 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep State-Space Generative Model For Correlated Time-to-Event Predictions
Jul 28, 2024



Capturing the inter-dependencies among multiple types of clinically-critical events is critical not only to accurate future event prediction, but also to better treatment planning. In this work, we propose a deep latent state-space generative model to capture the interactions among different types of correlated clinical events (e.g., kidney failure, mortality) by explicitly modeling the temporal dynamics of patients' latent states. Based on these learned patient states, we further develop a new general discrete-time formulation of the hazard rate function to estimate the survival distribution of patients with significantly improved accuracy. Extensive evaluations over real EMR data show that our proposed model compares favorably to various state-of-the-art baselines. Furthermore, our method also uncovers meaningful insights about the latent correlations among mortality and different types of organ failures.
NATURAL PLAN: Benchmarking LLMs on Natural Language Planning
Jun 06, 2024



We introduce NATURAL PLAN, a realistic planning benchmark in natural language containing 3 key tasks: Trip Planning, Meeting Planning, and Calendar Scheduling. We focus our evaluation on the planning capabilities of LLMs with full information on the task, by providing outputs from tools such as Google Flights, Google Maps, and Google Calendar as contexts to the models. This eliminates the need for a tool-use environment for evaluating LLMs on Planning. We observe that NATURAL PLAN is a challenging benchmark for state of the art models. For example, in Trip Planning, GPT-4 and Gemini 1.5 Pro could only achieve 31.1% and 34.8% solve rate respectively. We find that model performance drops drastically as the complexity of the problem increases: all models perform below 5% when there are 10 cities, highlighting a significant gap in planning in natural language for SoTA LLMs. We also conduct extensive ablation studies on NATURAL PLAN to further shed light on the (in)effectiveness of approaches such as self-correction, few-shot generalization, and in-context planning with long-contexts on improving LLM planning.
CRISPR-GPT: An LLM Agent for Automated Design of Gene-Editing Experiments
Apr 27, 2024The introduction of genome engineering technology has transformed biomedical research, making it possible to make precise changes to genetic information. However, creating an efficient gene-editing system requires a deep understanding of CRISPR technology, and the complex experimental systems under investigation. While Large Language Models (LLMs) have shown promise in various tasks, they often lack specific knowledge and struggle to accurately solve biological design problems. In this work, we introduce CRISPR-GPT, an LLM agent augmented with domain knowledge and external tools to automate and enhance the design process of CRISPR-based gene-editing experiments. CRISPR-GPT leverages the reasoning ability of LLMs to facilitate the process of selecting CRISPR systems, designing guide RNAs, recommending cellular delivery methods, drafting protocols, and designing validation experiments to confirm editing outcomes. We showcase the potential of CRISPR-GPT for assisting non-expert researchers with gene-editing experiments from scratch and validate the agent's effectiveness in a real-world use case. Furthermore, we explore the ethical and regulatory considerations associated with automated gene-editing design, highlighting the need for responsible and transparent use of these tools. Our work aims to bridge the gap between beginner biological researchers and CRISPR genome engineering techniques, and demonstrate the potential of LLM agents in facilitating complex biological discovery tasks.
Best Practices and Lessons Learned on Synthetic Data for Language Models
Apr 11, 2024
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
Chain of Thought Empowers Transformers to Solve Inherently Serial Problems
Feb 20, 2024
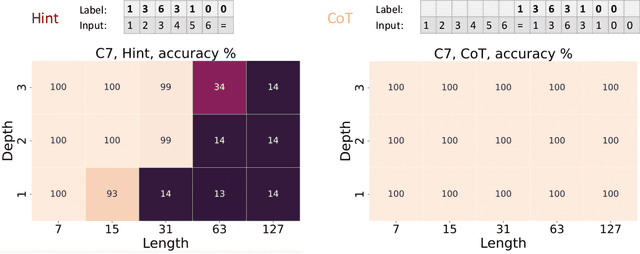

