 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evaluating LLMs for Multi-Step Tasks: Stepwise Confidence Estimation for Failure Detection
Nov 10, 2025



Reliability and failure detection of large language models (LLMs) is critical for their deployment in high-stakes, multi-step reasoning tasks. Prior work explores confidence estimation for self-evaluating LLM-scorer systems, with confidence scorers estimating the likelihood of errors in LLM responses. However, most methods focus on single-step outputs and overlook the challenges of multi-step reasoning. In this work, we extend self-evaluation techniques to multi-step tasks, testing two intuitive approaches: holistic scoring and step-by-step scoring. Using two multi-step benchmark datasets, we show that stepwise evaluation generally outperforms holistic scoring in detecting potential errors, with up to 15% relative increase in AUC-ROC. Our findings demonstrate that self-evaluating LLM systems provide meaningful confidence estimates in complex reasoning, improving their trustworthiness and providing a practical framework for failure detection.
Retrieval-Augmented Chain-of-Thought in Semi-structured Domains
Oct 22, 2023Applying existing question answering (QA) systems to specialized domains like law and finance presents challenges that necessitate domain expertise. Although large language models (LLMs) have shown impressive language comprehension and in-context learning capabilities, their inability to handle very long inputs/contexts is well known. Tasks specific to these domains need significant background knowledge, leading to contexts that can often exceed the maximum length that existing LLMs can process. This study explores leveraging the semi-structured nature of legal and financial data to efficiently retrieve relevant context, enabling the use of LLMs for domain-specialized QA. The resulting system outperforms contemporary models and also provides useful explanations for the answers, encouraging the integration of LLMs into legal and financial NLP systems for future research.
A Survey on Multi-hop Question Answering and Generation
Apr 19, 2022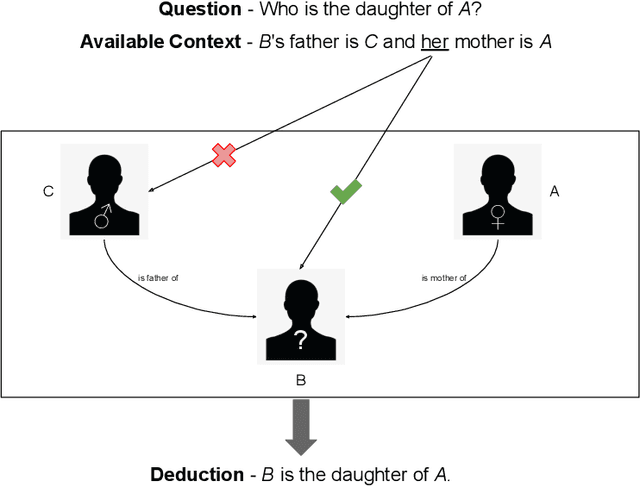

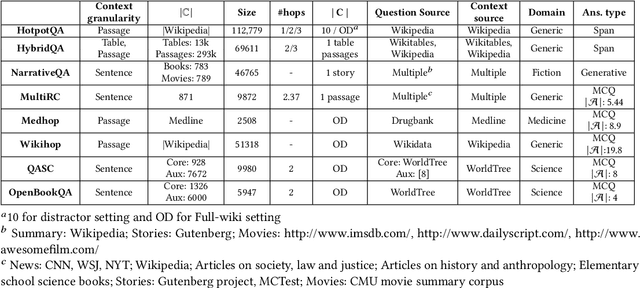
The problem of Question Answering (QA) has attracted significant research interest for long. Its relevance to language understanding and knowledge retrieval tasks, along with the simple setting makes the task of QA crucial for strong AI systems. Recent success on simple QA tasks has shifted the focus to more complex settings. Among these, Multi-Hop QA (MHQA) is one of the most researched tasks over the recent years. The ability to answer multi-hop questions and perform multi step reasoning can significantly improve the utility of NLP systems. Consequently, the field has seen a sudden surge with high quality datasets, models and evaluation strategies. The notion of `multiple hops' is somewhat abstract which results in a large variety of tasks that require multi-hop reasoning. This implies that different datasets and models differ significantly which makes the field challenging to generalize and survey. This work aims to provide a general and formal definition of MHQA task, and organize and summarize existing MHQA frameworks. We also outline the best methods to create MHQA datasets. The paper provides a systematic and thorough introduction as well as the structuring of the existing attempts to this highly interesting, yet quite challenging task.
WIDAR -- Weighted Input Document Augmented ROUGE
Jan 23, 2022

