 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAS-Prompt: Large Language Models as Numerical Optimizers for Robot Self-Improvement
Apr 29, 2025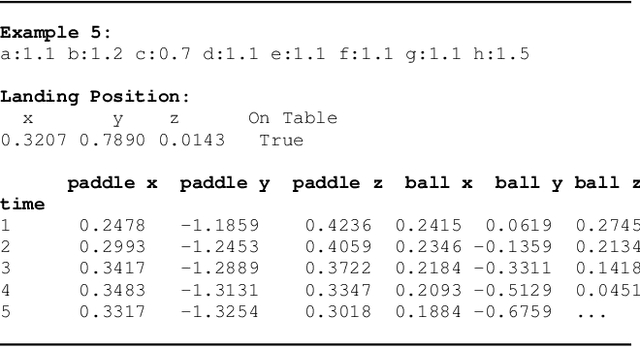

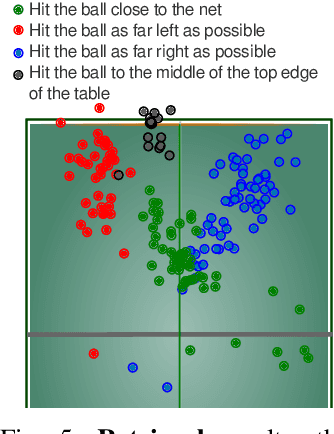

We demonstrate the ability of large language models (LLMs) to perform iterative self-improvement of robot policies. An important insight of this paper is that LLMs have a built-in ability to perform (stochastic) numerical optimization and that this property can be leveraged for explainable robot policy search. Based on this insight, we introduce the SAS Prompt (Summarize, Analyze, Synthesize) -- a single prompt that enables iterative learning and adaptation of robot behavior by combining the LLM's ability to retrieve, reason and optimize over previous robot traces in order to synthesize new, unseen behavior. Our approach can be regarded as an early example of a new family of explainable policy search methods that are entirely implemented within an LLM. We evaluate our approach both in simulation and on a real-robot table tennis task. Project website: sites.google.com/asu.edu/sas-llm/
PlanGEN: A Multi-Agent Framework for Generating Planning and Reasoning Trajectories for Complex Problem Solving
Feb 22, 2025Recent agent frameworks and inference-time algorithms often struggle with complex planning problems due to limitations in verifying generated plans or reasoning and varying complexity of instances within a single task. Many existing methods for these tasks either perform task-level verification without considering constraints or apply inference-time algorithms without adapting to instance-level complexity. To address these limitations, we propose PlanGEN, a model-agnostic and easily scalable agent framework with three key components: constraint, verification, and selection agents. Specifically, our approach proposes constraint-guided iterative verification to enhance performance of inference-time algorithms--Best of N, Tree-of-Thought, and REBASE. In PlanGEN framework, the selection agent optimizes algorithm choice based on instance complexity, ensuring better adaptability to complex planning problems. Experimental results demonstrate significant improvements over the strongest baseline across multiple benchmarks, achieving state-of-the-art results on NATURAL PLAN ($\sim$8%$\uparrow$), OlympiadBench ($\sim$4%$\uparrow$), DocFinQA ($\sim$7%$\uparrow$), and GPQA ($\sim$1%$\uparrow$). Our key finding highlights that constraint-guided iterative verification improves inference-time algorithms, and adaptive selection further boosts performance on complex planning and reasoning problems.
