 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Heterogeneous Transfer Learning from Recommender Systems to Cold-Start Search Retrieval
Aug 19, 2020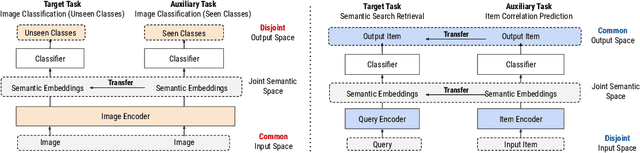

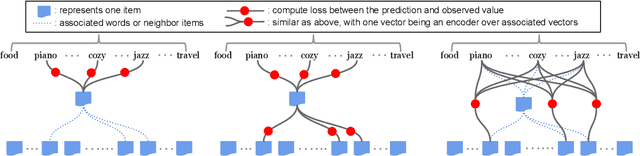
Many recent advances in neural information retrieval models, which predict top-K items given a query, learn directly from a large training set of (query, item) pairs. However, they are often insufficient when there are many previously unseen (query, item) combinations, often referred to as the cold start problem. Furthermore, the search system can be biased towards items that are frequently shown to a query previously, also known as the 'rich get richer' (a.k.a. feedback loop) problem. In light of these problems, we observed that most online content platforms have both a search and a recommender system that, while having heterogeneous input spaces, can be connected through their common output item space and a shared semantic representation. In this paper, we propose a new Zero-Shot Heterogeneous Transfer Learning framework that transfers learned knowledge from the recommender system component to improve the search component of a content platform. First, it learns representations of items and their natural-language features by predicting (item, item) correlation graphs derived from the recommender system as an auxiliary task. Then, the learned representations are transferred to solve the target search retrieval task, performing query-to-item prediction without having seen any (query, item) pairs in training. We conduct online and offline experiments on one of the world's largest search and recommender systems from Google, and present the results and lessons learned. We demonstrate that the proposed approach can achieve high performance on offline search retrieval tasks, and more importantly, achieved significant improvements on relevance and user interactions over the highly-optimized production system in online experiments.
On-the-fly Closed-loop Autonomous Materials Discovery via Bayesian Active Learning
Jun 11, 2020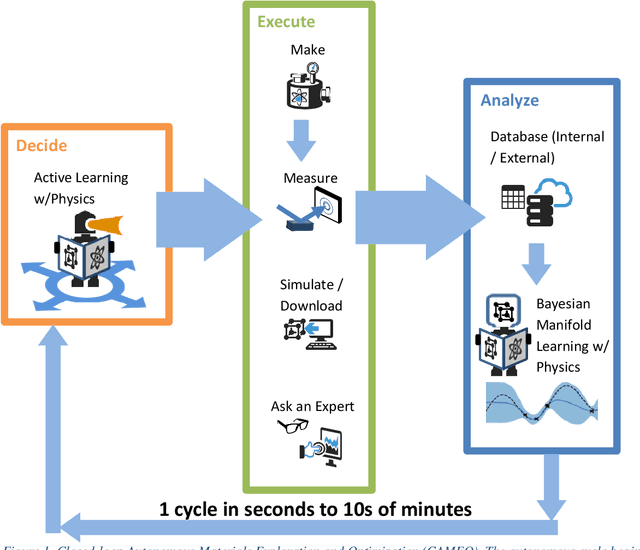
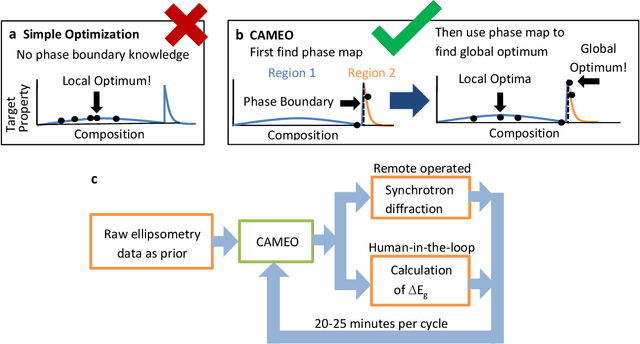
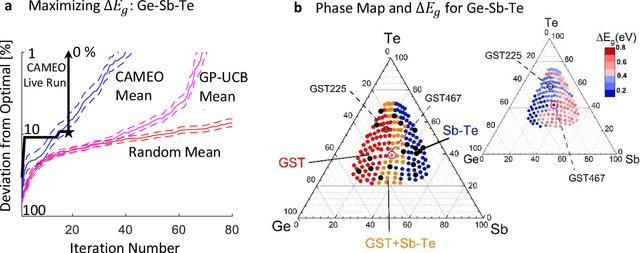
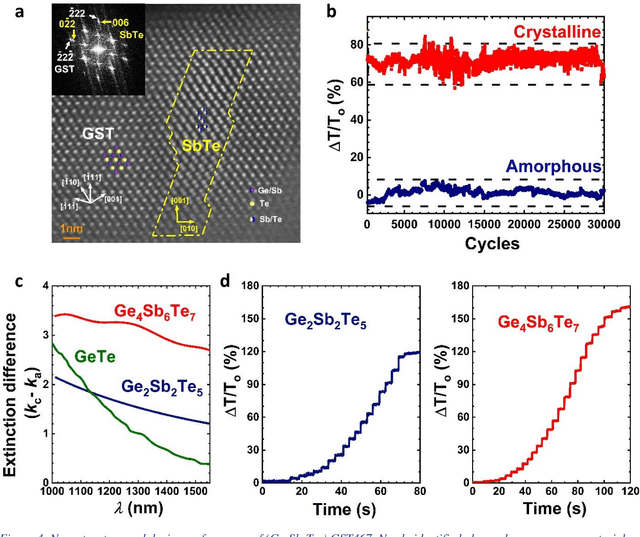
Active learning - the field of machine learning (ML) dedicated to optimal experiment design, has played a part in science as far back as the 18th century when Laplace used it to guide his discovery of celestial mechanics [1]. In this work we focus a closed-loop, active learning-driven autonomous system on another major challenge, the discovery of advanced materials against the exceedingly complex synthesis-processes-structure-property landscape. We demonstrate autonomous research methodology (i.e. autonomous hypothesis definition and evaluation) that can place complex, advanced materials in reach, allowing scientists to fail smarter, learn faster, and spend less resources in their studies, while simultaneously improving trust in scientific results and machine learning tools. Additionally, this robot science enables science-over-the-network, reducing the economic impact of scientists being physically separated from their labs. We used the real-time closed-loop, autonomous system for materials exploration and optimization (CAMEO) at the synchrotron beamline to accelerate the fundamentally interconnected tasks of rapid phase mapping and property optimization, with each cycle taking seconds to minutes, resulting in the discovery of a novel epitaxial nanocomposite phase-change memory material.