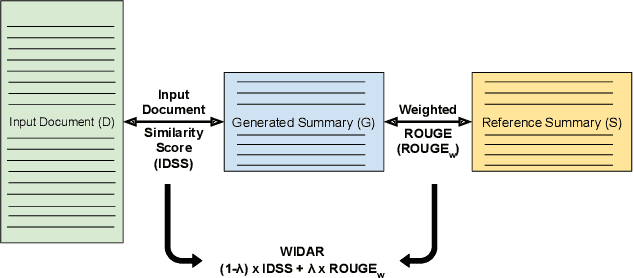
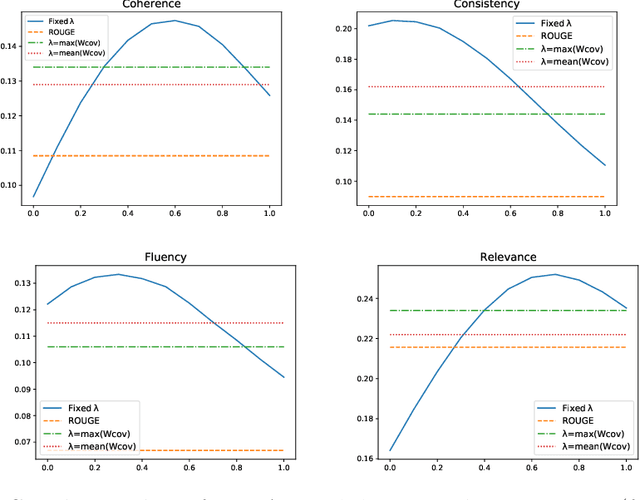
The task of automatic text summarization has gained a lot of traction due to the recent advancements in machine learning techniques. However, evaluating the quality of a generated summary remains to be an open problem. The literature has widely adopted Recall-Oriented Understudy for Gisting Evaluation (ROUGE) as the standard evaluation metric for summarization. However, ROUGE has some long-established limitations; a major one being its dependence on the availability of good quality reference summary. In this work, we propose the metric WIDAR which in addition to utilizing the reference summary uses also the input document in order to evaluate the quality of the generated summary. The proposed metric is versatile, since it is designed to adapt the evaluation score according to the quality of the reference summary. The proposed metric correlates better than ROUGE by 26%, 76%, 82%, and 15%, respectively, in coherence, consistency, fluency, and relevance on human judgement scores provided in the SummEval dataset. The proposed metric is able to obtain comparable results with other state-of-the-art metrics while requiring a relatively short computational time.
Semantic Extractor-Paraphraser based Abstractive Summarization
May 04, 2021

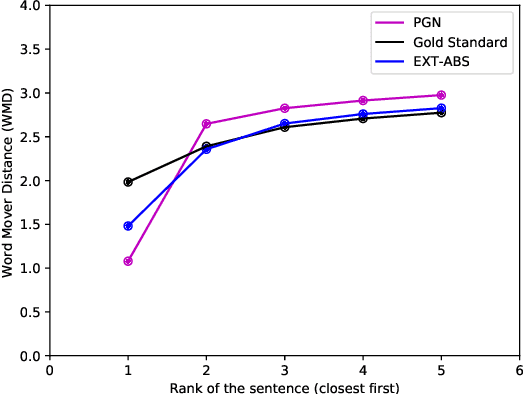

The anthology of spoken languages today is inundated with textual information, necessitating the development of automatic summarization models. In this manuscript, we propose an extractor-paraphraser based abstractive summarization system that exploits semantic overlap as opposed to its predecessors that focus more on syntactic information overlap. Our model outperforms the state-of-the-art baselines in terms of ROUGE, METEOR and word mover similarity (WMS), establishing the superiority of the proposed system via extensive ablation experiments. We have also challenged the summarization capabilities of the state of the art Pointer Generator Network (PGN), and through thorough experimentation, shown that PGN is more of a paraphraser, contrary to the prevailing notion of a summarizer; illustrating it's incapability to accumulate information across multiple sentences.