 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Tag Prediction based on Question Tagging Behavior Analysis of CommunityQA Platform Users
Jul 04, 2023
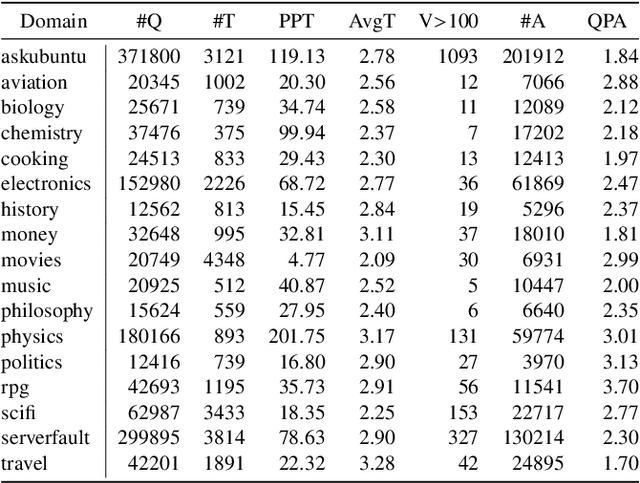
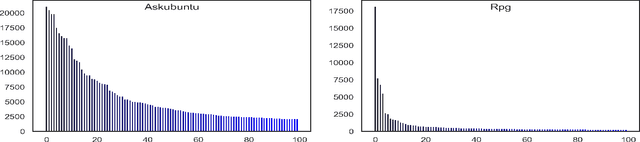
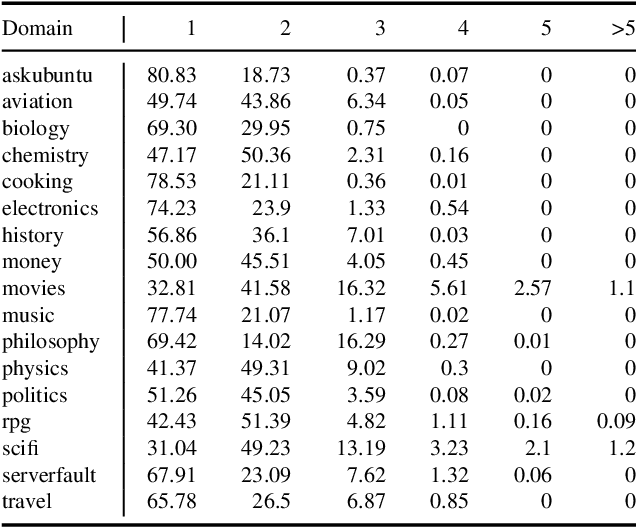
In community question-answering platforms, tags play essential roles in effective information organization and retrieval, better question routing, faster response to questions, and assessment of topic popularity. Hence, automatic assistance for predicting and suggesting tags for posts is of high utility to users of such platforms. To develop better tag prediction across diverse communities and domains, we performed a thorough analysis of users' tagging behavior in 17 StackExchange communities. We found various common inherent properties of this behavior in those diverse domains. We used the findings to develop a flexible neural tag prediction architecture, which predicts both popular tags and more granular tags for each question. Our extensive experiments and obtained performance show the effectiveness of our model
EDM3: Event Detection as Multi-task Text Generation
May 25, 2023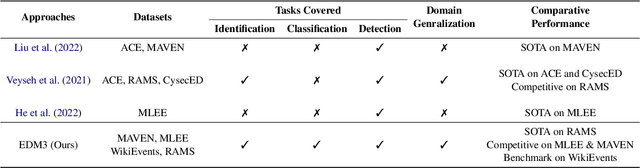


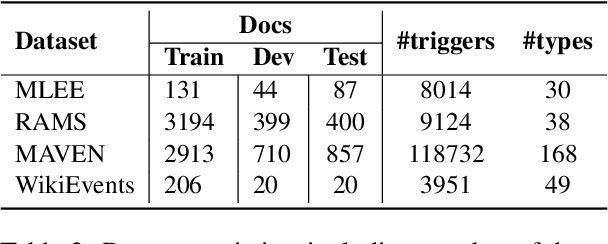
Event detection refers to identifying event occurrences in a text and comprises of two subtasks; event identification and classification. We present EDM3, a novel approach for Event Detection that formulates three generative tasks: identification, classification, and combined detection. We show that EDM3 helps to learn transferable knowledge that can be leveraged to perform Event Detection and its subtasks concurrently, mitigating the error propagation inherent in pipelined approaches. Unlike previous dataset- or domain-specific approaches, EDM3 utilizes the existing knowledge of language models, allowing it to be trained over any classification schema. We evaluate EDM3 on multiple event detection datasets: RAMS, WikiEvents, MAVEN, and MLEE, showing that EDM3 outperforms 1) single-task performance by 8.4% on average and 2) multi-task performance without instructional prompts by 2.4% on average. We obtain SOTA results on RAMS (71.3% vs. 65.1% F-1) and competitive performance on other datasets. We analyze our approach to demonstrate its efficacy in low-resource and multi-sentence settings. We also show the effectiveness of this approach on non-standard event configurations such as multi-word and multi-class event triggers. Overall, our results show that EDM3 is a promising approach for Event Detection that has the potential for real-world applications.