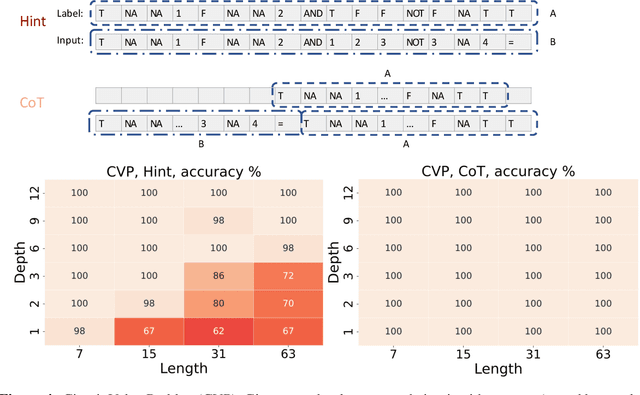
Instructing the model to generate a sequence of intermediate steps, a.k.a., a chain of thought (CoT), is a highly effective method to improve the accuracy of large language models (LLMs) on arithmetics and symbolic reasoning tasks. However, the mechanism behind CoT remains unclear. This work provides a theoretical understanding of the power of CoT for decoder-only transformers through the lens of expressiveness. Conceptually, CoT empowers the model with the ability to perform inherently serial computation, which is otherwise lacking in transformers, especially when depth is low. Given input length $n$, previous works have shown that constant-depth transformers with finite precision $\mathsf{poly}(n)$ embedding size can only solve problems in $\mathsf{TC}^0$ without CoT. We first show an even tighter expressiveness upper bound for constant-depth transformers with constant-bit precision, which can only solve problems in $\mathsf{AC}^0$, a proper subset of $ \mathsf{TC}^0$. However, with $T$ steps of CoT, constant-depth transformers using constant-bit precision and $O(\log n)$ embedding size can solve any problem solvable by boolean circuits of size $T$. Empirically, enabling CoT dramatically improves the accuracy for tasks that are hard for parallel computation, including the composition of permutation groups, iterated squaring, and circuit value problems, especially for low-depth transformers.
Chain-of-Thought Reasoning Without Prompting
Feb 15, 2024

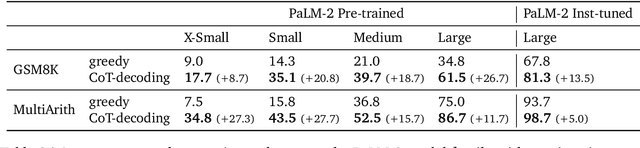

In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) prompting. These methods, while effective, often involve manually intensive prompt engineering. Our study takes a novel approach by asking: Can LLMs reason effectively without prompting? Our findings reveal that, intriguingly, CoT reasoning paths can be elicited from pre-trained LLMs by simply altering the \textit{decoding} process. Rather than conventional greedy decoding, we investigate the top-$k$ alternative tokens, uncovering that CoT paths are frequently inherent in these sequences. This approach not only bypasses the confounders of prompting but also allows us to assess the LLMs' \textit{intrinsic} reasoning abilities. Moreover, we observe that the presence of a CoT in the decoding path correlates with a higher confidence in the model's decoded answer. This confidence metric effectively differentiates between CoT and non-CoT paths. Extensive empirical studies on various reasoning benchmarks show that the proposed CoT-decoding substantially outperforms the standard greedy decoding.
Transformers Can Achieve Length Generalization But Not Robustly
Feb 14, 2024



Length generalization, defined as the ability to extrapolate from shorter training sequences to longer test ones, is a significant challenge for language models. This issue persists even with large-scale Transformers handling relatively straightforward tasks. In this paper, we test the Transformer's ability of length generalization using the task of addition of two integers. We show that the success of length generalization is intricately linked to the data format and the type of position encoding. Using the right combination of data format and position encodings, we show for the first time that standard Transformers can extrapolate to a sequence length that is 2.5x the input length. Nevertheless, unlike in-distribution generalization, length generalization remains fragile, significantly influenced by factors like random weight initialization and training data order, leading to large variances across different random seeds.
Premise Order Matters in Reasoning with Large Language Models
Feb 14, 2024
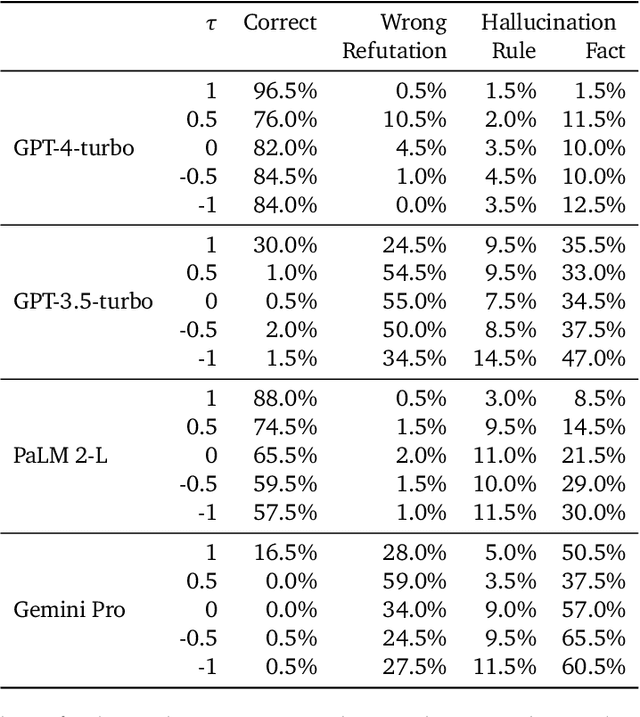


