 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Artificial Intelligence Through a Christian Understanding of Human Flourishing
Apr 03, 2026Artificial intelligence (AI) alignment is fundamentally a formation problem, not only a safety problem. As Large Language Models (LLMs) increasingly mediate moral deliberation and spiritual inquiry, they do more than provide information; they function as instruments of digital catechesis, actively shaping and ordering human understanding, decision-making, and moral reflection. To make this formative influence visible and measurable, we introduce the Flourishing AI Benchmark: Christian Single-Turn (FAI-C-ST), a framework designed to evaluate Frontier Model responses against a Christian understanding of human flourishing across seven dimensions. By comparing 20 Frontier Models against both pluralistic and Christian-specific criteria, we show that current AI systems are not worldview-neutral. Instead, they default to a Procedural Secularism that lacks the grounding necessary to sustain theological coherence, resulting in a systematic performance decline of approximately 17 points across all dimensions of flourishing. Most critically, there is a 31-point decline in the Faith and Spirituality dimension. These findings suggest that the performance gap in values alignment is not a technical limitation, but arises from training objectives that prioritize broad acceptability and safety over deep, internally coherent moral or theological reasoning.
Statistical Downscaling via High-Dimensional Distribution Matching with Generative Models
Dec 11, 2024Statistical downscaling is a technique used in climate modeling to increase the resolution of climate simulations. High-resolution climate information is essential for various high-impact applications, including natural hazard risk assessment. However, simulating climate at high resolution is intractable. Thus, climate simulations are often conducted at a coarse scale and then downscaled to the desired resolution. Existing downscaling techniques are either simulation-based methods with high computational costs, or statistical approaches with limitations in accuracy or application specificity. We introduce Generative Bias Correction and Super-Resolution (GenBCSR), a two-stage probabilistic framework for statistical downscaling that overcomes the limitations of previous methods. GenBCSR employs two transformations to match high-dimensional distributions at different resolutions: (i) the first stage, bias correction, aligns the distributions at coarse scale, (ii) the second stage, statistical super-resolution, lifts the corrected coarse distribution by introducing fine-grained details. Each stage is instantiated by a state-of-the-art generative model, resulting in an efficient and effective computational pipeline for the well-studied distribution matching problem. By framing the downscaling problem as distribution matching, GenBCSR relaxes the constraints of supervised learning, which requires samples to be aligned. Despite not requiring such correspondence, we show that GenBCSR surpasses standard approaches in predictive accuracy of critical impact variables, particularly in predicting the tails (99% percentile) of composite indexes composed of interacting variables, achieving up to 4-5 folds of error reduction.
Dynamical-generative downscaling of climate model ensembles
Oct 02, 2024



Regional high-resolution climate projections are crucial for many applications, such as agriculture, hydrology, and natural hazard risk assessment. Dynamical downscaling, the state-of-the-art method to produce localized future climate information, involves running a regional climate model (RCM) driven by an Earth System Model (ESM), but it is too computationally expensive to apply to large climate projection ensembles. We propose a novel approach combining dynamical downscaling with generative artificial intelligence to reduce the cost and improve the uncertainty estimates of downscaled climate projections. In our framework, an RCM dynamically downscales ESM output to an intermediate resolution, followed by a generative diffusion model that further refines the resolution to the target scale. This approach leverages the generalizability of physics-based models and the sampling efficiency of diffusion models, enabling the downscaling of large multi-model ensembles. We evaluate our method against dynamically-downscaled climate projections from the CMIP6 ensemble. Our results demonstrate its ability to provide more accurate uncertainty bounds on future regional climate than alternatives such as dynamical downscaling of smaller ensembles, or traditional empirical statistical downscaling methods. We also show that dynamical-generative downscaling results in significantly lower errors than bias correction and spatial disaggregation (BCSD), and captures more accurately the spectra and multivariate correlations of meteorological fields. These characteristics make the dynamical-generative framework a flexible, accurate, and efficient way to downscale large ensembles of climate projections, currently out of reach for pure dynamical downscaling.
