 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Science Journalists: Supporting Early-stage Researchers in Communicating Their Science to the Public
Jan 09, 2026The scientific community needs tools that help early-stage researchers effectively communicate their findings and innovations to the public. Although existing general-purpose Large Language Models (LLMs) can assist in this endeavor, they are not optimally aligned for it. To address this, we propose a framework for training LLMs to emulate the role of a science journalist that can be used by early-stage researchers to learn how to properly communicate their papers to the general public. We evaluate the usefulness of our trained LLM Journalists in leading conversations with both simulated and human researchers. %compared to the general-purpose ones. Our experiments indicate that LLMs trained using our framework ask more relevant questions that address the societal impact of research, prompting researchers to clarify and elaborate on their findings. In the user study, the majority of participants who interacted with our trained LLM Journalist appreciated it more than interacting with general-purpose LLMs.
Evaluating Style-Personalized Text Generation: Challenges and Directions
Aug 08, 2025While prior research has built tools and benchmarks towards style personalized text generation, there has been limited exploration of evaluation in low-resource author style personalized text generation space. Through this work, we question the effectiveness of the widely adopted evaluation metrics like BLEU and ROUGE, and explore other evaluation paradigms such as style embeddings and LLM-as-judge to holistically evaluate the style personalized text generation task. We evaluate these metrics and their ensembles using our style discrimination benchmark, that spans eight writing tasks, and evaluates across three settings, domain discrimination, authorship attribution, and LLM personalized vs non-personalized discrimination. We provide conclusive evidence to adopt ensemble of diverse evaluation metrics to effectively evaluate style personalized text generation.
Navigating the Landscape of Hint Generation Research: From the Past to the Future
Apr 06, 2024Digital education has gained popularity in the last decade, especially after the COVID-19 pandemic. With the improving capabilities of large language models to reason and communicate with users, envisioning intelligent tutoring systems (ITSs) that can facilitate self-learning is not very far-fetched. One integral component to fulfill this vision is the ability to give accurate and effective feedback via hints to scaffold the learning process. In this survey article, we present a comprehensive review of prior research on hint generation, aiming to bridge the gap between research in education and cognitive science, and research in AI and Natural Language Processing. Informed by our findings, we propose a formal definition of the hint generation task, and discuss the roadmap of building an effective hint generation system aligned with the formal definition, including open challenges, future directions and ethical considerations.
TriviaHG: A Dataset for Automatic Hint Generation from Factoid Questions
Mar 27, 2024Nowadays, individuals tend to engage in dialogues with Large Language Models, seeking answers to their questions. In times when such answers are readily accessible to anyone, the stimulation and preservation of human's cognitive abilities, as well as the assurance of maintaining good reasoning skills by humans becomes crucial. This study addresses such needs by proposing hints (instead of final answers or before giving answers) as a viable solution. We introduce a framework for the automatic hint generation for factoid questions, employing it to construct TriviaHG, a novel large-scale dataset featuring 160,230 hints corresponding to 16,645 questions from the TriviaQA dataset. Additionally, we present an automatic evaluation method that measures the Convergence and Familiarity quality attributes of hints. To evaluate the TriviaHG dataset and the proposed evaluation method, we enlisted 10 individuals to annotate 2,791 hints and tasked 6 humans with answering questions using the provided hints. The effectiveness of hints varied, with success rates of 96%, 78%, and 36% for questions with easy, medium, and hard answers, respectively. Moreover, the proposed automatic evaluation methods showed a robust correlation with annotators' results. Conclusively, the findings highlight three key insights: the facilitative role of hints in resolving unknown questions, the dependence of hint quality on answer difficulty, and the feasibility of employing automatic evaluation methods for hint assessment.