Reverse Thinking Makes LLMs Stronger Reasoners
Nov 29, 2024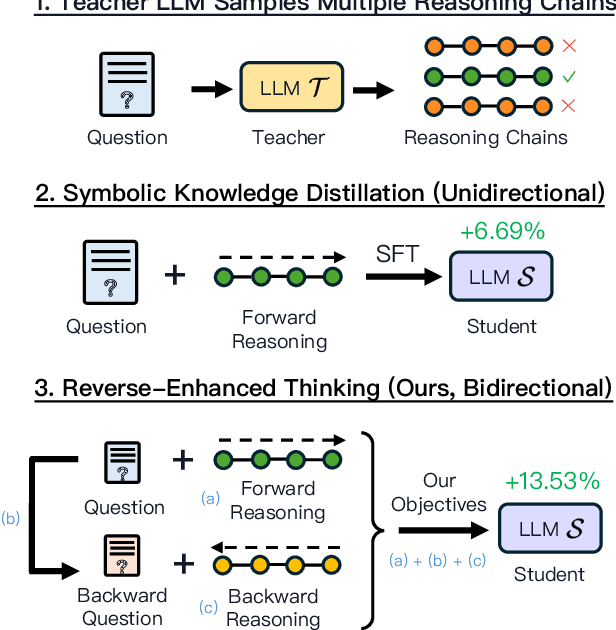
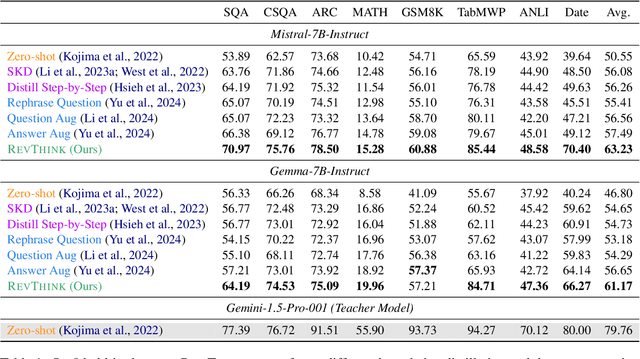
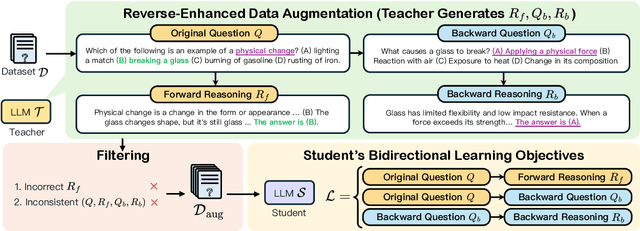
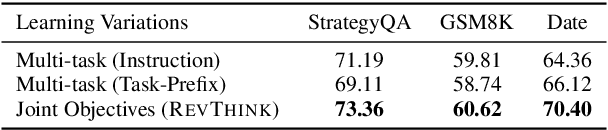
Reverse thinking plays a crucial role in human reasoning. Humans can reason not only from a problem to a solution but also in reverse, i.e., start from the solution and reason towards the problem. This often enhances overall reasoning performance as it enables consistency checks between their forward and backward thinking. To enable Large Language Models (LLMs) to perform reverse thinking, we introduce Reverse-Enhanced Thinking (RevThink), a framework composed of data augmentation and learning objectives. In RevThink, we augment the dataset by collecting structured forward-backward reasoning from a teacher model, consisting of: (1) the original question, (2) forward reasoning, (3) backward question, and (4) backward reasoning. We then employ three objectives to train a smaller student model in a multi-task learning fashion: (a) generate forward reasoning from a question, (b) generate a backward question from a question, and (c) generate backward reasoning from the backward question. Experiments across 12 datasets covering commonsense, math, and logical reasoning show an average 13.53% improvement over the student model's zero-shot performance and a 6.84% improvement over the strongest knowledge distillation baselines. Moreover, our method demonstrates sample efficiency -- using only 10% of the correct forward reasoning from the training data, it outperforms a standard fine-tuning method trained on 10x more forward reasoning. RevThink also exhibits strong generalization to out-of-distribution held-out datasets.
Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting
Jul 11, 2024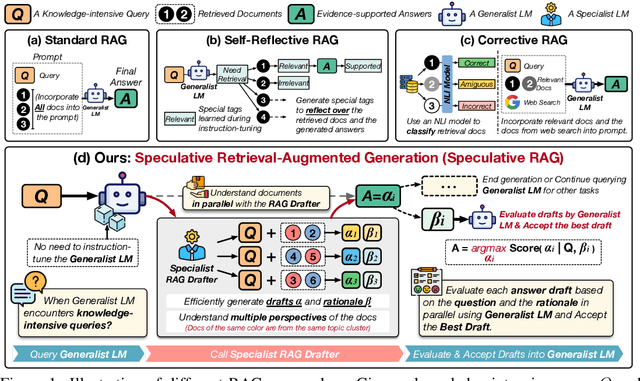
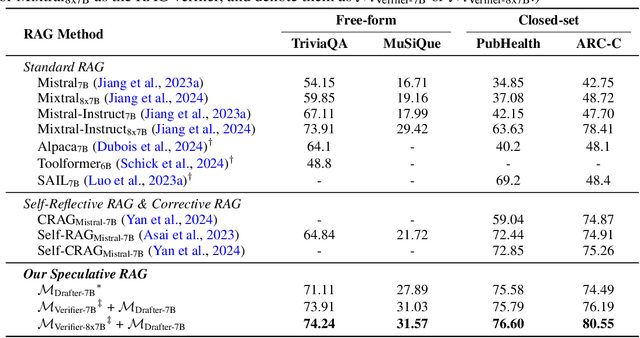
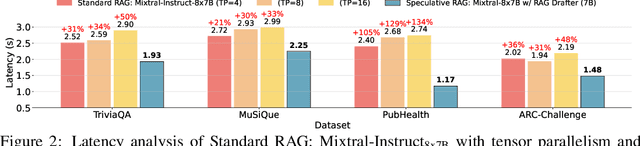
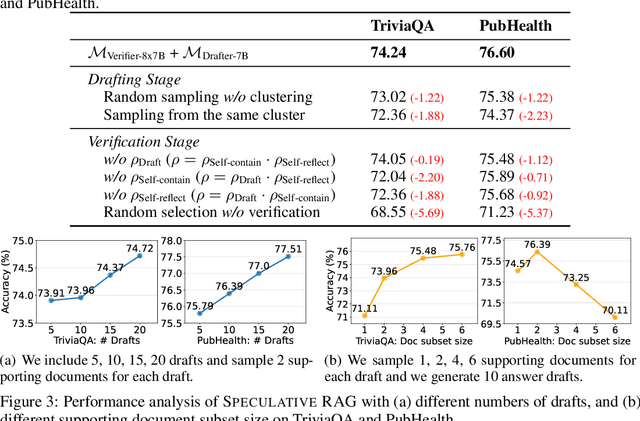
Retrieval augmented generation (RAG) combines the generative abilities of large language models (LLMs) with external knowledge sources to provide more accurate and up-to-date responses. Recent RAG advancements focus on improving retrieval outcomes through iterative LLM refinement or self-critique capabilities acquired through additional instruction tuning of LLMs. In this work, we introduce Speculative RAG - a framework that leverages a larger generalist LM to efficiently verify multiple RAG drafts produced in parallel by a smaller, distilled specialist LM. Each draft is generated from a distinct subset of retrieved documents, offering diverse perspectives on the evidence while reducing input token counts per draft. This approach enhances comprehension of each subset and mitigates potential position bias over long context. Our method accelerates RAG by delegating drafting to the smaller specialist LM, with the larger generalist LM performing a single verification pass over the drafts. Extensive experiments demonstrate that Speculative RAG achieves state-of-the-art performance with reduced latency on TriviaQA, MuSiQue, PubHealth, and ARC-Challenge benchmarks. It notably enhances accuracy by up to 12.97% while reducing latency by 51% compared to conventional RAG systems on PubHealth.
NATURAL PLAN: Benchmarking LLMs on Natural Language Planning
Jun 06, 2024



We introduce NATURAL PLAN, a realistic planning benchmark in natural language containing 3 key tasks: Trip Planning, Meeting Planning, and Calendar Scheduling. We focus our evaluation on the planning capabilities of LLMs with full information on the task, by providing outputs from tools such as Google Flights, Google Maps, and Google Calendar as contexts to the models. This eliminates the need for a tool-use environment for evaluating LLMs on Planning. We observe that NATURAL PLAN is a challenging benchmark for state of the art models. For example, in Trip Planning, GPT-4 and Gemini 1.5 Pro could only achieve 31.1% and 34.8% solve rate respectively. We find that model performance drops drastically as the complexity of the problem increases: all models perform below 5% when there are 10 cities, highlighting a significant gap in planning in natural language for SoTA LLMs. We also conduct extensive ablation studies on NATURAL PLAN to further shed light on the (in)effectiveness of approaches such as self-correction, few-shot generalization, and in-context planning with long-contexts on improving LLM planning.
