 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarGEN: Targeted Data Generation with Large Language Models
Oct 30, 2023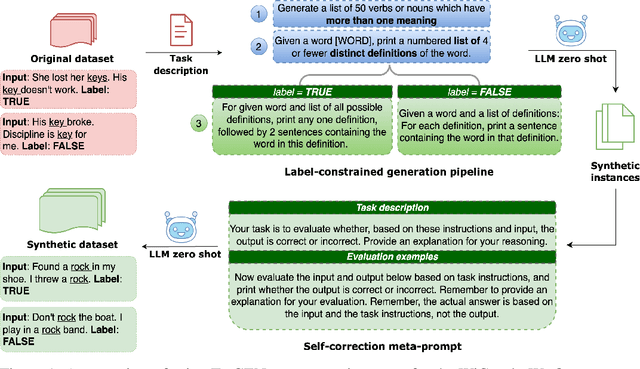
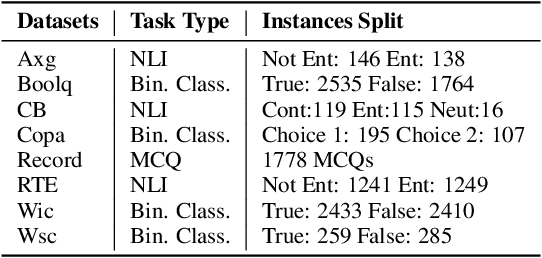
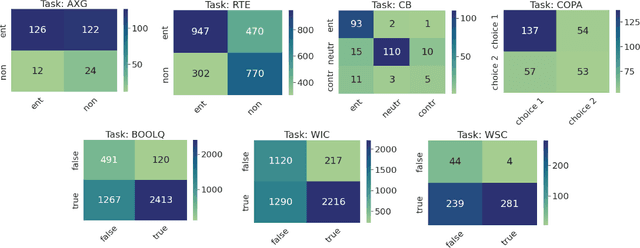
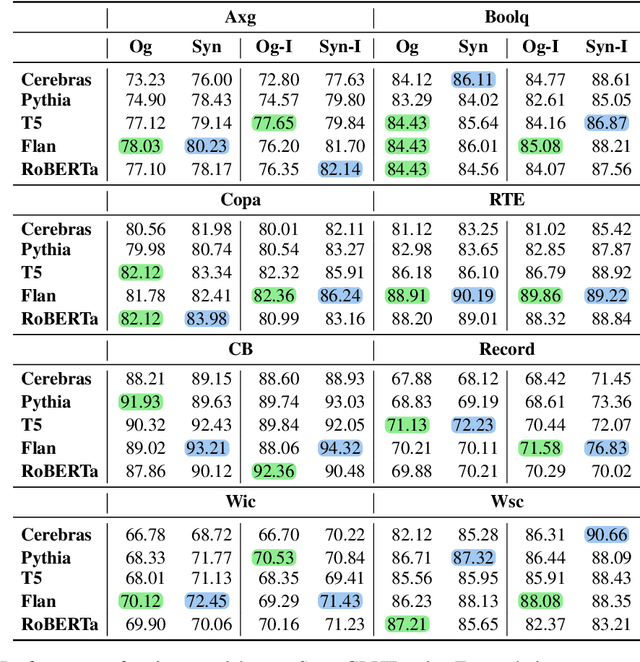
The rapid advancement of large language models (LLMs) has sparked interest in data synthesis techniques, aiming to generate diverse and high-quality synthetic datasets. However, these synthetic datasets often suffer from a lack of diversity and added noise. In this paper, we present TarGEN, a multi-step prompting strategy for generating high-quality synthetic datasets utilizing a LLM. An advantage of TarGEN is its seedless nature; it does not require specific task instances, broadening its applicability beyond task replication. We augment TarGEN with a method known as self-correction empowering LLMs to rectify inaccurately labeled instances during dataset creation, ensuring reliable labels. To assess our technique's effectiveness, we emulate 8 tasks from the SuperGLUE benchmark and finetune various language models, including encoder-only, encoder-decoder, and decoder-only models on both synthetic and original training sets. Evaluation on the original test set reveals that models trained on datasets generated by TarGEN perform approximately 1-2% points better than those trained on original datasets (82.84% via syn. vs. 81.12% on og. using Flan-T5). When incorporating instruction tuning, the performance increases to 84.54% on synthetic data vs. 81.49% on original data by Flan-T5. A comprehensive analysis of the synthetic dataset compared to the original dataset reveals that the synthetic dataset demonstrates similar or higher levels of dataset complexity and diversity. Furthermore, the synthetic dataset displays a bias level that aligns closely with the original dataset. Finally, when pre-finetuned on our synthetic SuperGLUE dataset, T5-3B yields impressive results on the OpenLLM leaderboard, surpassing the model trained on the Self-Instruct dataset by 4.14% points. We hope that TarGEN can be helpful for quality data generation and reducing the human efforts to create complex benchmarks.