Large Scale Multi-Lingual Multi-Modal Summarization Dataset
Feb 13, 2023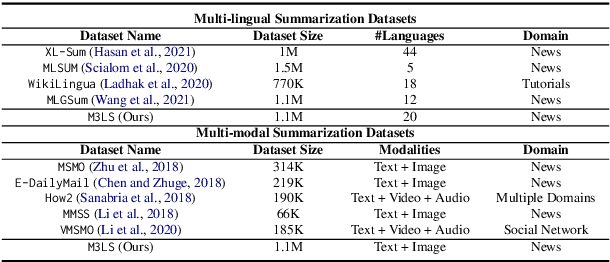

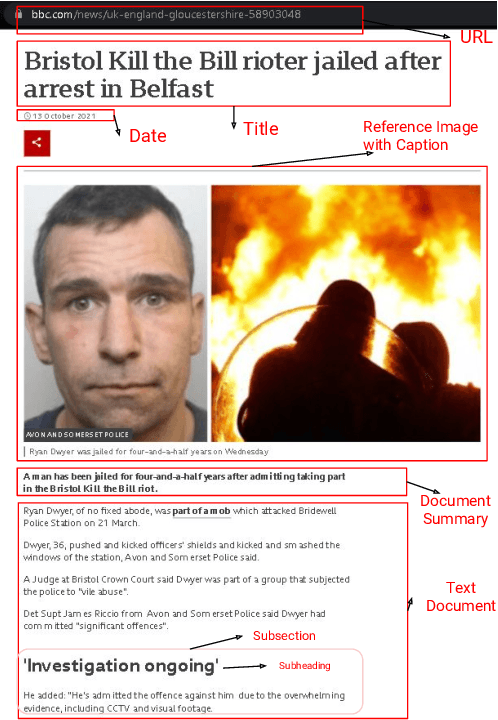
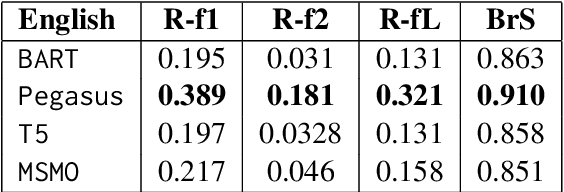
Significant developments in techniques such as encoder-decoder models have enabled us to represent information comprising multiple modalities. This information can further enhance many downstream tasks in the field of information retrieval and natural language processing; however, improvements in multi-modal techniques and their performance evaluation require large-scale multi-modal data which offers sufficient diversity. Multi-lingual modeling for a variety of tasks like multi-modal summarization, text generation, and translation leverages information derived from high-quality multi-lingual annotated data. In this work, we present the current largest multi-lingual multi-modal summarization dataset (M3LS), and it consists of over a million instances of document-image pairs along with a professionally annotated multi-modal summary for each pair. It is derived from news articles published by British Broadcasting Corporation(BBC) over a decade and spans 20 languages, targeting diversity across five language roots, it is also the largest summarization dataset for 13 languages and consists of cross-lingual summarization data for 2 languages. We formally define the multi-lingual multi-modal summarization task utilizing our dataset and report baseline scores from various state-of-the-art summarization techniques in a multi-lingual setting. We also compare it with many similar datasets to analyze the uniqueness and difficulty of M3LS.
A Survey on Medical Document Summarization
Dec 03, 2022
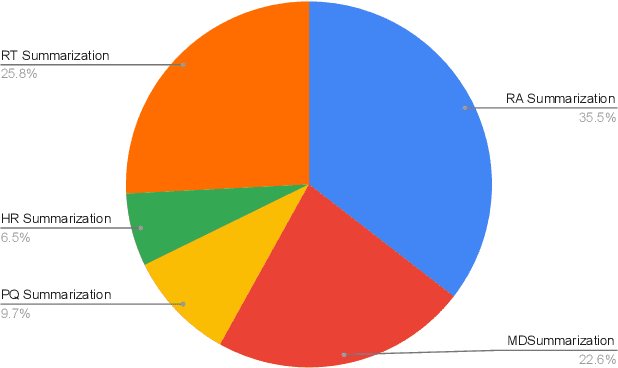

The internet has had a dramatic effect on the healthcare industry, allowing documents to be saved, shared, and managed digitally. This has made it easier to locate and share important data, improving patient care and providing more opportunities for medical studies. As there is so much data accessible to doctors and patients alike, summarizing it has become increasingly necessary - this has been supported through the introduction of deep learning and transformer-based networks, which have boosted the sector significantly in recent years. This paper gives a comprehensive survey of the current techniques and trends in medical summarization
T-STAR: Truthful Style Transfer using AMR Graph as Intermediate Representation
Dec 03, 2022



Unavailability of parallel corpora for training text style transfer (TST) models is a very challenging yet common scenario. Also, TST models implicitly need to preserve the content while transforming a source sentence into the target style. To tackle these problems, an intermediate representation is often constructed that is devoid of style while still preserving the meaning of the source sentence. In this work, we study the usefulness of Abstract Meaning Representation (AMR) graph as the intermediate style agnostic representation. We posit that semantic notations like AMR are a natural choice for an intermediate representation. Hence, we propose T-STAR: a model comprising of two components, text-to-AMR encoder and a AMR-to-text decoder. We propose several modeling improvements to enhance the style agnosticity of the generated AMR. To the best of our knowledge, T-STAR is the first work that uses AMR as an intermediate representation for TST. With thorough experimental evaluation we show T-STAR significantly outperforms state of the art techniques by achieving on an average 15.2% higher content preservation with negligible loss (3% approx.) in style accuracy. Through detailed human evaluation with 90,000 ratings, we also show that T-STAR has up to 50% lesser hallucinations compared to state of the art TST models.