Prompt-Based Learning for Thread Structure Prediction in Cybersecurity Forums
Mar 05, 2023



With recent trends indicating cyber crimes increasing in both frequency and cost, it is imperative to develop new methods that leverage data-rich hacker forums to assist in combating ever evolving cyber threats. Defining interactions within these forums is critical as it facilitates identifying highly skilled users, which can improve prediction of novel threats and future cyber attacks. We propose a method called Next Paragraph Prediction with Instructional Prompting (NPP-IP) to predict thread structures while grounded on the context around posts. This is the first time to apply an instructional prompting approach to the cybersecurity domain. We evaluate our NPP-IP with the Reddit dataset and Hacker Forums dataset that has posts and thread structures of real hacker forums' threads, and compare our method's performance with existing methods. The experimental evaluation shows that our proposed method can predict the thread structure significantly better than existing methods allowing for better social network prediction based on forum interactions.
Exploring the Limits of Transfer Learning with Unified Model in the Cybersecurity Domain
Feb 20, 2023



With the increase in cybersecurity vulnerabilities of software systems, the ways to exploit them are also increasing. Besides these, malware threats, irregular network interactions, and discussions about exploits in public forums are also on the rise. To identify these threats faster, to detect potentially relevant entities from any texts, and to be aware of software vulnerabilities, automated approaches are necessary. Application of natural language processing (NLP) techniques in the Cybersecurity domain can help in achieving this. However, there are challenges such as the diverse nature of texts involved in the cybersecurity domain, the unavailability of large-scale publicly available datasets, and the significant cost of hiring subject matter experts for annotations. One of the solutions is building multi-task models that can be trained jointly with limited data. In this work, we introduce a generative multi-task model, Unified Text-to-Text Cybersecurity (UTS), trained on malware reports, phishing site URLs, programming code constructs, social media data, blogs, news articles, and public forum posts. We show UTS improves the performance of some cybersecurity datasets. We also show that with a few examples, UTS can be adapted to novel unseen tasks and the nature of data