In-Context Principle Learning from Mistakes
Feb 09, 2024

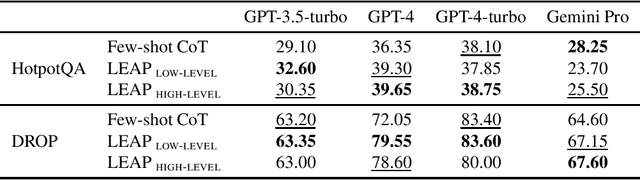

In-context learning (ICL, also known as few-shot prompting) has been the standard method of adapting LLMs to downstream tasks, by learning from a few input-output examples. Nonetheless, all ICL-based approaches only learn from correct input-output pairs. In this paper, we revisit this paradigm, by learning more from the few given input-output examples. We introduce Learning Principles (LEAP): First, we intentionally induce the model to make mistakes on these few examples; then we reflect on these mistakes, and learn explicit task-specific "principles" from them, which help solve similar problems and avoid common mistakes; finally, we prompt the model to answer unseen test questions using the original few-shot examples and these learned general principles. We evaluate LEAP on a wide range of benchmarks, including multi-hop question answering (Hotpot QA), textual QA (DROP), Big-Bench Hard reasoning, and math problems (GSM8K and MATH); in all these benchmarks, LEAP improves the strongest available LLMs such as GPT-3.5-turbo, GPT-4, GPT-4 turbo and Claude-2.1. For example, LEAP improves over the standard few-shot prompting using GPT-4 by 7.5% in DROP, and by 3.3% in HotpotQA. Importantly, LEAP does not require any more input or examples than the standard few-shot prompting settings.
Self-Discover: Large Language Models Self-Compose Reasoning Structures
Feb 06, 2024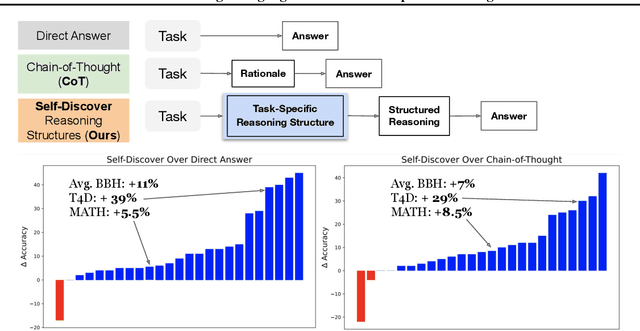



We introduce SELF-DISCOVER, a general framework for LLMs to self-discover the task-intrinsic reasoning structures to tackle complex reasoning problems that are challenging for typical prompting methods. Core to the framework is a self-discovery process where LLMs select multiple atomic reasoning modules such as critical thinking and step-by-step thinking, and compose them into an explicit reasoning structure for LLMs to follow during decoding. SELF-DISCOVER substantially improves GPT-4 and PaLM 2's performance on challenging reasoning benchmarks such as BigBench-Hard, grounded agent reasoning, and MATH, by as much as 32% compared to Chain of Thought (CoT). Furthermore, SELF-DISCOVER outperforms inference-intensive methods such as CoT-Self-Consistency by more than 20%, while requiring 10-40x fewer inference compute. Finally, we show that the self-discovered reasoning structures are universally applicable across model families: from PaLM 2-L to GPT-4, and from GPT-4 to Llama2, and share commonalities with human reasoning patterns.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Beyond ChatBots: ExploreLLM for Structured Thoughts and Personalized Model Responses
Dec 01, 2023
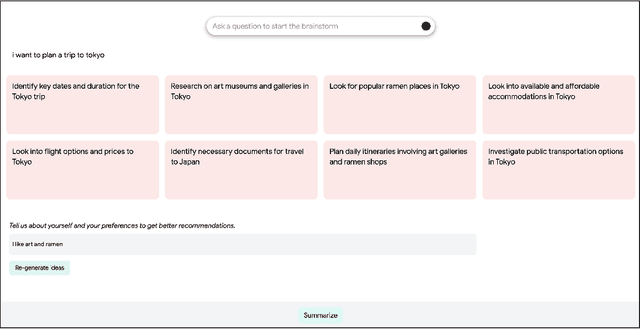


Large language model (LLM) powered chatbots are primarily text-based today, and impose a large interactional cognitive load, especially for exploratory or sensemaking tasks such as planning a trip or learning about a new city. Because the interaction is textual, users have little scaffolding in the way of structure, informational "scent", or ability to specify high-level preferences or goals. We introduce ExploreLLM that allows users to structure thoughts, help explore different options, navigate through the choices and recommendations, and to more easily steer models to generate more personalized responses. We conduct a user study and show that users find it helpful to use ExploreLLM for exploratory or planning tasks, because it provides a useful schema-like structure to the task, and guides users in planning. The study also suggests that users can more easily personalize responses with high-level preferences with ExploreLLM. Together, ExploreLLM points to a future where users interact with LLMs beyond the form of chatbots, and instead designed to support complex user tasks with a tighter integration between natural language and graphical user interfaces.
