 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Advantage-Filtered Behavioral Cloning in High-Noise Datasets
Paper and Code
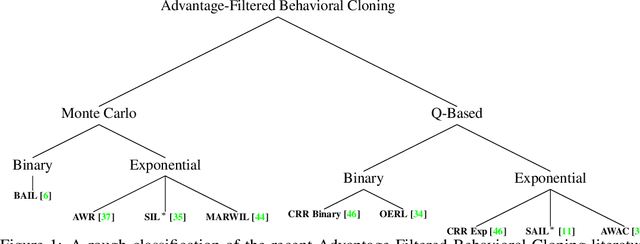
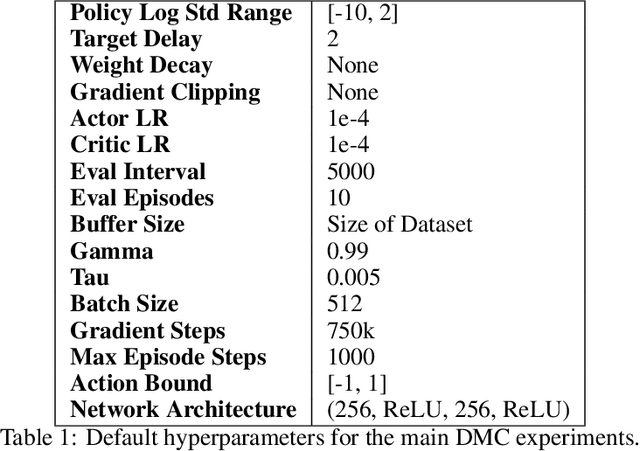
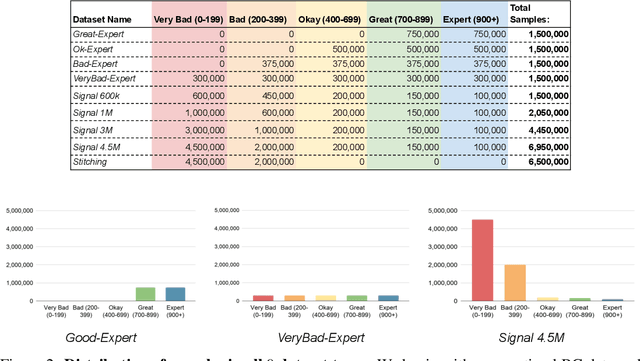

Recent Offline Reinforcement Learning methods have succeeded in learning high-performance policies from fixed datasets of experience. A particularly effective approach learns to first identify and then mimic optimal decision-making strategies. Our work evaluates this method's ability to scale to vast datasets consisting almost entirely of sub-optimal noise. A thorough investigation on a custom benchmark helps identify several key challenges involved in learning from high-noise datasets. We re-purpose prioritized experience sampling to locate expert-level demonstrations among millions of low-performance samples. This modification enables offline agents to learn state-of-the-art policies in benchmark tasks using datasets where expert actions are outnumbered nearly 65:1.