"John is 50 years old, can his son be 65?" Evaluating NLP Models' Understanding of Feasibility
Oct 14, 2022
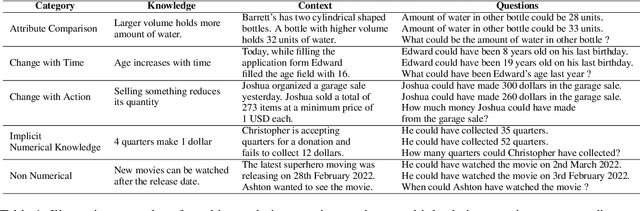
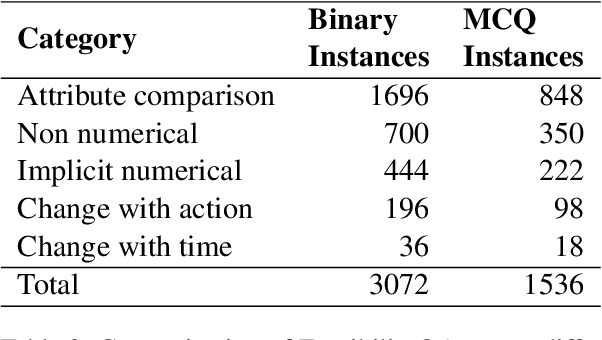

In current NLP research, large-scale language models and their abilities are widely being discussed. Some recent works have also found notable failures of these models. Often these failure examples involve complex reasoning abilities. This work focuses on a simple commonsense ability, reasoning about when an action (or its effect) is feasible. We introduce FeasibilityQA, a question-answering dataset involving binary classification (BCQ) and multi-choice multi-correct questions (MCQ) that test understanding of feasibility. We show that even state-of-the-art models such as GPT-3 struggle to answer the feasibility questions correctly. Specifically, on (MCQ, BCQ) questions, GPT-3 achieves accuracy of just (19%, 62%) and (25%, 64%) in zero-shot and few-shot settings, respectively. We also evaluate models by providing relevant knowledge statements required to answer the question and find that the additional knowledge leads to a 7% gain in performance, but the overall performance still remains low. These results make one wonder how much commonsense knowledge about action feasibility is encoded in GPT-3 and how well the model can reason about it.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

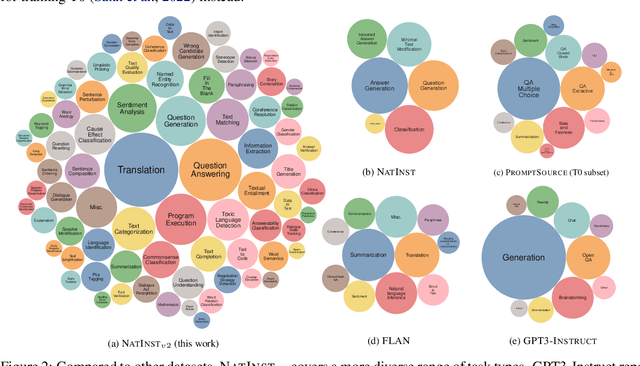
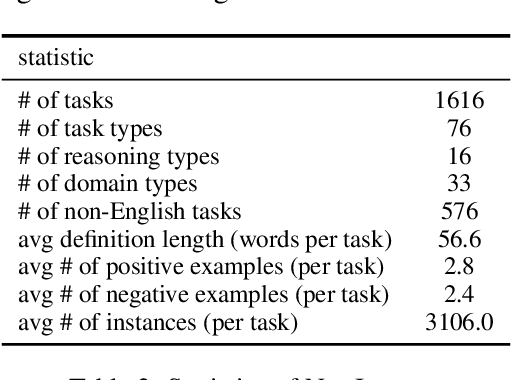
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
Investigating Numeracy Learning Ability of a Text-to-Text Transfer Model
Sep 10, 2021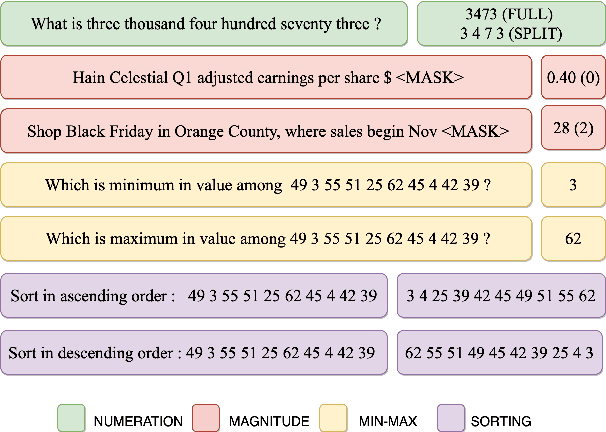
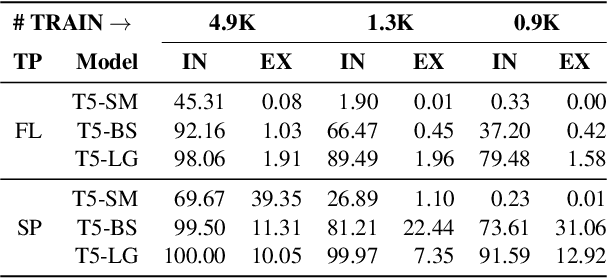
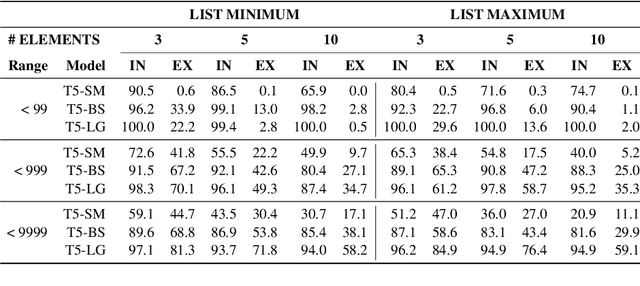

The transformer-based pre-trained language models have been tremendously successful in most of the conventional NLP tasks. But they often struggle in those tasks where numerical understanding is required. Some possible reasons can be the tokenizers and pre-training objectives which are not specifically designed to learn and preserve numeracy. Here we investigate the ability of text-to-text transfer learning model (T5), which has outperformed its predecessors in the conventional NLP tasks, to learn numeracy. We consider four numeracy tasks: numeration, magnitude order prediction, finding minimum and maximum in a series, and sorting. We find that, although T5 models perform reasonably well in the interpolation setting, they struggle considerably in the extrapolation setting across all four tasks.
