all necessary rubrics with a real-world complex goal for improvement (e.g., being more helpful and less harmful). To this end, we propose an ImPlicit Self-ImprovemenT (PIT) framework that implicitly learns the improvement goal from human preference data. PIT only requires preference data that are used to train reward models without extra human efforts. Specifically, we reformulate the training objective of reinforcement learning from human feedback (RLHF) -- instead of maximizing response quality for a given input, we maximize the quality gap of the response conditioned on a reference response. In this way, PIT is implicitly trained with the improvement goal of better aligning with human preferences. Experiments on two real-world datasets and one synthetic dataset show that our method significantly outperforms prompting-based methods.
Deep Learning Models for Predicting Wildfires from Historical Remote-Sensing Data
Oct 15, 2020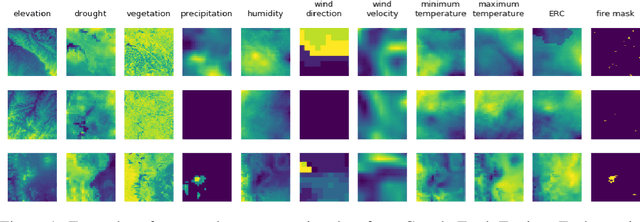
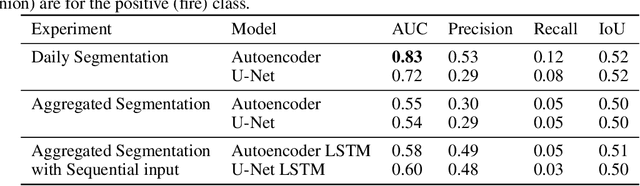
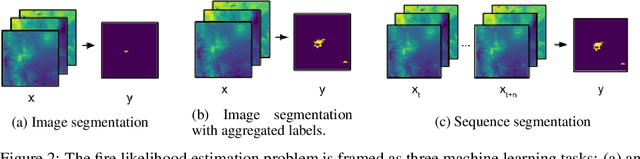

Identifying regions that have high likelihood for wildfires is a key component of land and forestry management and disaster preparedness. We create a data set by aggregating nearly a decade of remote-sensing data and historical fire records to predict wildfires. This prediction problem is framed as three machine learning tasks. Results are compared and analyzed for four different deep learning models to estimate wildfire likelihood. The results demonstrate that deep learning models can successfully identify areas of high fire likelihood using aggregated data about vegetation, weather, and topography with an AUC of 83%.
Fast Transient Simulation of High-Speed Channels Using Recurrent Neural Network
Feb 08, 2019
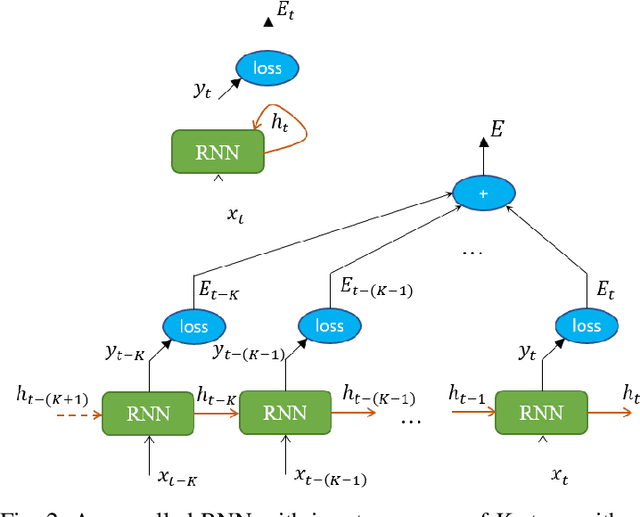
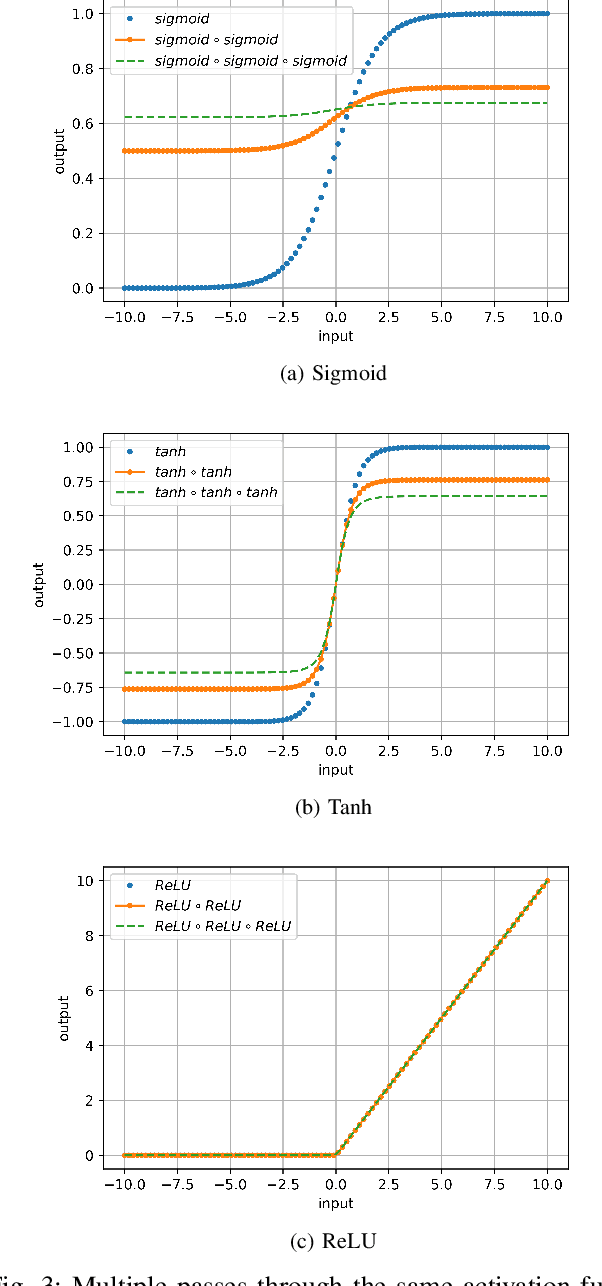

Generating eye diagrams by using a circuit simulator can be very computationally intensive, especially in the presence of nonlinearities. It often involves multiple Newton-like iterations at every time step when a SPICE-like circuit simulator handles a nonlinear system in the transient regime. In this paper, we leverage machine learning methods, to be specific, the recurrent neural network (RNN), to generate black-box macromodels and achieve significant reduction of computation time. Through the proposed approach, an RNN model is first trained and then validated on a relatively short sequence generated from a circuit simulator. Once the training completes, the RNN can be used to make predictions on the remaining sequence in order to generate an eye diagram. The training cost can also be amortized when the trained RNN starts making predictions. Besides, the proposed approach requires no complex circuit simulations nor substantial domain knowledge. We use two high-speed link examples to demonstrate that the proposed approach provides adequate accuracy while the computation time can be dramatically reduced. In the high-speed link example with a PAM4 driver, the eye diagram generated by RNN models shows good agreement with that obtained from a commercial circuit simulator. This paper also investigates the impacts of various RNN topologies, training schemes, and tunable parameters on both the accuracy and the generalization capability of an RNN model. It is found out that the long short-term memory (LSTM) network outperforms the vanilla RNN in terms of the accuracy in predicting transient waveforms.