Modeling Information Need of Users in Search Sessions
Jan 03, 2020


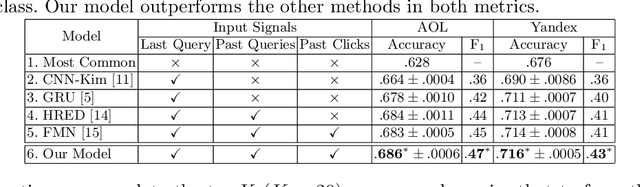
Users issue queries to Search Engines, and try to find the desired information in the results produced. They repeat this process if their information need is not met at the first place. It is crucial to identify the important words in a query that depict the actual information need of the user and will determine the course of a search session. To this end, we propose a sequence-to-sequence based neural architecture that leverages the set of past queries issued by users, and results that were explored by them. Firstly, we employ our model for predicting the words in the current query that are important and would be retained in the next query. Additionally, as a downstream application of our model, we evaluate it on the widely popular task of next query suggestion. We show that our intuitive strategy of capturing information need can yield superior performance at these tasks on two large real-world search log datasets.
Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology
May 31, 2019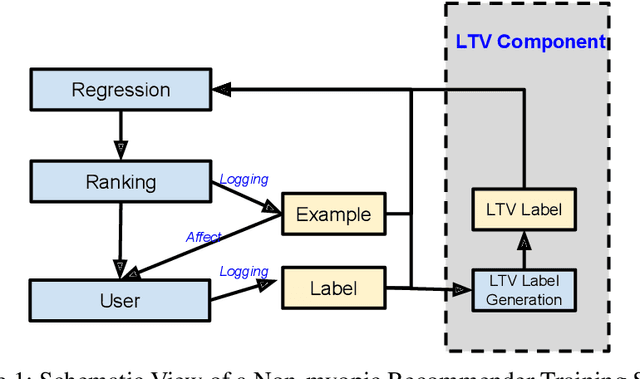
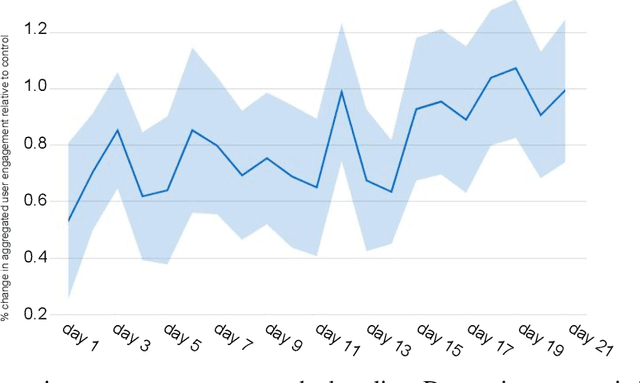
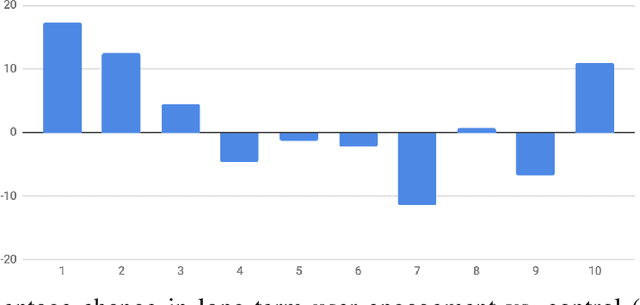
Most practical recommender systems focus on estimating immediate user engagement without considering the long-term effects of recommendations on user behavior. Reinforcement learning (RL) methods offer the potential to optimize recommendations for long-term user engagement. However, since users are often presented with slates of multiple items - which may have interacting effects on user choice - methods are required to deal with the combinatorics of the RL action space. In this work, we address the challenge of making slate-based recommendations to optimize long-term value using RL. Our contributions are three-fold. (i) We develop SLATEQ, a decomposition of value-based temporal-difference and Q-learning that renders RL tractable with slates. Under mild assumptions on user choice behavior, we show that the long-term value (LTV) of a slate can be decomposed into a tractable function of its component item-wise LTVs. (ii) We outline a methodology that leverages existing myopic learning-based recommenders to quickly develop a recommender that handles LTV. (iii) We demonstrate our methods in simulation, and validate the scalability of decomposed TD-learning using SLATEQ in live experiments on YouTube.