Constructing Flow Graphs from Procedural Cybersecurity Texts
May 29, 2021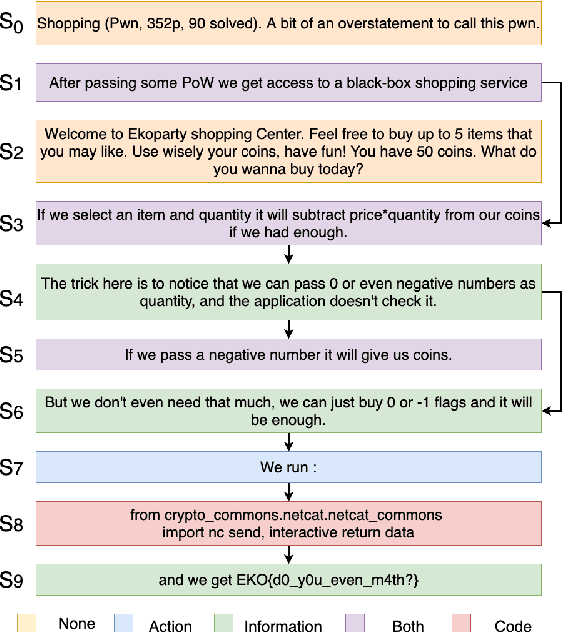
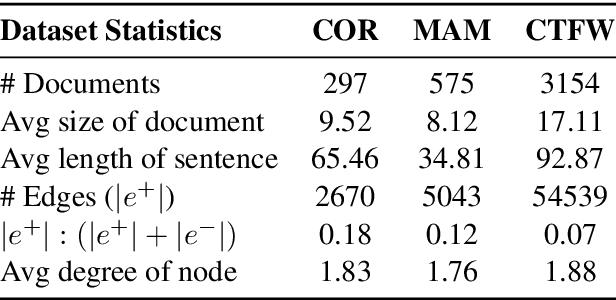
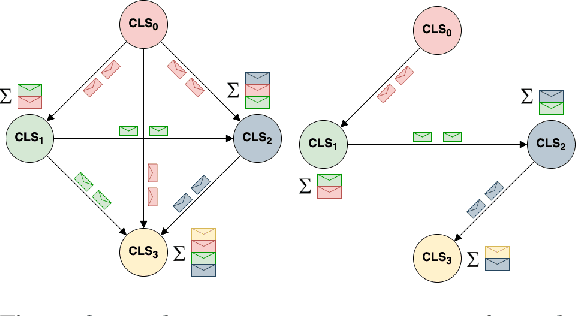
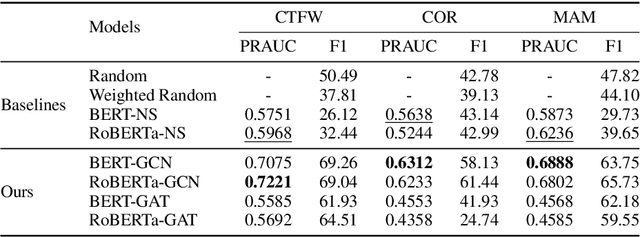
Following procedural texts written in natural languages is challenging. We must read the whole text to identify the relevant information or identify the instruction flows to complete a task, which is prone to failures. If such texts are structured, we can readily visualize instruction-flows, reason or infer a particular step, or even build automated systems to help novice agents achieve a goal. However, this structure recovery task is a challenge because of such texts' diverse nature. This paper proposes to identify relevant information from such texts and generate information flows between sentences. We built a large annotated procedural text dataset (CTFW) in the cybersecurity domain (3154 documents). This dataset contains valuable instructions regarding software vulnerability analysis experiences. We performed extensive experiments on CTFW with our LM-GNN model variants in multiple settings. To show the generalizability of both this task and our method, we also experimented with procedural texts from two other domains (Maintenance Manual and Cooking), which are substantially different from cybersecurity. Our experiments show that Graph Convolution Network with BERT sentence embeddings outperforms BERT in all three domains
Variable Name Recovery in Decompiled Binary Code using Constrained Masked Language Modeling
Mar 23, 2021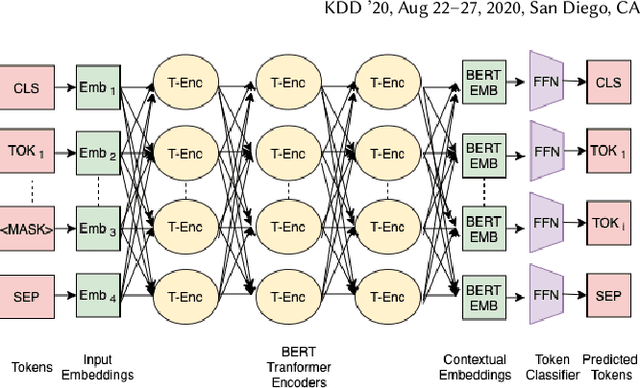
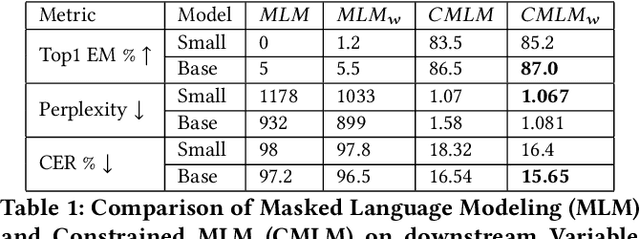
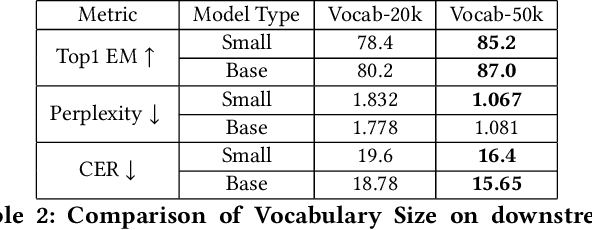
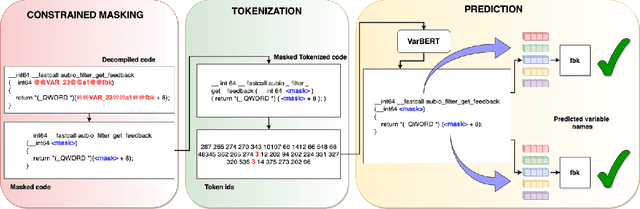
Decompilation is the procedure of transforming binary programs into a high-level representation, such as source code, for human analysts to examine. While modern decompilers can reconstruct and recover much information that is discarded during compilation, inferring variable names is still extremely difficult. Inspired by recent advances in natural language processing, we propose a novel solution to