SEEDS: Emulation of Weather Forecast Ensembles with Diffusion Models
Jun 24, 2023



Probabilistic forecasting is crucial to decision-making under uncertainty about future weather. The dominant approach is to use an ensemble of forecasts to represent and quantify uncertainty in operational numerical weather prediction. However, generating ensembles is computationally costly. In this paper, we propose to generate ensemble forecasts at scale by leveraging recent advances in generative artificial intelligence. Our approach learns a data-driven probabilistic diffusion model from the 5-member ensemble GEFS reforecast dataset. The model can then be sampled efficiently to produce realistic weather forecasts, conditioned on a few members of the operational GEFS forecasting system. The generated ensembles have similar predictive skill as the full GEFS 31-member ensemble, evaluated against ERA5 reanalysis, and emulate well the statistics of large physics-based ensembles. We also apply the same methodology to developing a diffusion model for generative post-processing: the model directly learns to correct biases present in the emulated forecasting system by leveraging reanalysis data as labels during training. Ensembles from this generative post-processing model show greater reliability and accuracy, particularly in extreme event classification. In general, they are more reliable and forecast the probability of extreme weather more accurately than the GEFS operational ensemble. Our models achieve these results at less than 1/10th of the computational cost incurred by the operational GEFS system.
Debias Coarsely, Sample Conditionally: Statistical Downscaling through Optimal Transport and Probabilistic Diffusion Models
May 24, 2023



We introduce a two-stage probabilistic framework for statistical downscaling between unpaired data. Statistical downscaling seeks a probabilistic map to transform low-resolution data from a (possibly biased) coarse-grained numerical scheme to high-resolution data that is consistent with a high-fidelity scheme. Our framework tackles the problem by tandeming two transformations: a debiasing step that is performed by an optimal transport map, and an upsampling step that is achieved by a probabilistic diffusion model with \textit{a posteriori} conditional sampling. This approach characterizes a conditional distribution without the need for paired data, and faithfully recovers relevant physical statistics from biased samples. We demonstrate the utility of the proposed approach on one- and two-dimensional fluid flow problems, which are representative of the core difficulties present in numerical simulations of weather and climate. Our method produces realistic high-resolution outputs from low-resolution inputs, by upsampling resolutions of $8\times$ and $16\times$. Moreover, our procedure correctly matches the statistics of physical quantities, even when the low-frequency content of the inputs and outputs do not match, a crucial but difficult-to-satisfy assumption needed by current state-of-the-art alternatives.
Deep Learning Models for Predicting Wildfires from Historical Remote-Sensing Data
Oct 15, 2020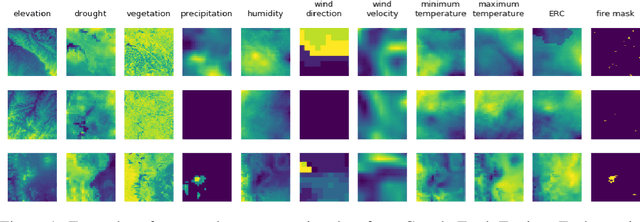
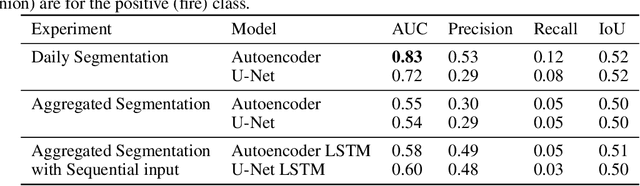
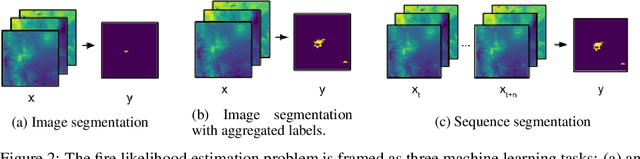

Identifying regions that have high likelihood for wildfires is a key component of land and forestry management and disaster preparedness. We create a data set by aggregating nearly a decade of remote-sensing data and historical fire records to predict wildfires. This prediction problem is framed as three machine learning tasks. Results are compared and analyzed for four different deep learning models to estimate wildfire likelihood. The results demonstrate that deep learning models can successfully identify areas of high fire likelihood using aggregated data about vegetation, weather, and topography with an AUC of 83%.
