 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Style-Personalized Text Generation: Challenges and Directions
Aug 08, 2025While prior research has built tools and benchmarks towards style personalized text generation, there has been limited exploration of evaluation in low-resource author style personalized text generation space. Through this work, we question the effectiveness of the widely adopted evaluation metrics like BLEU and ROUGE, and explore other evaluation paradigms such as style embeddings and LLM-as-judge to holistically evaluate the style personalized text generation task. We evaluate these metrics and their ensembles using our style discrimination benchmark, that spans eight writing tasks, and evaluates across three settings, domain discrimination, authorship attribution, and LLM personalized vs non-personalized discrimination. We provide conclusive evidence to adopt ensemble of diverse evaluation metrics to effectively evaluate style personalized text generation.
Neon: News Entity-Interaction Extraction for Enhanced Question Answering
Nov 20, 2024



Capturing fresh information in near real-time and using it to augment existing large language models (LLMs) is essential to generate up-to-date, grounded, and reliable output. This problem becomes particularly challenging when LLMs are used for informational tasks in rapidly evolving fields, such as Web search related to recent or unfolding events involving entities, where generating temporally relevant responses requires access to up-to-the-hour news sources. However, the information modeled by the parametric memory of LLMs is often outdated, and Web results from prototypical retrieval systems may fail to capture the latest relevant information and struggle to handle conflicting reports in evolving news. To address this challenge, we present the NEON framework, designed to extract emerging entity interactions -- such as events or activities -- as described in news articles. NEON constructs an entity-centric timestamped knowledge graph that captures such interactions, thereby facilitating enhanced QA capabilities related to news events. Our framework innovates by integrating open Information Extraction (openIE) style tuples into LLMs to enable in-context retrieval-augmented generation. This integration demonstrates substantial improvements in QA performance when tackling temporal, entity-centric search queries. Through NEON, LLMs can deliver more accurate, reliable, and up-to-date responses.
ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models
Apr 11, 2024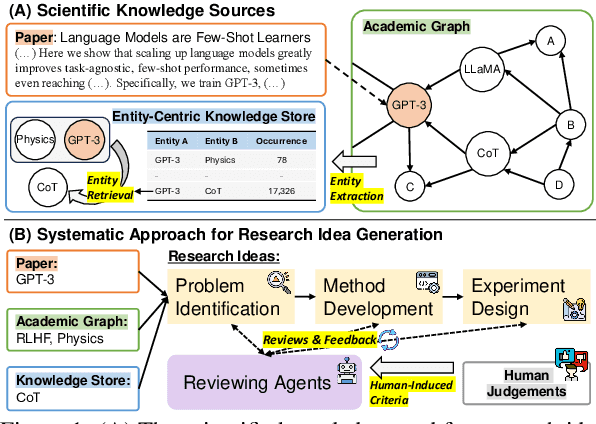


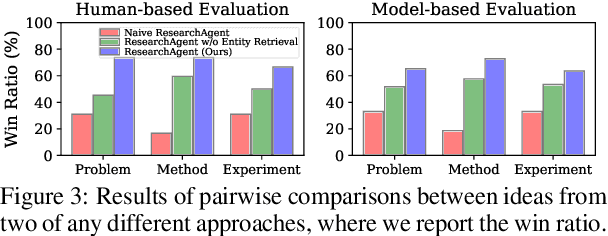
Scientific Research, vital for improving human life, is hindered by its inherent complexity, slow pace, and the need for specialized experts. To enhance its productivity, we propose a ResearchAgent, a large language model-powered research idea writing agent, which automatically generates problems, methods, and experiment designs while iteratively refining them based on scientific literature. Specifically, starting with a core paper as the primary focus to generate ideas, our ResearchAgent is augmented not only with relevant publications through connecting information over an academic graph but also entities retrieved from an entity-centric knowledge store based on their underlying concepts, mined and shared across numerous papers. In addition, mirroring the human approach to iteratively improving ideas with peer discussions, we leverage multiple ReviewingAgents that provide reviews and feedback iteratively. Further, they are instantiated with human preference-aligned large language models whose criteria for evaluation are derived from actual human judgments. We experimentally validate our ResearchAgent on scientific publications across multiple disciplines, showcasing its effectiveness in generating novel, clear, and valid research ideas based on human and model-based evaluation results.