infer variable names in decompiled code based on Masked Language Modeling, Byte-Pair Encoding, and neural architectures such as Transformers and BERT. Our solution takes \textit{raw} decompiler output, the less semantically meaningful code, as input, and enriches it using our proposed \textit{finetuning} technique, Constrained Masked Language Modeling. Using Constrained Masked Language Modeling introduces the challenge of predicting the number of masked tokens for the original variable name. We address this \textit{count of token prediction} challenge with our post-processing algorithm. Compared to the state-of-the-art approaches, our trained VarBERT model is simpler and of much better performance. We evaluated our model on an existing large-scale data set with 164,632 binaries and showed that it can predict variable names identical to the ones present in the original source code up to 84.15\% of the time.
Natural Language QA Approaches using Reasoning with External Knowledge
Mar 06, 2020

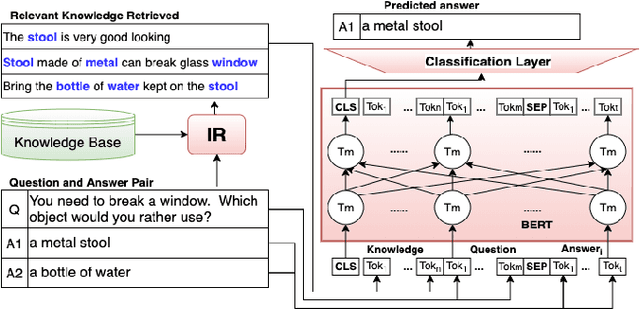
Question answering (QA) in natural language (NL) has been an important aspect of AI from its early days. Winograd's ``councilmen'' example in his 1972 paper and McCarthy's Mr. Hug example of 1976 highlights the role of external knowledge in NL understanding. While Machine Learning has been the go-to approach in NL processing as well as NL question answering (NLQA) for the last 30 years, recently there has been an increasingly emphasized thread on NLQA where external knowledge plays an important role. The challenges inspired by Winograd's councilmen example, and recent developments such as the Rebooting AI book, various NLQA datasets, research on knowledge acquisition in the NLQA context, and their use in various NLQA models have brought the issue of NLQA using ``reasoning'' with external knowledge to the forefront. In this paper, we present a survey of the recent work on them. We believe our survey will help establish a bridge between multiple fields of AI, especially between (a) the traditional fields of knowledge representation and reasoning and (b) the field of NL understanding and NLQA.