 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdopting Whisper for Confidence Estimation
Feb 19, 2025



Recent research on word-level confidence estimation for speech recognition systems has primarily focused on lightweight models known as Confidence Estimation Modules (CEMs), which rely on hand-engineered features derived from Automatic Speech Recognition (ASR) outputs. In contrast, we propose a novel end-to-end approach that leverages the ASR model itself (Whisper) to generate word-level confidence scores. Specifically, we introduce a method in which the Whisper model is fine-tuned to produce scalar confidence scores given an audio input and its corresponding hypothesis transcript. Our experiments demonstrate that the fine-tuned Whisper-tiny model, comparable in size to a strong CEM baseline, achieves similar performance on the in-domain dataset and surpasses the CEM baseline on eight out-of-domain datasets, whereas the fine-tuned Whisper-large model consistently outperforms the CEM baseline by a substantial margin across all datasets.
Improving Rare-Word Recognition of Whisper in Zero-Shot Settings
Feb 18, 2025Whisper, despite being trained on 680K hours of web-scaled audio data, faces difficulty in recognising rare words like domain-specific terms, with a solution being contextual biasing through prompting. To improve upon this method, in this paper, we propose a supervised learning strategy to fine-tune Whisper for contextual biasing instruction. We demonstrate that by using only 670 hours of Common Voice English set for fine-tuning, our model generalises to 11 diverse open-source English datasets, achieving a 45.6% improvement in recognition of rare words and 60.8% improvement in recognition of words unseen during fine-tuning over the baseline method. Surprisingly, our model's contextual biasing ability generalises even to languages unseen during fine-tuning.
Large Scale Multi-Lingual Multi-Modal Summarization Dataset
Feb 13, 2023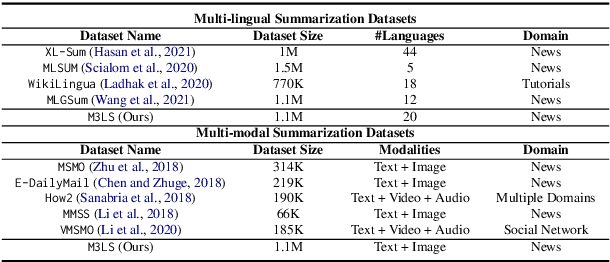

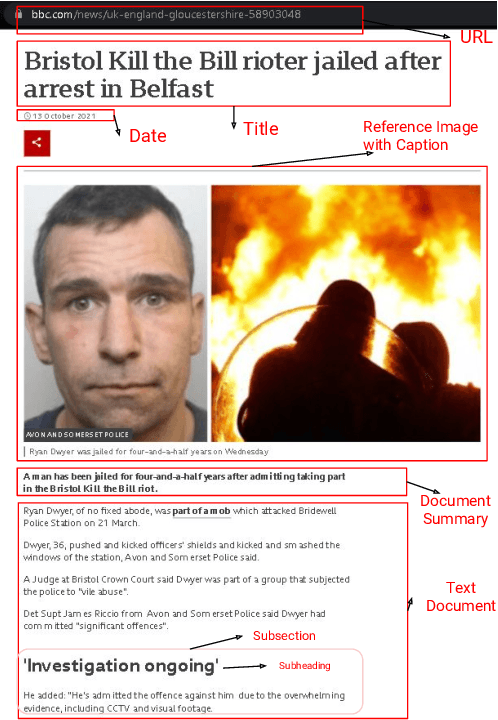
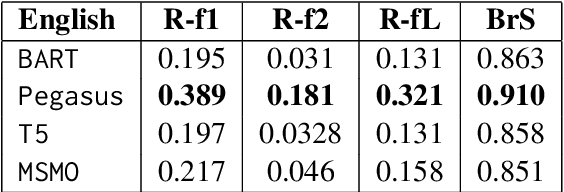
Significant developments in techniques such as encoder-decoder models have enabled us to represent information comprising multiple modalities. This information can further enhance many downstream tasks in the field of information retrieval and natural language processing; however, improvements in multi-modal techniques and their performance evaluation require large-scale multi-modal data which offers sufficient diversity. Multi-lingual modeling for a variety of tasks like multi-modal summarization, text generation, and translation leverages information derived from high-quality multi-lingual annotated data. In this work, we present the current largest multi-lingual multi-modal summarization dataset (M3LS), and it consists of over a million instances of document-image pairs along with a professionally annotated multi-modal summary for each pair. It is derived from news articles published by British Broadcasting Corporation(BBC) over a decade and spans 20 languages, targeting diversity across five language roots, it is also the largest summarization dataset for 13 languages and consists of cross-lingual summarization data for 2 languages. We formally define the multi-lingual multi-modal summarization task utilizing our dataset and report baseline scores from various state-of-the-art summarization techniques in a multi-lingual setting. We also compare it with many similar datasets to analyze the uniqueness and difficulty of M3LS.