Knowledge-Centric Templatic Views of Documents
Jan 13, 2024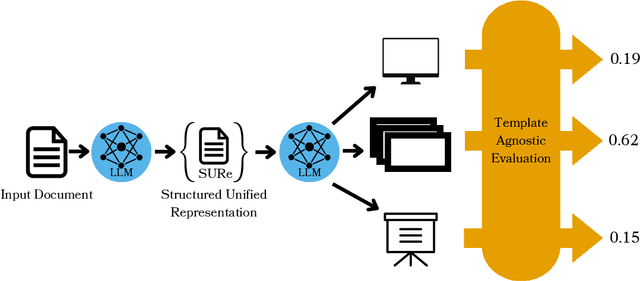

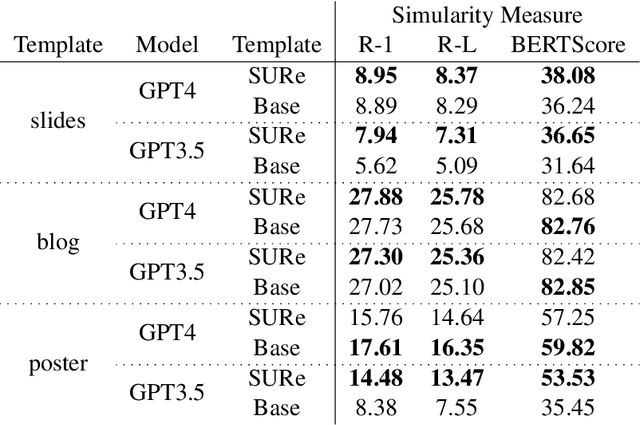
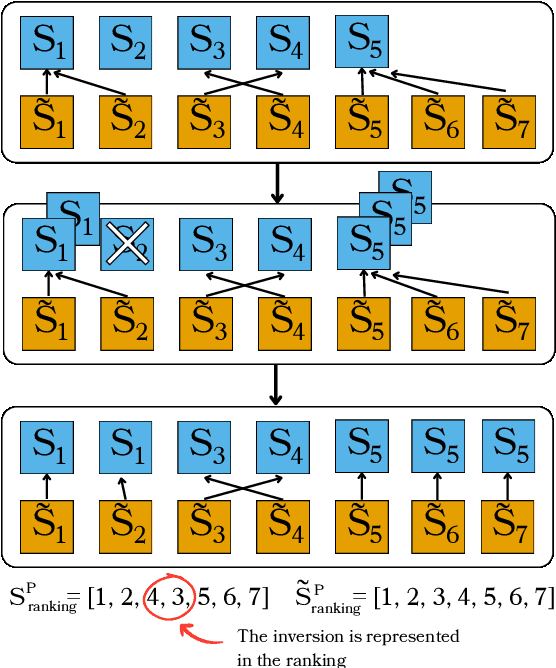
Authors seeking to communicate with broader audiences often compose their ideas about the same underlying knowledge in different documents and formats -- for example, as slide decks, newsletters, reports, brochures, etc. Prior work in document generation has generally considered the creation of each separate format to be different a task, developing independent methods for generation and evaluation. This approach is suboptimal for the advancement of AI-supported content authoring from both research and application perspectives because it leads to fragmented learning processes, redundancy in models and methods, and disjointed evaluation. Thus, in our work, we consider each of these documents to be templatic views of the same underlying knowledge, and we aim to unify the generation and evaluation of these templatic views of documents. We begin by introducing an LLM-powered method to extract the most important information from an input document and represent this information in a structured format. We show that this unified representation can be used to generate multiple templatic views with no supervision and with very little guidance, improving over strong baselines. We additionally introduce a unified evaluation method that is template agnostic, and can be adapted to building document generators for heterogeneous downstream applications. Finally, we conduct a human evaluation, which shows that humans prefer 82% of the downstream documents generated with our method. Furthermore, the newly proposed evaluation metric correlates more highly with human judgement than prior metrics, while providing a unified evaluation method.
