 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARS: Dynamic Action Re-Sampling to Enhance Coding Agent Performance by Adaptive Tree Traversal
Mar 18, 2025Large Language Models (LLMs) have revolutionized various domains, including natural language processing, data analysis, and software development, by enabling automation. In software engineering, LLM-powered coding agents have garnered significant attention due to their potential to automate complex development tasks, assist in debugging, and enhance productivity. However, existing approaches often struggle with sub-optimal decision-making, requiring either extensive manual intervention or inefficient compute scaling strategies. To improve coding agent performance, we present Dynamic Action Re-Sampling (DARS), a novel inference time compute scaling approach for coding agents, that is faster and more effective at recovering from sub-optimal decisions compared to baselines. While traditional agents either follow linear trajectories or rely on random sampling for scaling compute, our approach DARS works by branching out a trajectory at certain key decision points by taking an alternative action given the history of the trajectory and execution feedback of the previous attempt from that point. We evaluate our approach on SWE-Bench Lite benchmark, demonstrating that this scaling strategy achieves a pass@k score of 55% with Claude 3.5 Sonnet V2. Our framework achieves a pass@1 rate of 47%, outperforming state-of-the-art (SOTA) open-source frameworks.
Adopting Whisper for Confidence Estimation
Feb 19, 2025



Recent research on word-level confidence estimation for speech recognition systems has primarily focused on lightweight models known as Confidence Estimation Modules (CEMs), which rely on hand-engineered features derived from Automatic Speech Recognition (ASR) outputs. In contrast, we propose a novel end-to-end approach that leverages the ASR model itself (Whisper) to generate word-level confidence scores. Specifically, we introduce a method in which the Whisper model is fine-tuned to produce scalar confidence scores given an audio input and its corresponding hypothesis transcript. Our experiments demonstrate that the fine-tuned Whisper-tiny model, comparable in size to a strong CEM baseline, achieves similar performance on the in-domain dataset and surpasses the CEM baseline on eight out-of-domain datasets, whereas the fine-tuned Whisper-large model consistently outperforms the CEM baseline by a substantial margin across all datasets.
Improving Rare-Word Recognition of Whisper in Zero-Shot Settings
Feb 18, 2025Whisper, despite being trained on 680K hours of web-scaled audio data, faces difficulty in recognising rare words like domain-specific terms, with a solution being contextual biasing through prompting. To improve upon this method, in this paper, we propose a supervised learning strategy to fine-tune Whisper for contextual biasing instruction. We demonstrate that by using only 670 hours of Common Voice English set for fine-tuning, our model generalises to 11 diverse open-source English datasets, achieving a 45.6% improvement in recognition of rare words and 60.8% improvement in recognition of words unseen during fine-tuning over the baseline method. Surprisingly, our model's contextual biasing ability generalises even to languages unseen during fine-tuning.
MobileNetV4 -- Universal Models for the Mobile Ecosystem
Apr 16, 2024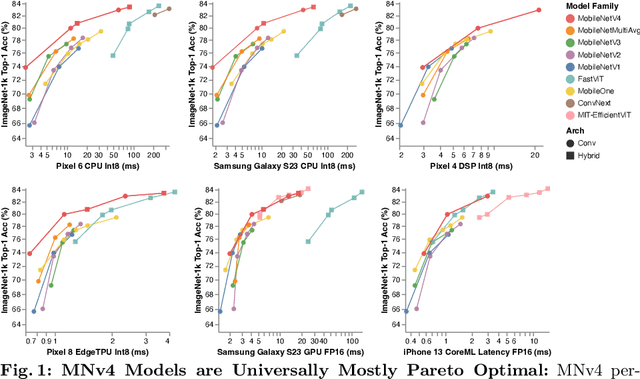
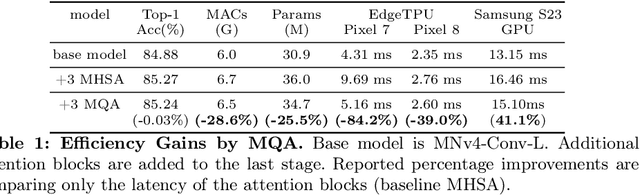
