 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe PokeAgent Challenge: Competitive and Long-Context Learning at Scale
Mar 17, 2026We present the PokeAgent Challenge, a large-scale benchmark for decision-making research built on Pokemon's multi-agent battle system and expansive role-playing game (RPG) environment. Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems for frontier AI, yet few benchmarks stress all three simultaneously under realistic conditions. PokeAgent targets these limitations at scale through two complementary tracks: our Battling Track, which calls for strategic reasoning and generalization under partial observability in competitive Pokemon battles, and our Speedrunning Track, which requires long-horizon planning and sequential decision-making in the Pokemon RPG. Our Battling Track supplies a dataset of 20M+ battle trajectories alongside a suite of heuristic, RL, and LLM-based baselines capable of high-level competitive play. Our Speedrunning Track provides the first standardized evaluation framework for RPG speedrunning, including an open-source multi-agent orchestration system for modular, reproducible comparisons of harness-based LLM approaches. Our NeurIPS 2025 competition validates both the quality of our resources and the research community's interest in Pokemon, with over 100 teams competing across both tracks and winning solutions detailed in our paper. Participant submissions and our baselines reveal considerable gaps between generalist (LLM), specialist (RL), and elite human performance. Analysis against the BenchPress evaluation matrix shows that Pokemon battling is nearly orthogonal to standard LLM benchmarks, measuring capabilities not captured by existing suites and positioning Pokemon as an unsolved benchmark that can drive RL and LLM research forward. We transition to a living benchmark with a live leaderboard for Battling and self-contained evaluation for Speedrunning at https://pokeagentchallenge.com.
VLM Q-Learning: Aligning Vision-Language Models for Interactive Decision-Making
May 06, 2025Recent research looks to harness the general knowledge and reasoning of large language models (LLMs) into agents that accomplish user-specified goals in interactive environments. Vision-language models (VLMs) extend LLMs to multi-modal data and provide agents with the visual reasoning necessary for new applications in areas such as computer automation. However, agent tasks emphasize skills where accessible open-weight VLMs lag behind their LLM equivalents. For example, VLMs are less capable of following an environment's strict output syntax requirements and are more focused on open-ended question answering. Overcoming these limitations requires supervised fine-tuning (SFT) on task-specific expert demonstrations. Our work approaches these challenges from an offline-to-online reinforcement learning (RL) perspective. RL lets us fine-tune VLMs to agent tasks while learning from the unsuccessful decisions of our own model or more capable (larger) models. We explore an off-policy RL solution that retains the stability and simplicity of the widely used SFT workflow while allowing our agent to self-improve and learn from low-quality datasets. We demonstrate this technique with two open-weight VLMs across three multi-modal agent domains.
Human-Level Competitive Pokémon via Scalable Offline Reinforcement Learning with Transformers
Apr 06, 2025Competitive Pok\'emon Singles (CPS) is a popular strategy game where players learn to exploit their opponent based on imperfect information in battles that can last more than one hundred stochastic turns. AI research in CPS has been led by heuristic tree search and online self-play, but the game may also create a platform to study adaptive policies trained offline on large datasets. We develop a pipeline to reconstruct the first-person perspective of an agent from logs saved from the third-person perspective of a spectator, thereby unlocking a dataset of real human battles spanning more than a decade that grows larger every day. This dataset enables a black-box approach where we train large sequence models to adapt to their opponent based solely on their input trajectory while selecting moves without explicit search of any kind. We study a progression from imitation learning to offline RL and offline fine-tuning on self-play data in the hardcore competitive setting of Pok\'emon's four oldest (and most partially observed) game generations. The resulting agents outperform a recent LLM Agent approach and a strong heuristic search engine. While playing anonymously in online battles against humans, our best agents climb to rankings inside the top 10% of active players.
AMAGO-2: Breaking the Multi-Task Barrier in Meta-Reinforcement Learning with Transformers
Nov 17, 2024



Language models trained on diverse datasets unlock generalization by in-context learning. Reinforcement Learning (RL) policies can achieve a similar effect by meta-learning within the memory of a sequence model. However, meta-RL research primarily focuses on adapting to minor variations of a single task. It is difficult to scale towards more general behavior without confronting challenges in multi-task optimization, and few solutions are compatible with meta-RL's goal of learning from large training sets of unlabeled tasks. To address this challenge, we revisit the idea that multi-task RL is bottlenecked by imbalanced training losses created by uneven return scales across different tasks. We build upon recent advancements in Transformer-based (in-context) meta-RL and evaluate a simple yet scalable solution where both an agent's actor and critic objectives are converted to classification terms that decouple optimization from the current scale of returns. Large-scale comparisons in Meta-World ML45, Multi-Game Procgen, Multi-Task POPGym, Multi-Game Atari, and BabyAI find that this design unlocks significant progress in online multi-task adaptation and memory problems without explicit task labels.
