 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen ASR Leaderboard: Towards Reproducible and Transparent Multilingual and Long-Form Speech Recognition Evaluation
Oct 08, 2025Despite rapid progress, ASR evaluation remains saturated with short-form English, and efficiency is rarely reported. We present the Open ASR Leaderboard, a fully reproducible benchmark and interactive leaderboard comparing 60+ open-source and proprietary systems across 11 datasets, including dedicated multilingual and long-form tracks. We standardize text normalization and report both word error rate (WER) and inverse real-time factor (RTFx), enabling fair accuracy-efficiency comparisons. For English transcription, Conformer encoders paired with LLM decoders achieve the best average WER but are slower, while CTC and TDT decoders deliver much better RTFx, making them attractive for long-form and offline use. Whisper-derived encoders fine-tuned for English improve accuracy but often trade off multilingual coverage. All code and dataset loaders are open-sourced to support transparent, extensible evaluation.
Anti-Money Laundering Machine Learning Pipelines; A Technical Analysis on Identifying High-risk Bank Clients with Supervised Learning
Sep 11, 2025Anti-money laundering (AML) actions and measurements are among the priorities of financial institutions, for which machine learning (ML) has shown to have a high potential. In this paper, we propose a comprehensive and systematic approach for developing ML pipelines to identify high-risk bank clients in a dataset curated for Task 1 of the University of Toronto 2023-2024 Institute for Management and Innovation (IMI) Big Data and Artificial Intelligence Competition. The dataset included 195,789 customer IDs, and we employed a 16-step design and statistical analysis to ensure the final pipeline was robust. We also framed the data in a SQLite database, developed SQL-based feature engineering algorithms, connected our pre-trained model to the database, and made it inference-ready, and provided explainable artificial intelligence (XAI) modules to derive feature importance. Our pipeline achieved a mean area under the receiver operating characteristic curve (AUROC) of 0.961 with a standard deviation (SD) of 0.005. The proposed pipeline achieved second place in the competition.
Human-Level Competitive Pokémon via Scalable Offline Reinforcement Learning with Transformers
Apr 06, 2025Competitive Pok\'emon Singles (CPS) is a popular strategy game where players learn to exploit their opponent based on imperfect information in battles that can last more than one hundred stochastic turns. AI research in CPS has been led by heuristic tree search and online self-play, but the game may also create a platform to study adaptive policies trained offline on large datasets. We develop a pipeline to reconstruct the first-person perspective of an agent from logs saved from the third-person perspective of a spectator, thereby unlocking a dataset of real human battles spanning more than a decade that grows larger every day. This dataset enables a black-box approach where we train large sequence models to adapt to their opponent based solely on their input trajectory while selecting moves without explicit search of any kind. We study a progression from imitation learning to offline RL and offline fine-tuning on self-play data in the hardcore competitive setting of Pok\'emon's four oldest (and most partially observed) game generations. The resulting agents outperform a recent LLM Agent approach and a strong heuristic search engine. While playing anonymously in online battles against humans, our best agents climb to rankings inside the top 10% of active players.
Best Practices and Lessons Learned on Synthetic Data for Language Models
Apr 11, 2024
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
In-Context Principle Learning from Mistakes
Feb 09, 2024

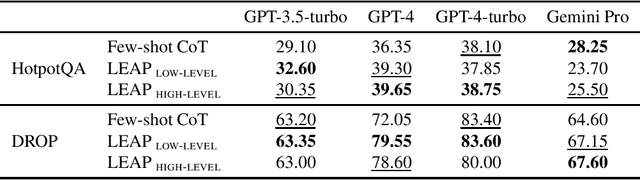

In-context learning (ICL, also known as few-shot prompting) has been the standard method of adapting LLMs to downstream tasks, by learning from a few input-output examples. Nonetheless, all ICL-based approaches only learn from correct input-output pairs. In this paper, we revisit this paradigm, by learning more from the few given input-output examples. We introduce Learning Principles (LEAP): First, we intentionally induce the model to make mistakes on these few examples; then we reflect on these mistakes, and learn explicit task-specific "principles" from them, which help solve similar problems and avoid common mistakes; finally, we prompt the model to answer unseen test questions using the original few-shot examples and these learned general principles. We evaluate LEAP on a wide range of benchmarks, including multi-hop question answering (Hotpot QA), textual QA (DROP), Big-Bench Hard reasoning, and math problems (GSM8K and MATH); in all these benchmarks, LEAP improves the strongest available LLMs such as GPT-3.5-turbo, GPT-4, GPT-4 turbo and Claude-2.1. For example, LEAP improves over the standard few-shot prompting using GPT-4 by 7.5% in DROP, and by 3.3% in HotpotQA. Importantly, LEAP does not require any more input or examples than the standard few-shot prompting settings.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.