Large language models (LLMs) have accomplished remarkable reasoning performance in various domains. However, in the domain of reasoning tasks, we discover a frailty: LLMs are surprisingly brittle to the ordering of the premises, despite the fact that such ordering does not alter the underlying task. In particular, we observe that LLMs achieve the best performance when the premise order aligns with the context required in intermediate reasoning steps. For example, in deductive reasoning tasks, presenting the premises in the same order as the ground truth proof in the prompt (as opposed to random ordering) drastically increases the model's accuracy. We first examine the effect of premise ordering on deductive reasoning on a variety of LLMs, and our evaluation shows that permuting the premise order can cause a performance drop of over 30%. In addition, we release the benchmark R-GSM, based on GSM8K, to examine the ordering effect for mathematical problem-solving, and we again observe a significant drop in accuracy, relative to the original GSM8K benchmark.
Self-Discover: Large Language Models Self-Compose Reasoning Structures
Feb 06, 2024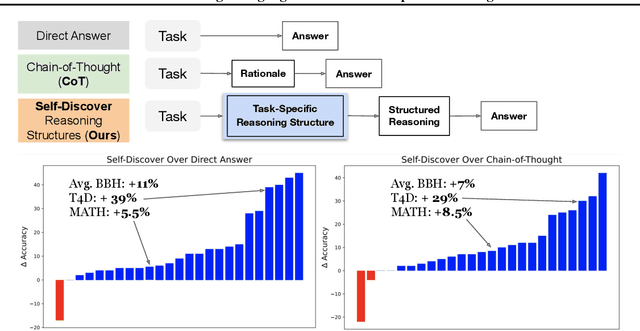



We introduce SELF-DISCOVER, a general framework for LLMs to self-discover the task-intrinsic reasoning structures to tackle complex reasoning problems that are challenging for typical prompting methods. Core to the framework is a self-discovery process where LLMs select multiple atomic reasoning modules such as critical thinking and step-by-step thinking, and compose them into an explicit reasoning structure for LLMs to follow during decoding. SELF-DISCOVER substantially improves GPT-4 and PaLM 2's performance on challenging reasoning benchmarks such as BigBench-Hard, grounded agent reasoning, and MATH, by as much as 32% compared to Chain of Thought (CoT). Furthermore, SELF-DISCOVER outperforms inference-intensive methods such as CoT-Self-Consistency by more than 20%, while requiring 10-40x fewer inference compute. Finally, we show that the self-discovered reasoning structures are universally applicable across model families: from PaLM 2-L to GPT-4, and from GPT-4 to Llama2, and share commonalities with human reasoning patterns.
Universal Self-Consistency for Large Language Model Generation
Nov 29, 2023



Self-consistency with chain-of-thought prompting (CoT) has demonstrated remarkable performance gains on various challenging tasks, by utilizing multiple reasoning paths sampled from large language models (LLMs). However, self-consistency relies on the answer extraction process to aggregate multiple solutions, which is not applicable to free-form answers. In this work, we propose Universal Self-Consistency (USC), which leverages LLMs themselves to select the most consistent answer among multiple candidates. We evaluate USC on a variety of benchmarks, including mathematical reasoning, code generation, long-context summarization, and open-ended question answering. On open-ended generation tasks where the original self-consistency method is not applicable, USC effectively utilizes multiple samples and improves the performance. For mathematical reasoning, USC matches the standard self-consistency performance without requiring the answer formats to be similar. Finally, without access to execution results, USC also matches the execution-based voting performance on code generation.