AMAGO: Scalable In-Context Reinforcement Learning for Adaptive Agents
Nov 05, 2023We introduce AMAGO, an in-context Reinforcement Learning (RL) agent that uses sequence models to tackle the challenges of generalization, long-term memory, and meta-learning. Recent works have shown that off-policy learning can make in-context RL with recurrent policies viable. Nonetheless, these approaches require extensive tuning and limit scalability by creating key bottlenecks in agents' memory capacity, planning horizon, and model size. AMAGO revisits and redesigns the off-policy in-context approach to successfully train long-sequence Transformers over entire rollouts in parallel with end-to-end RL. Our agent is uniquely scalable and applicable to a wide range of problems. We demonstrate its strong performance empirically in meta-RL and long-term memory domains. AMAGO's focus on sparse rewards and off-policy data also allows in-context learning to extend to goal-conditioned problems with challenging exploration. When combined with a novel hindsight relabeling scheme, AMAGO can solve a previously difficult category of open-world domains, where agents complete many possible instructions in procedurally generated environments. We evaluate our agent on three goal-conditioned domains and study how its individual improvements connect to create a generalist policy.
Cross-Episodic Curriculum for Transformer Agents
Oct 12, 2023



We present a new algorithm, Cross-Episodic Curriculum (CEC), to boost the learning efficiency and generalization of Transformer agents. Central to CEC is the placement of cross-episodic experiences into a Transformer's context, which forms the basis of a curriculum. By sequentially structuring online learning trials and mixed-quality demonstrations, CEC constructs curricula that encapsulate learning progression and proficiency increase across episodes. Such synergy combined with the potent pattern recognition capabilities of Transformer models delivers a powerful cross-episodic attention mechanism. The effectiveness of CEC is demonstrated under two representative scenarios: one involving multi-task reinforcement learning with discrete control, such as in DeepMind Lab, where the curriculum captures the learning progression in both individual and progressively complex settings; and the other involving imitation learning with mixed-quality data for continuous control, as seen in RoboMimic, where the curriculum captures the improvement in demonstrators' expertise. In all instances, policies resulting from CEC exhibit superior performance and strong generalization. Code is open-sourced at https://cec-agent.github.io/ to facilitate research on Transformer agent learning.
PGrad: Learning Principal Gradients For Domain Generalization
May 02, 2023Machine learning models fail to perform when facing out-of-distribution (OOD) domains, a challenging task known as domain generalization (DG). In this work, we develop a novel DG training strategy, we call PGrad, to learn a robust gradient direction, improving models' generalization ability on unseen domains. The proposed gradient aggregates the principal directions of a sampled roll-out optimization trajectory that measures the training dynamics across all training domains. PGrad's gradient design forces the DG training to ignore domain-dependent noise signals and updates all training domains with a robust direction covering main components of parameter dynamics. We further improve PGrad via bijection-based computational refinement and directional plus length-based calibrations. Our theoretical proof connects PGrad to the spectral analysis of Hessian in training neural networks. Experiments on DomainBed and WILDS benchmarks demonstrate that our approach effectively enables robust DG optimization and leads to smoothly decreased loss curves. Empirically, PGrad achieves competitive results across seven datasets, demonstrating its efficacy across both synthetic and real-world distributional shifts. Code is available at https://github.com/QData/PGrad.
Launchpad: Learning to Schedule Using Offline and Online RL Methods
Dec 02, 2022Deep reinforcement learning algorithms have succeeded in several challenging domains. Classic Online RL job schedulers can learn efficient scheduling strategies but often takes thousands of timesteps to explore the environment and adapt from a randomly initialized DNN policy. Existing RL schedulers overlook the importance of learning from historical data and improving upon custom heuristic policies. Offline reinforcement learning presents the prospect of policy optimization from pre-recorded datasets without online environment interaction. Following the recent success of data-driven learning, we explore two RL methods: 1) Behaviour Cloning and 2) Offline RL, which aim to learn policies from logged data without interacting with the environment. These methods address the challenges concerning the cost of data collection and safety, particularly pertinent to real-world applications of RL. Although the data-driven RL methods generate good results, we show that the performance is highly dependent on the quality of the historical datasets. Finally, we demonstrate that by effectively incorporating prior expert demonstrations to pre-train the agent, we short-circuit the random exploration phase to learn a reasonable policy with online training. We utilize Offline RL as a launchpad to learn effective scheduling policies from prior experience collected using Oracle or heuristic policies. Such a framework is effective for pre-training from historical datasets and well suited to continuous improvement with online data collection.