Knowledge-Augmented Large Language Models for Personalized Contextual Query Suggestion
Nov 10, 2023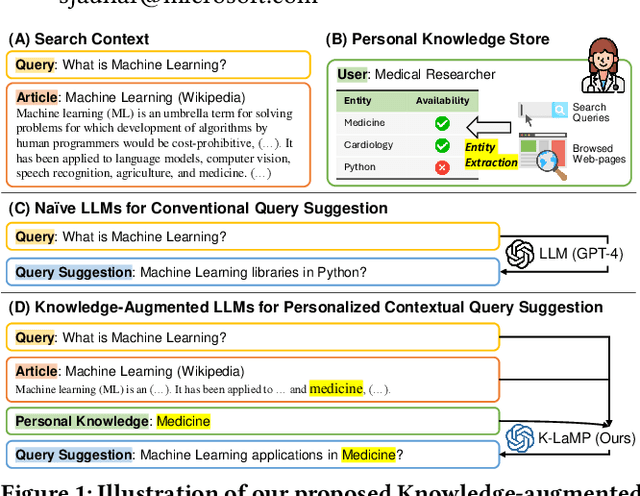


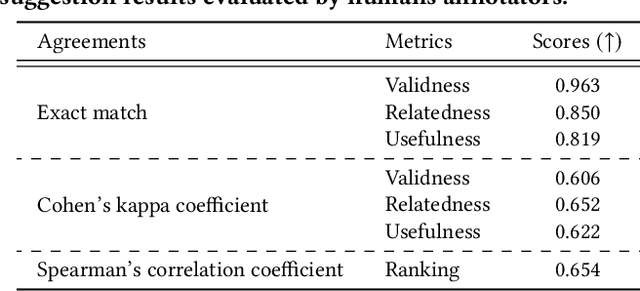
Large Language Models (LLMs) excel at tackling various natural language tasks. However, due to the significant costs involved in re-training or fine-tuning them, they remain largely static and difficult to personalize. Nevertheless, a variety of applications could benefit from generations that are tailored to users' preferences, goals, and knowledge. Among them is web search, where knowing what a user is trying to accomplish, what they care about, and what they know can lead to improved search experiences. In this work, we propose a novel and general approach that augments an LLM with relevant context from users' interaction histories with a search engine in order to personalize its outputs. Specifically, we construct an entity-centric knowledge store for each user based on their search and browsing activities on the web, which is then leveraged to provide contextually relevant LLM prompt augmentations. This knowledge store is light-weight, since it only produces user-specific aggregate projections of interests and knowledge onto public knowledge graphs, and leverages existing search log infrastructure, thereby mitigating the privacy, compliance, and scalability concerns associated with building deep user profiles for personalization. We then validate our approach on the task of contextual query suggestion, which requires understanding not only the user's current search context but also what they historically know and care about. Through a number of experiments based on human evaluation, we show that our approach is significantly better than several other LLM-powered baselines, generating query suggestions that are contextually more relevant, personalized, and useful.
Modeling Tag Prediction based on Question Tagging Behavior Analysis of CommunityQA Platform Users
Jul 04, 2023
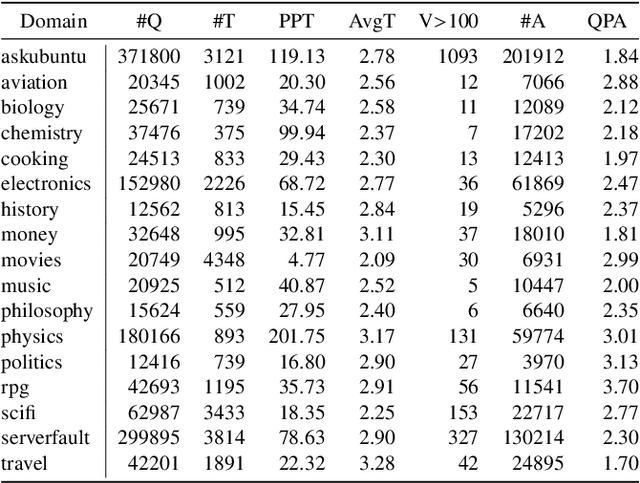
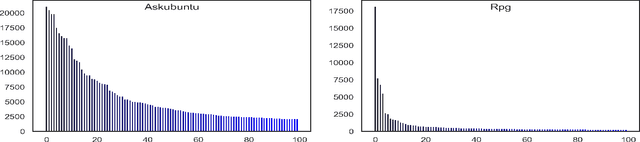
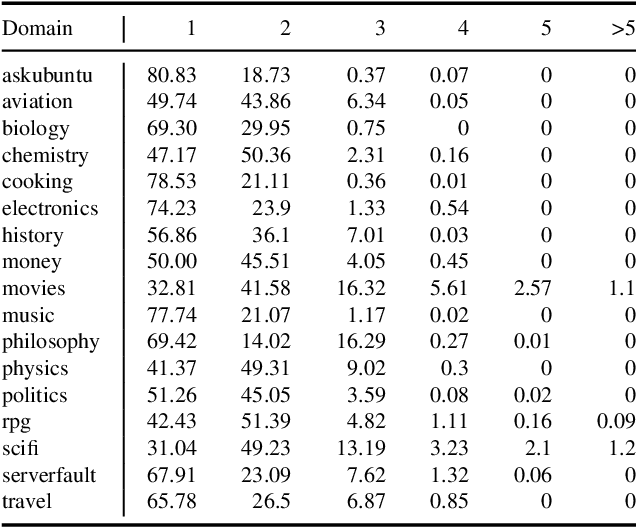
In community question-answering platforms, tags play essential roles in effective information organization and retrieval, better question routing, faster response to questions, and assessment of topic popularity. Hence, automatic assistance for predicting and suggesting tags for posts is of high utility to users of such platforms. To develop better tag prediction across diverse communities and domains, we performed a thorough analysis of users' tagging behavior in 17 StackExchange communities. We found various common inherent properties of this behavior in those diverse domains. We used the findings to develop a flexible neural tag prediction architecture, which predicts both popular tags and more granular tags for each question. Our extensive experiments and obtained performance show the effectiveness of our model