Zero-Shot Heterogeneous Transfer Learning from Recommender Systems to Cold-Start Search Retrieval
Aug 19, 2020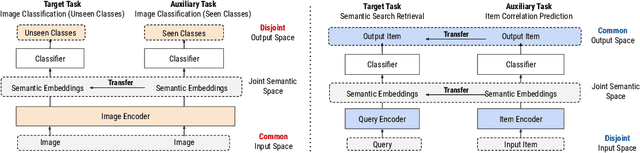

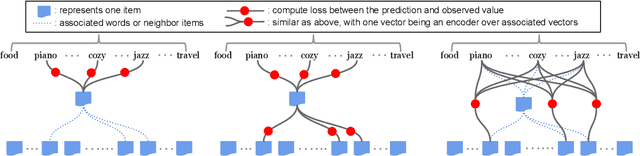
Many recent advances in neural information retrieval models, which predict top-K items given a query, learn directly from a large training set of (query, item) pairs. However, they are often insufficient when there are many previously unseen (query, item) combinations, often referred to as the cold start problem. Furthermore, the search system can be biased towards items that are frequently shown to a query previously, also known as the 'rich get richer' (a.k.a. feedback loop) problem. In light of these problems, we observed that most online content platforms have both a search and a recommender system that, while having heterogeneous input spaces, can be connected through their common output item space and a shared semantic representation. In this paper, we propose a new Zero-Shot Heterogeneous Transfer Learning framework that transfers learned knowledge from the recommender system component to improve the search component of a content platform. First, it learns representations of items and their natural-language features by predicting (item, item) correlation graphs derived from the recommender system as an auxiliary task. Then, the learned representations are transferred to solve the target search retrieval task, performing query-to-item prediction without having seen any (query, item) pairs in training. We conduct online and offline experiments on one of the world's largest search and recommender systems from Google, and present the results and lessons learned. We demonstrate that the proposed approach can achieve high performance on offline search retrieval tasks, and more importantly, achieved significant improvements on relevance and user interactions over the highly-optimized production system in online experiments.
Neural Collaborative Filtering vs. Matrix Factorization Revisited
Jun 01, 2020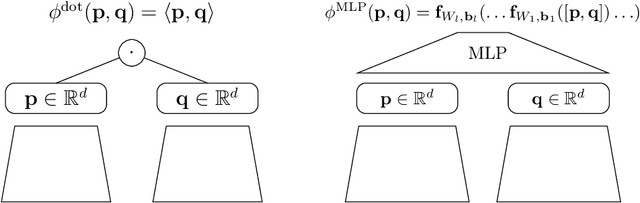
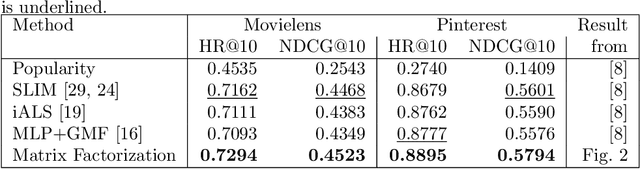
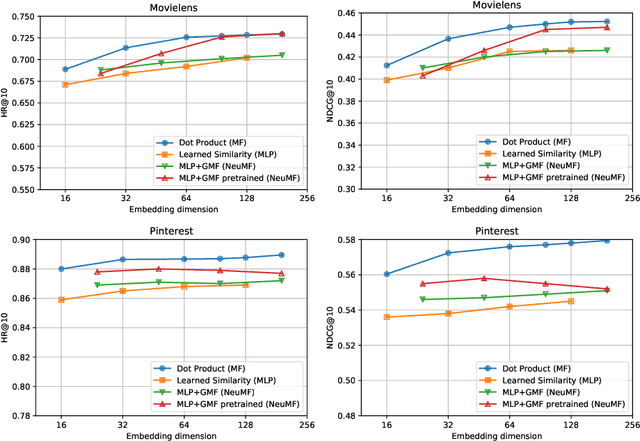
Embedding based models have been the state of the art in collaborative filtering for over a decade. Traditionally, the dot product or higher order equivalents have been used to combine two or more embeddings, e.g., most notably in matrix factorization. In recent years, it was suggested to replace the dot product with a learned similarity e.g. using a multilayer perceptron (MLP). This approach is often referred to as neural collaborative filtering (NCF). In this work, we revisit the experiments of the NCF paper that popularized learned similarities using MLPs. First, we show that with a proper hyperparameter selection, a simple dot product substantially outperforms the proposed learned similarities. Second, while a MLP can in theory approximate any function, we show that it is non-trivial to learn a dot product with an MLP. Finally, we discuss practical issues that arise when applying MLP based similarities and show that MLPs are too costly to use for item recommendation in production environments while dot products allow to apply very efficient retrieval algorithms. We conclude that MLPs should be used with care as embedding combiner and that dot products might be a better default choice.
