 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Based Learning for Thread Structure Prediction in Cybersecurity Forums
Mar 05, 2023



With recent trends indicating cyber crimes increasing in both frequency and cost, it is imperative to develop new methods that leverage data-rich hacker forums to assist in combating ever evolving cyber threats. Defining interactions within these forums is critical as it facilitates identifying highly skilled users, which can improve prediction of novel threats and future cyber attacks. We propose a method called Next Paragraph Prediction with Instructional Prompting (NPP-IP) to predict thread structures while grounded on the context around posts. This is the first time to apply an instructional prompting approach to the cybersecurity domain. We evaluate our NPP-IP with the Reddit dataset and Hacker Forums dataset that has posts and thread structures of real hacker forums' threads, and compare our method's performance with existing methods. The experimental evaluation shows that our proposed method can predict the thread structure significantly better than existing methods allowing for better social network prediction based on forum interactions.
Exploring the Limits of Transfer Learning with Unified Model in the Cybersecurity Domain
Feb 20, 2023



With the increase in cybersecurity vulnerabilities of software systems, the ways to exploit them are also increasing. Besides these, malware threats, irregular network interactions, and discussions about exploits in public forums are also on the rise. To identify these threats faster, to detect potentially relevant entities from any texts, and to be aware of software vulnerabilities, automated approaches are necessary. Application of natural language processing (NLP) techniques in the Cybersecurity domain can help in achieving this. However, there are challenges such as the diverse nature of texts involved in the cybersecurity domain, the unavailability of large-scale publicly available datasets, and the significant cost of hiring subject matter experts for annotations. One of the solutions is building multi-task models that can be trained jointly with limited data. In this work, we introduce a generative multi-task model, Unified Text-to-Text Cybersecurity (UTS), trained on malware reports, phishing site URLs, programming code constructs, social media data, blogs, news articles, and public forum posts. We show UTS improves the performance of some cybersecurity datasets. We also show that with a few examples, UTS can be adapted to novel unseen tasks and the nature of data
Constructing Flow Graphs from Procedural Cybersecurity Texts
May 29, 2021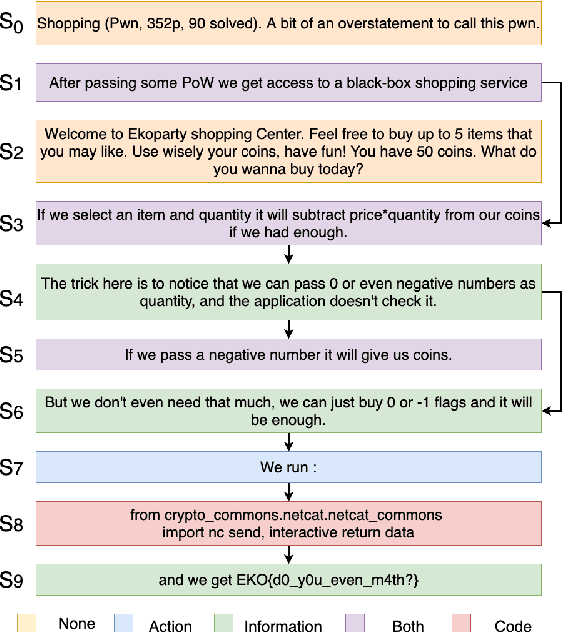
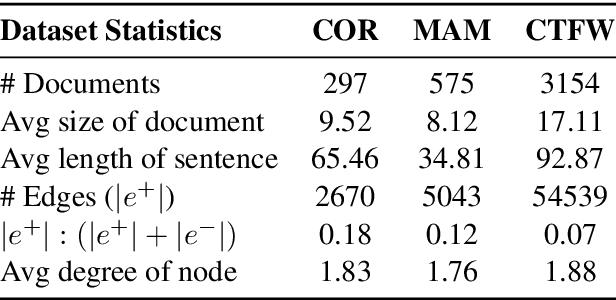
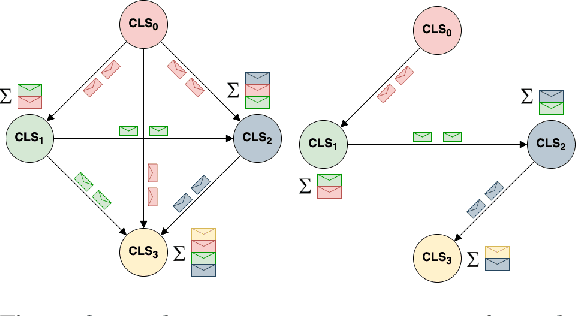
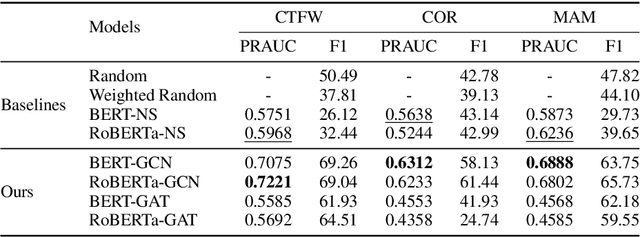
Following procedural texts written in natural languages is challenging. We must read the whole text to identify the relevant information or identify the instruction flows to complete a task, which is prone to failures. If such texts are structured, we can readily visualize instruction-flows, reason or infer a particular step, or even build automated systems to help novice agents achieve a goal. However, this structure recovery task is a challenge because of such texts' diverse nature. This paper proposes to identify relevant information from such texts and generate information flows between sentences. We built a large annotated procedural text dataset (CTFW) in the cybersecurity domain (3154 documents). This dataset contains valuable instructions regarding software vulnerability analysis experiences. We performed extensive experiments on CTFW with our LM-GNN model variants in multiple settings. To show the generalizability of both this task and our method, we also experimented with procedural texts from two other domains (Maintenance Manual and Cooking), which are substantially different from cybersecurity. Our experiments show that Graph Convolution Network with BERT sentence embeddings outperforms BERT in all three domains