A Survey on Multi-hop Question Answering and Generation
Apr 19, 2022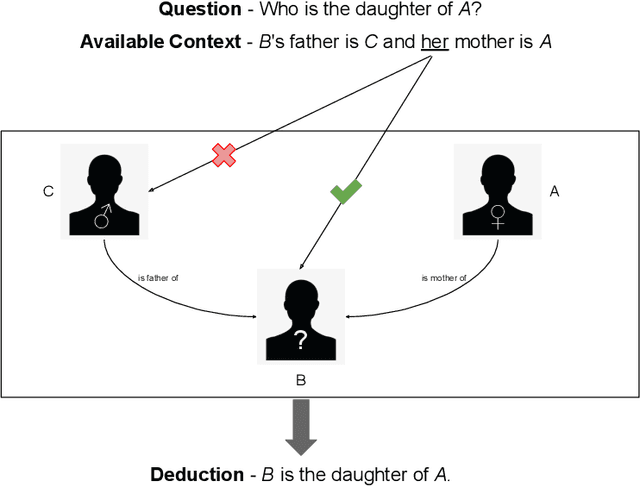

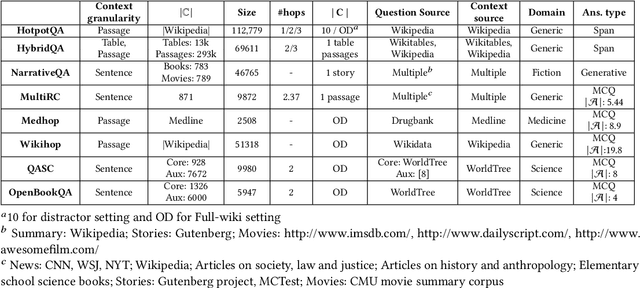
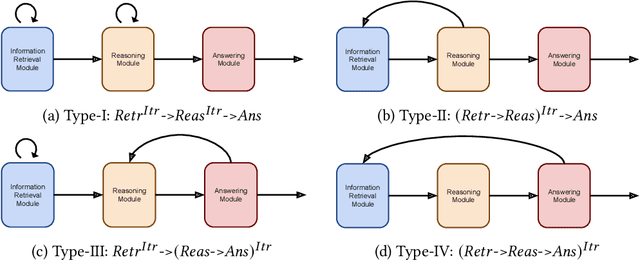
The problem of Question Answering (QA) has attracted significant research interest for long. Its relevance to language understanding and knowledge retrieval tasks, along with the simple setting makes the task of QA crucial for strong AI systems. Recent success on simple QA tasks has shifted the focus to more complex settings. Among these, Multi-Hop QA (MHQA) is one of the most researched tasks over the recent years. The ability to answer multi-hop questions and perform multi step reasoning can significantly improve the utility of NLP systems. Consequently, the field has seen a sudden surge with high quality datasets, models and evaluation strategies. The notion of `multiple hops' is somewhat abstract which results in a large variety of tasks that require multi-hop reasoning. This implies that different datasets and models differ significantly which makes the field challenging to generalize and survey. This work aims to provide a general and formal definition of MHQA task, and organize and summarize existing MHQA frameworks. We also outline the best methods to create MHQA datasets. The paper provides a systematic and thorough introduction as well as the structuring of the existing attempts to this highly interesting, yet quite challenging task.