Superbloom: Bloom filter meets Transformer
Feb 11, 2020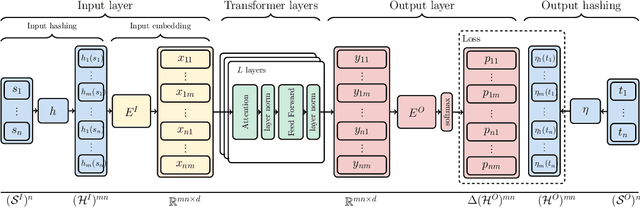

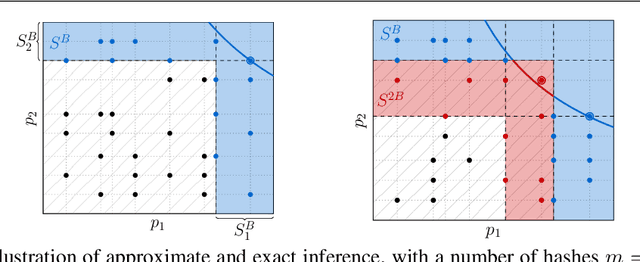
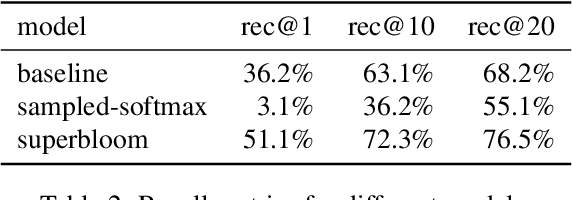
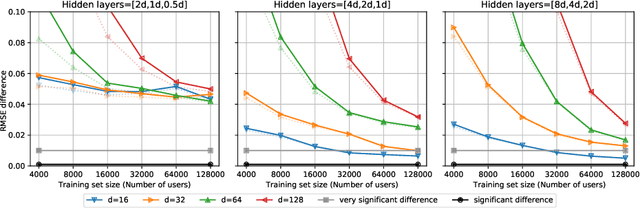
We extend the idea of word pieces in natural language models to machine learning tasks on opaque ids. This is achieved by applying hash functions to map each id to multiple hash tokens in a much smaller space, similarly to a Bloom filter. We show that by applying a multi-layer Transformer to these Bloom filter digests, we are able to obtain models with high accuracy. They outperform models of a similar size without hashing and, to a large degree, models of a much larger size trained using sampled softmax with the same computational budget. Our key observation is that it is important to use a multi-layer Transformer for Bloom filter digests to remove ambiguity in the hashed input. We believe this provides an alternative method to solving problems with large vocabulary size.
Scaling Up Collaborative Filtering Data Sets through Randomized Fractal Expansions
Apr 08, 2019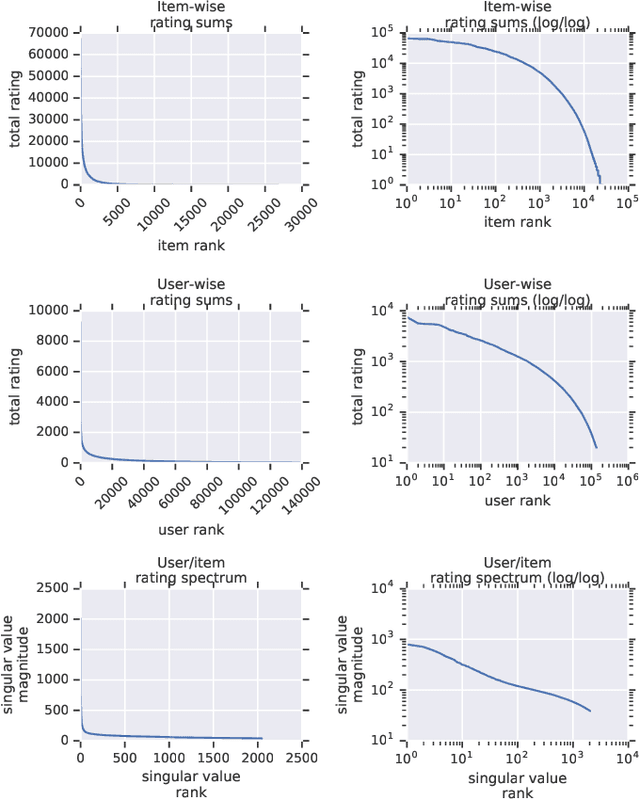
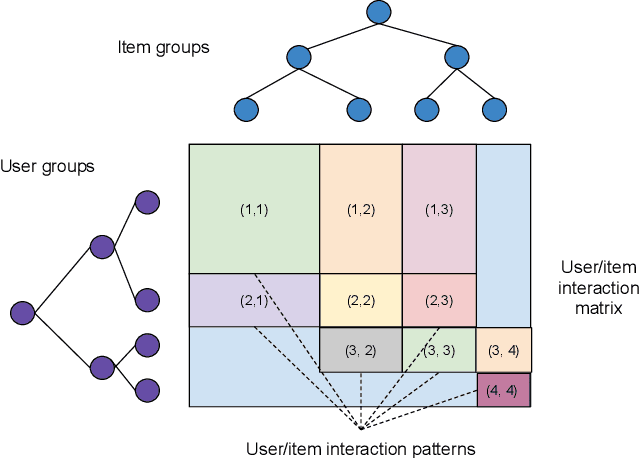
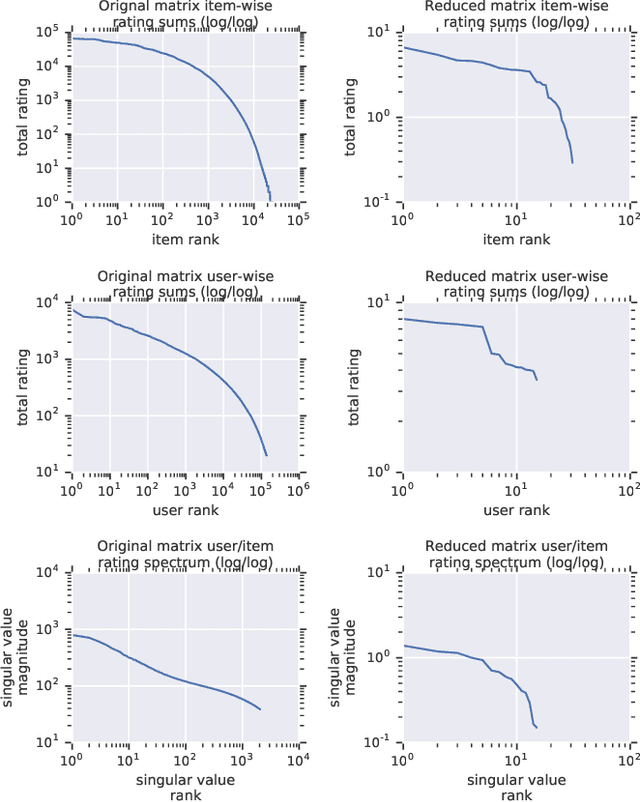
