 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWIDAR -- Weighted Input Document Augmented ROUGE
Paper and Code


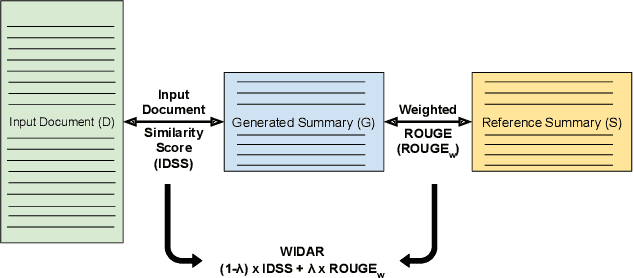
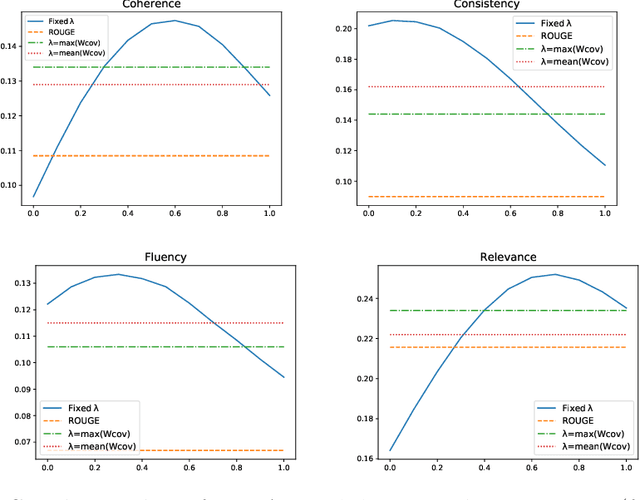
The task of automatic text summarization has gained a lot of traction due to the recent advancements in machine learning techniques. However, evaluating the quality of a generated summary remains to be an open problem. The literature has widely adopted Recall-Oriented Understudy for Gisting Evaluation (ROUGE) as the standard evaluation metric for summarization. However, ROUGE has some long-established limitations; a major one being its dependence on the availability of good quality reference summary. In this work, we propose the metric WIDAR which in addition to utilizing the reference summary uses also the input document in order to evaluate the quality of the generated summary. The proposed metric is versatile, since it is designed to adapt the evaluation score according to the quality of the reference summary. The proposed metric correlates better than ROUGE by 26%, 76%, 82%, and 15%, respectively, in coherence, consistency, fluency, and relevance on human judgement scores provided in the SummEval dataset. The proposed metric is able to obtain comparable results with other state-of-the-art metrics while requiring a relatively short computational time.