Rule-Based Error Detection and Correction to Operationalize Movement Trajectory Classification
Aug 28, 2023



Classification of movement trajectories has many applications in transportation. Supervised neural models represent the current state-of-the-art. Recent security applications require this task to be rapidly employed in environments that may differ from the data used to train such models for which there is little training data. We provide a neuro-symbolic rule-based framework to conduct error correction and detection of these models to support eventual deployment in security applications. We provide a suite of experiments on several recent and state-of-the-art models and show an accuracy improvement of 1.7% over the SOTA model in the case where all classes are present in training and when 40% of classes are omitted from training, we obtain a 5.2% improvement (zero-shot) and 23.9% (few-shot) improvement over the SOTA model without resorting to retraining of the base model.
InstructABSA: Instruction Learning for Aspect Based Sentiment Analysis
Feb 21, 2023In this paper, we present InstructABSA, Aspect-Based Sentiment Analysis (ABSA) using instruction learning paradigm for all ABSA subtasks: Aspect Term Extraction (ATE), Aspect Term Sentiment Classification (ATSC), and Joint Task modeling. Our method introduces positive, negative, and neutral examples to each training sample, and instruction tunes the model (Tk-Instruct Base) for each ABSA subtask, yielding significant performance improvements. Experimental results on the Sem Eval 2014 dataset demonstrate that InstructABSA outperforms the previous state-of-the-art (SOTA) approaches on all three ABSA subtasks (ATE, ATSC, and Joint Task) by a significant margin, outperforming 7x larger models. In particular, InstructABSA surpasses the SOTA on the restaurant ATE subtask by 7.31% points and on the Laptop Joint Task by 8.63% points. Our results also suggest a strong generalization ability to unseen tasks across all three subtasks.
"John is 50 years old, can his son be 65?" Evaluating NLP Models' Understanding of Feasibility
Oct 14, 2022
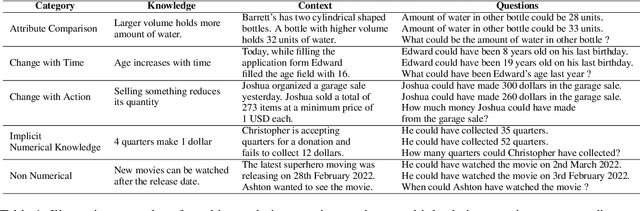
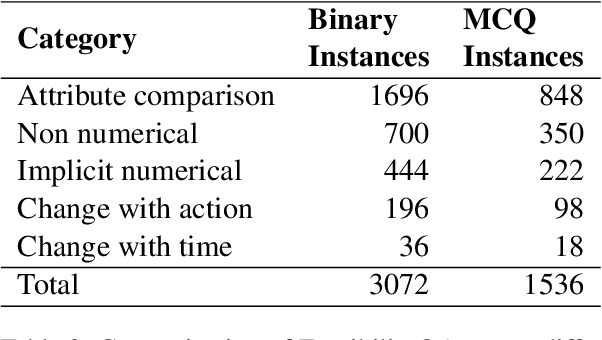

In current NLP research, large-scale language models and their abilities are widely being discussed. Some recent works have also found notable failures of these models. Often these failure examples involve complex reasoning abilities. This work focuses on a simple commonsense ability, reasoning about when an action (or its effect) is feasible. We introduce FeasibilityQA, a question-answering dataset involving binary classification (BCQ) and multi-choice multi-correct questions (MCQ) that test understanding of feasibility. We show that even state-of-the-art models such as GPT-3 struggle to answer the feasibility questions correctly. Specifically, on (MCQ, BCQ) questions, GPT-3 achieves accuracy of just (19%, 62%) and (25%, 64%) in zero-shot and few-shot settings, respectively. We also evaluate models by providing relevant knowledge statements required to answer the question and find that the additional knowledge leads to a 7% gain in performance, but the overall performance still remains low. These results make one wonder how much commonsense knowledge about action feasibility is encoded in GPT-3 and how well the model can reason about it.