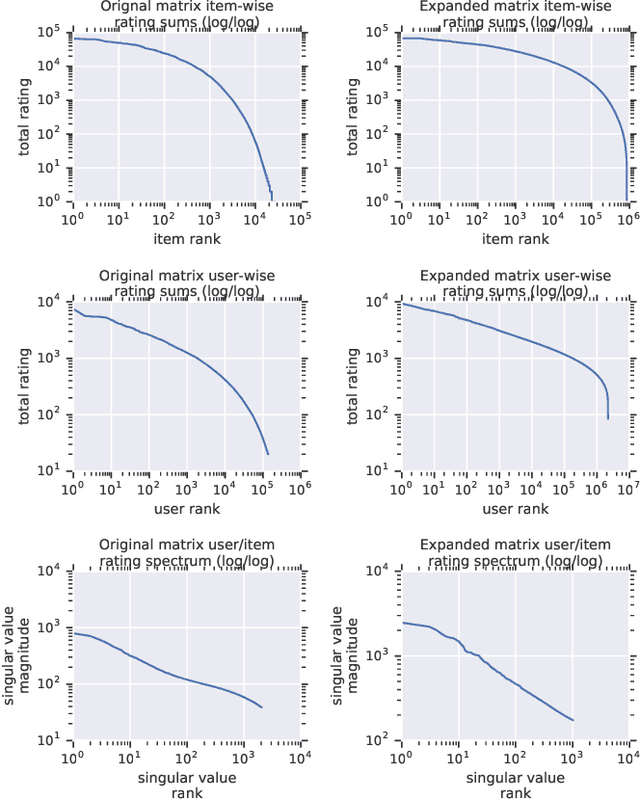
Recommender system research suffers from a disconnect between the size of academic data sets and the scale of industrial production systems. In order to bridge that gap, we propose to generate large-scale user/item interaction data sets by expanding pre-existing public data sets. Our key contribution is a technique that expands user/item incidence matrices matrices to large numbers of rows (users), columns (items), and non-zero values (interactions). The proposed method adapts Kronecker Graph Theory to preserve key higher order statistical properties such as the fat-tailed distribution of user engagements, item popularity, and singular value spectra of user/item interaction matrices. Preserving such properties is key to building large realistic synthetic data sets which in turn can be employed reliably to benchmark recommender systems and the systems employed to train them. We further apply our stochastic expansion algorithm to the binarized MovieLens 20M data set, which comprises 20M interactions between 27K movies and 138K users. The resulting expanded data set has 1.2B ratings, 2.2M users, and 855K items, which can be scaled up or down.