WIDAR -- Weighted Input Document Augmented ROUGE
Jan 23, 2022

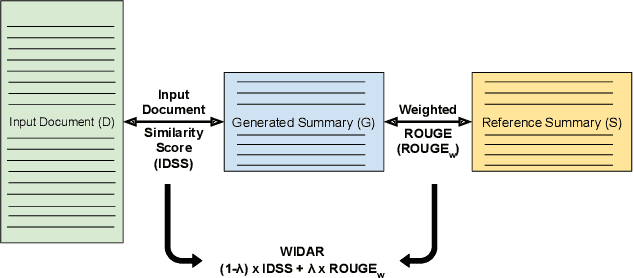
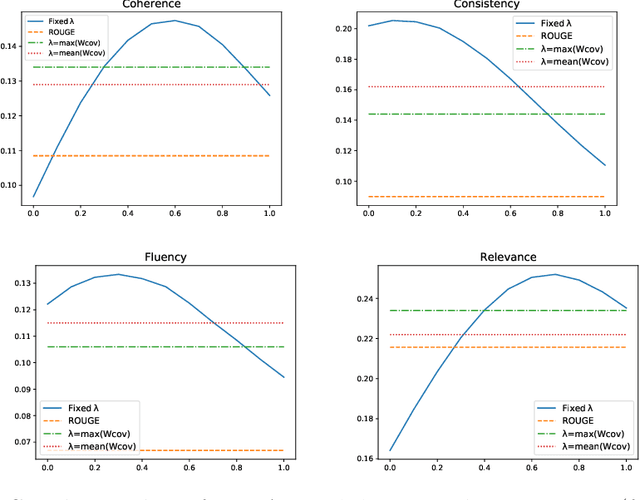
The task of automatic text summarization has gained a lot of traction due to the recent advancements in machine learning techniques. However, evaluating the quality of a generated summary remains to be an open problem. The literature has widely adopted Recall-Oriented Understudy for Gisting Evaluation (ROUGE) as the standard evaluation metric for summarization. However, ROUGE has some long-established limitations; a major one being its dependence on the availability of good quality reference summary. In this work, we propose the metric WIDAR which in addition to utilizing the reference summary uses also the input document in order to evaluate the quality of the generated summary. The proposed metric is versatile, since it is designed to adapt the evaluation score according to the quality of the reference summary. The proposed metric correlates better than ROUGE by 26%, 76%, 82%, and 15%, respectively, in coherence, consistency, fluency, and relevance on human judgement scores provided in the SummEval dataset. The proposed metric is able to obtain comparable results with other state-of-the-art metrics while requiring a relatively short computational time.
A Survey on Multi-modal Summarization
Sep 11, 2021
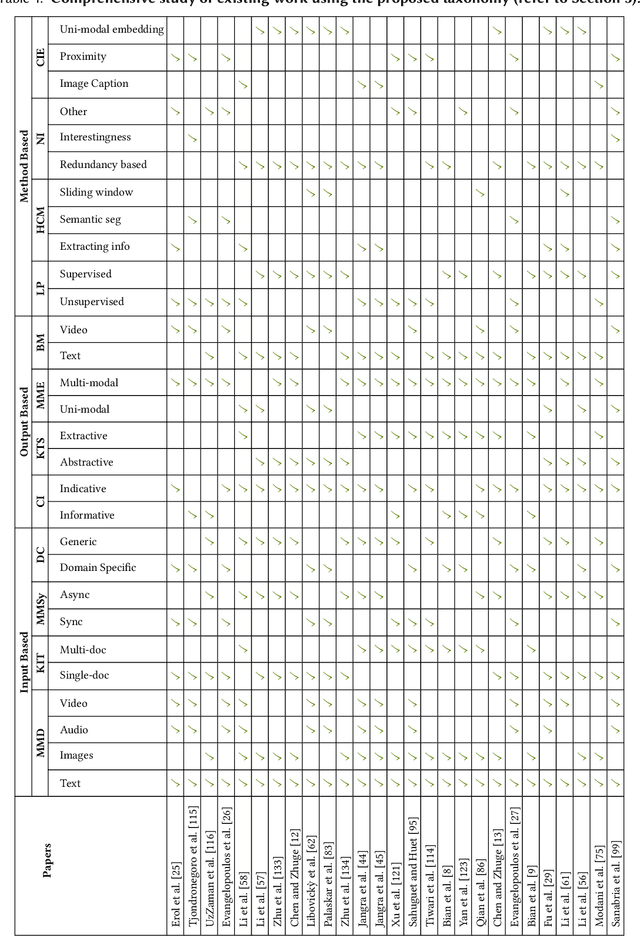
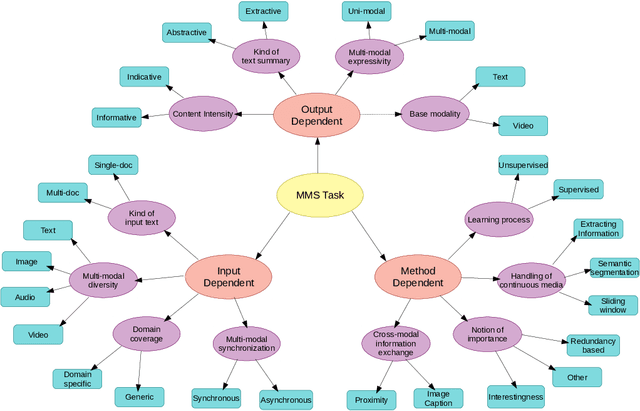

The new era of technology has brought us to the point where it is convenient for people to share their opinions over an abundance of platforms. These platforms have a provision for the users to express themselves in multiple forms of representations, including text, images, videos, and audio. This, however, makes it difficult for users to obtain all the key information about a topic, making the task of automatic multi-modal summarization (MMS) essential. In this paper, we present a comprehensive survey of the existing research in the area of MMS.