RARE: Renewable Energy Aware Resource Management in Datacenters
Nov 10, 2022



The exponential growth in demand for digital services drives massive datacenter energy consumption and negative environmental impacts. Promoting sustainable solutions to pressing energy and digital infrastructure challenges is crucial. Several hyperscale cloud providers have announced plans to power their datacenters using renewable energy. However, integrating renewables to power the datacenters is challenging because the power generation is intermittent, necessitating approaches to tackle power supply variability. Hand engineering domain-specific heuristics-based schedulers to meet specific objective functions in such complex dynamic green datacenter environments is time-consuming, expensive, and requires extensive tuning by domain experts. The green datacenters need smart systems and system software to employ multiple renewable energy sources (wind and solar) by intelligently adapting computing to renewable energy generation. We present RARE (Renewable energy Aware REsource management), a Deep Reinforcement Learning (DRL) job scheduler that automatically learns effective job scheduling policies while continually adapting to datacenters' complex dynamic environment. The resulting DRL scheduler performs better than heuristic scheduling policies with different workloads and adapts to the intermittent power supply from renewables. We demonstrate DRL scheduler system design parameters that, when tuned correctly, produce better performance. Finally, we demonstrate that the DRL scheduler can learn from and improve upon existing heuristic policies using Offline Learning.
A Closer Look at Advantage-Filtered Behavioral Cloning in High-Noise Datasets
Oct 10, 2021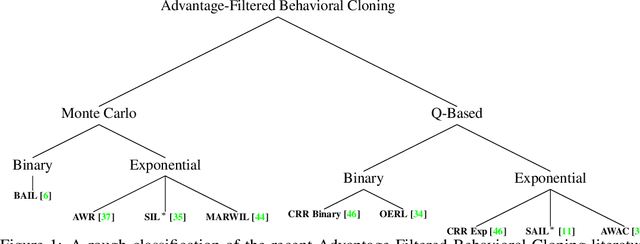
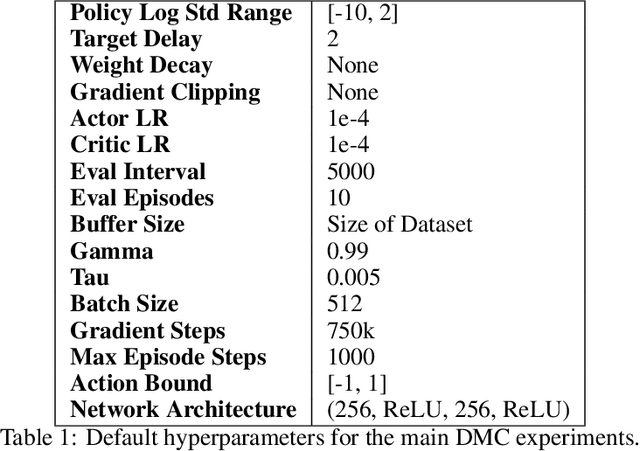
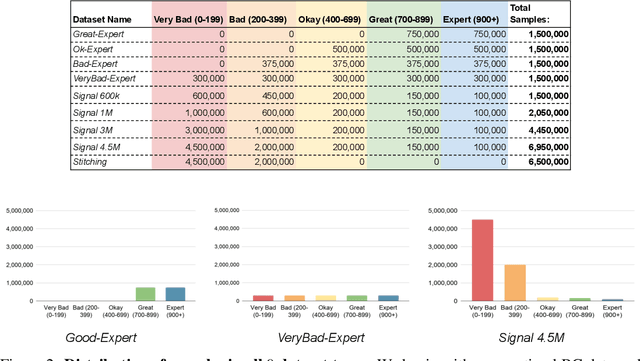

Recent Offline Reinforcement Learning methods have succeeded in learning high-performance policies from fixed datasets of experience. A particularly effective approach learns to first identify and then mimic optimal decision-making strategies. Our work evaluates this method's ability to scale to vast datasets consisting almost entirely of sub-optimal noise. A thorough investigation on a custom benchmark helps identify several key challenges involved in learning from high-noise datasets. We re-purpose prioritized experience sampling to locate expert-level demonstrations among millions of low-performance samples. This modification enables offline agents to learn state-of-the-art policies in benchmark tasks using datasets where expert actions are outnumbered nearly 65:1.