Instruction-Following Evaluation for Large Language Models
Nov 14, 2023
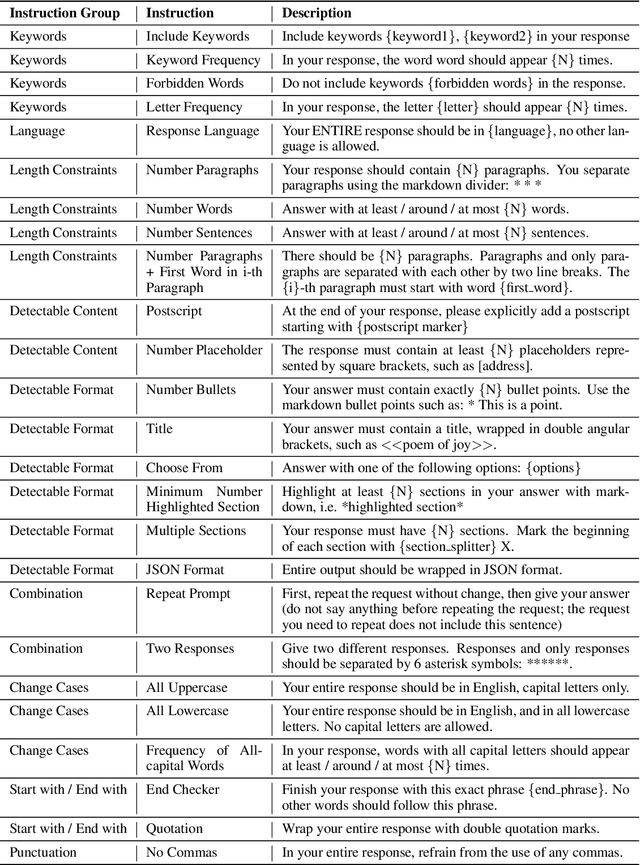
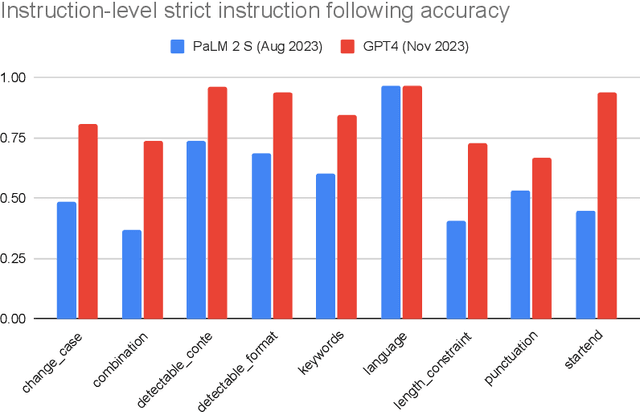

One core capability of Large Language Models (LLMs) is to follow natural language instructions. However, the evaluation of such abilities is not standardized: Human evaluations are expensive, slow, and not objectively reproducible, while LLM-based auto-evaluation is potentially biased or limited by the ability of the evaluator LLM. To overcome these issues, we introduce Instruction-Following Eval (IFEval) for large language models. IFEval is a straightforward and easy-to-reproduce evaluation benchmark. It focuses on a set of "verifiable instructions" such as "write in more than 400 words" and "mention the keyword of AI at least 3 times". We identified 25 types of those verifiable instructions and constructed around 500 prompts, with each prompt containing one or more verifiable instructions. We show evaluation results of two widely available LLMs on the market. Our code and data can be found at https://github.com/google-research/google-research/tree/master/instruction_following_eval