 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Evaluation of Generative Models in Calorimeter Shower Simulation
Jun 08, 2024

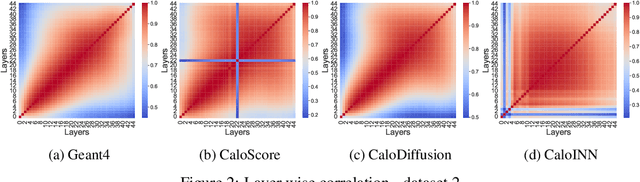
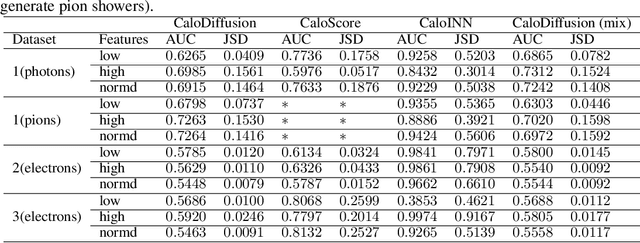
The pursuit of understanding fundamental particle interactions has reached unparalleled precision levels. Particle physics detectors play a crucial role in generating low-level object signatures that encode collision physics. However, simulating these particle collisions is a demanding task in terms of memory and computation which will be exasperated with larger data volumes, more complex detectors, and a higher pileup environment in the High-Luminosity LHC. The introduction of "Fast Simulation" has been pivotal in overcoming computational bottlenecks. The use of deep-generative models has sparked a surge of interest in surrogate modeling for detector simulations, generating particle showers that closely resemble the observed data. Nonetheless, there is a pressing need for a comprehensive evaluation of their performance using a standardized set of metrics. In this study, we conducted a rigorous evaluation of three generative models using standard datasets and a diverse set of metrics derived from physics, computer vision, and statistics. Furthermore, we explored the impact of using full versus mixed precision modes during inference. Our evaluation revealed that the CaloDiffusion and CaloScore generative models demonstrate the most accurate simulation of particle showers, yet there remains substantial room for improvement. Our findings identified areas where the evaluated models fell short in accurately replicating Geant4 data.
Launchpad: Learning to Schedule Using Offline and Online RL Methods
Dec 02, 2022Deep reinforcement learning algorithms have succeeded in several challenging domains. Classic Online RL job schedulers can learn efficient scheduling strategies but often takes thousands of timesteps to explore the environment and adapt from a randomly initialized DNN policy. Existing RL schedulers overlook the importance of learning from historical data and improving upon custom heuristic policies. Offline reinforcement learning presents the prospect of policy optimization from pre-recorded datasets without online environment interaction. Following the recent success of data-driven learning, we explore two RL methods: 1) Behaviour Cloning and 2) Offline RL, which aim to learn policies from logged data without interacting with the environment. These methods address the challenges concerning the cost of data collection and safety, particularly pertinent to real-world applications of RL. Although the data-driven RL methods generate good results, we show that the performance is highly dependent on the quality of the historical datasets. Finally, we demonstrate that by effectively incorporating prior expert demonstrations to pre-train the agent, we short-circuit the random exploration phase to learn a reasonable policy with online training. We utilize Offline RL as a launchpad to learn effective scheduling policies from prior experience collected using Oracle or heuristic policies. Such a framework is effective for pre-training from historical datasets and well suited to continuous improvement with online data collection.
RARE: Renewable Energy Aware Resource Management in Datacenters
Nov 10, 2022



The exponential growth in demand for digital services drives massive datacenter energy consumption and negative environmental impacts. Promoting sustainable solutions to pressing energy and digital infrastructure challenges is crucial. Several hyperscale cloud providers have announced plans to power their datacenters using renewable energy. However, integrating renewables to power the datacenters is challenging because the power generation is intermittent, necessitating approaches to tackle power supply variability. Hand engineering domain-specific heuristics-based schedulers to meet specific objective functions in such complex dynamic green datacenter environments is time-consuming, expensive, and requires extensive tuning by domain experts. The green datacenters need smart systems and system software to employ multiple renewable energy sources (wind and solar) by intelligently adapting computing to renewable energy generation. We present RARE (Renewable energy Aware REsource management), a Deep Reinforcement Learning (DRL) job scheduler that automatically learns effective job scheduling policies while continually adapting to datacenters' complex dynamic environment. The resulting DRL scheduler performs better than heuristic scheduling policies with different workloads and adapts to the intermittent power supply from renewables. We demonstrate DRL scheduler system design parameters that, when tuned correctly, produce better performance. Finally, we demonstrate that the DRL scheduler can learn from and improve upon existing heuristic policies using Offline Learning.
Job Scheduling in Datacenters using Constraint Controlled RL
Nov 10, 2022

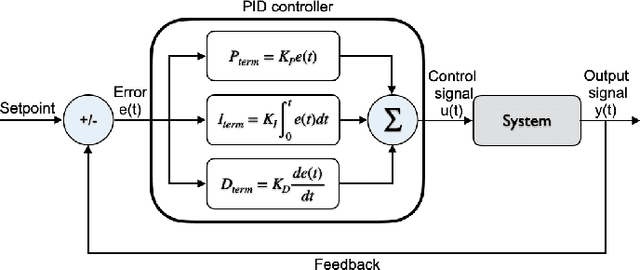

This paper studies a model for online job scheduling in green datacenters. In green datacenters, resource availability depends on the power supply from the renewables. Intermittent power supply from renewables leads to intermittent resource availability, inducing job delays (and associated costs). Green datacenter operators must intelligently manage their workloads and available power supply to extract maximum benefits. The scheduler's objective is to schedule jobs on a set of resources to maximize the total value (revenue) while minimizing the overall job delay. A trade-off exists between achieving high job value on the one hand and low expected delays on the other. Hence, the aims of achieving high rewards and low costs are in opposition. In addition, datacenter operators often prioritize multiple objectives, including high system utilization and job completion. To accomplish the opposing goals of maximizing total job value and minimizing job delays, we apply the Proportional-Integral-Derivative (PID) Lagrangian methods in Deep Reinforcement Learning to job scheduling problem in the green datacenter environment. Lagrangian methods are widely used algorithms for constrained optimization problems. We adopt a controls perspective to learn the Lagrange multiplier with proportional, integral, and derivative control, achieving favorable learning dynamics. Feedback control defines cost terms for the learning agent, monitors the cost limits during training, and continuously adjusts the learning parameters to achieve stable performance. Our experiments demonstrate improved performance compared to scheduling policies without the PID Lagrangian methods. Experimental results illustrate the effectiveness of the Constraint Controlled Reinforcement Learning (CoCoRL) scheduler that simultaneously satisfies multiple objectives.