 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable Name Recovery in Decompiled Binary Code using Constrained Masked Language Modeling
Paper and Code
Mar 23, 2021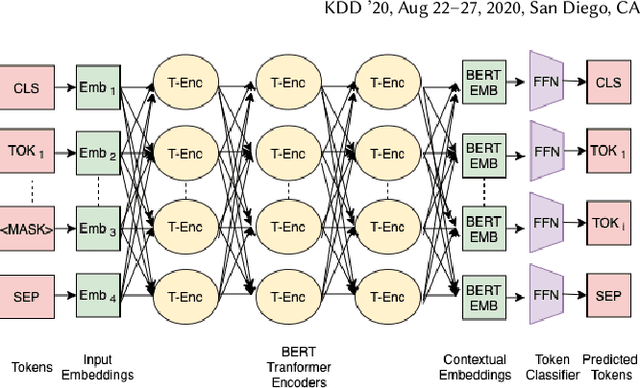
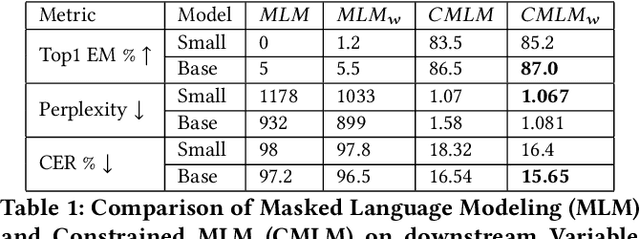
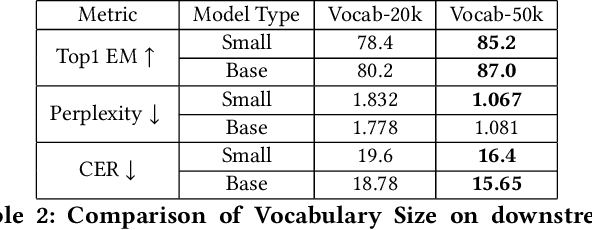
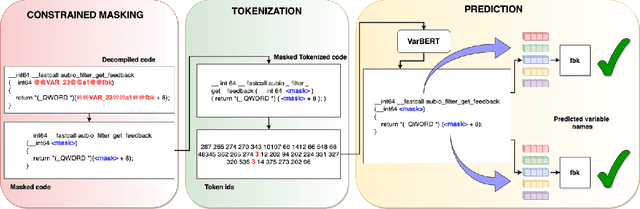
Decompilation is the procedure of transforming binary programs into a high-level representation, such as source code, for human analysts to examine. While modern decompilers can reconstruct and recover much information that is discarded during compilation, inferring variable names is still extremely difficult. Inspired by recent advances in natural language processing, we propose a novel solution to infer variable names in decompiled code based on Masked Language Modeling, Byte-Pair Encoding, and neural architectures such as Transformers and BERT. Our solution takes \textit{raw} decompiler output, the less semantically meaningful code, as input, and enriches it using our proposed \textit{finetuning} technique, Constrained Masked Language Modeling. Using Constrained Masked Language Modeling introduces the challenge of predicting the number of masked tokens for the original variable name. We address this \textit{count of token prediction} challenge with our post-processing algorithm. Compared to the state-of-the-art approaches, our trained VarBERT model is simpler and of much better performance. We evaluated our model on an existing large-scale data set with 164,632 binaries and showed that it can predict variable names identical to the ones present in the original source code up to 84.15\% of the time.