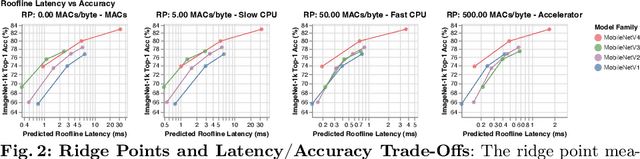
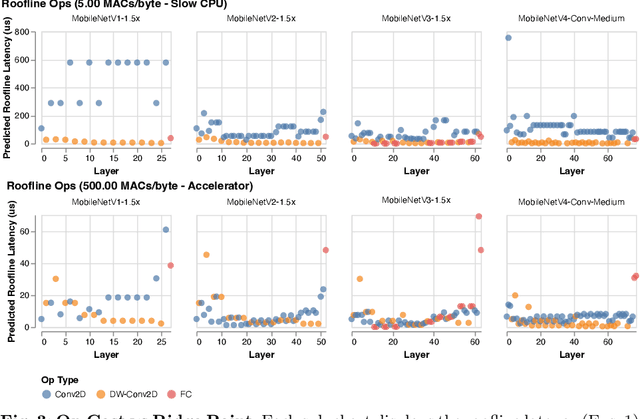
We present the latest generation of MobileNets, known as MobileNetV4 (MNv4), featuring universally efficient architecture designs for mobile devices. At its core, we introduce the Universal Inverted Bottleneck (UIB) search block, a unified and flexible structure that merges Inverted Bottleneck (IB), ConvNext, Feed Forward Network (FFN), and a novel Extra Depthwise (ExtraDW) variant. Alongside UIB, we present Mobile MQA, an attention block tailored for mobile accelerators, delivering a significant 39% speedup. An optimized neural architecture search (NAS) recipe is also introduced which improves MNv4 search effectiveness. The integration of UIB, Mobile MQA and the refined NAS recipe results in a new suite of MNv4 models that are mostly Pareto optimal across mobile CPUs, DSPs, GPUs, as well as specialized accelerators like Apple Neural Engine and Google Pixel EdgeTPU - a characteristic not found in any other models tested. Finally, to further boost accuracy, we introduce a novel distillation technique. Enhanced by this technique, our MNv4-Hybrid-Large model delivers 87% ImageNet-1K accuracy, with a Pixel 8 EdgeTPU runtime of just 3.8ms.
R-MAE: Regions Meet Masked Autoencoders
Jun 08, 2023Vision-specific concepts such as "region" have played a key role in extending general machine learning frameworks to tasks like object detection. Given the success of region-based detectors for supervised learning and the progress of intra-image methods for contrastive learning, we explore the use of regions for reconstructive pre-training. Starting from Masked Autoencoding (MAE) both as a baseline and an inspiration, we propose a parallel pre-text task tailored to address the one-to-many mapping between images and regions. Since such regions can be generated in an unsupervised way, our approach (R-MAE) inherits the wide applicability from MAE, while being more "region-aware". We conduct thorough analyses during the development of R-MAE, and converge on a variant that is both effective and efficient (1.3% overhead over MAE). Moreover, it shows consistent quantitative improvements when generalized to various pre-training data and downstream detection and segmentation benchmarks. Finally, we provide extensive qualitative visualizations to enhance the understanding of R-MAE's behaviour and potential. Code will be made available at https://github.com/facebookresearch/r-mae.
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
Jun 01, 2023



Modern hierarchical vision transformers have added several vision-specific components in the pursuit of supervised classification performance. While these components lead to effective accuracies and attractive FLOP counts, the added complexity actually makes these transformers slower than their vanilla ViT counterparts. In this paper, we argue that this additional bulk is unnecessary. By pretraining with a strong visual pretext task (MAE), we can strip out all the bells-and-whistles from a state-of-the-art multi-stage vision transformer without losing accuracy. In the process, we create Hiera, an extremely simple hierarchical vision transformer that is more accurate than previous models while being significantly faster both at inference and during training. We evaluate Hiera on a variety of tasks for image and video recognition. Our code and models are available at https://github.com/facebookresearch/hiera.
The effectiveness of MAE pre-pretraining for billion-scale pretraining
Mar 23, 2023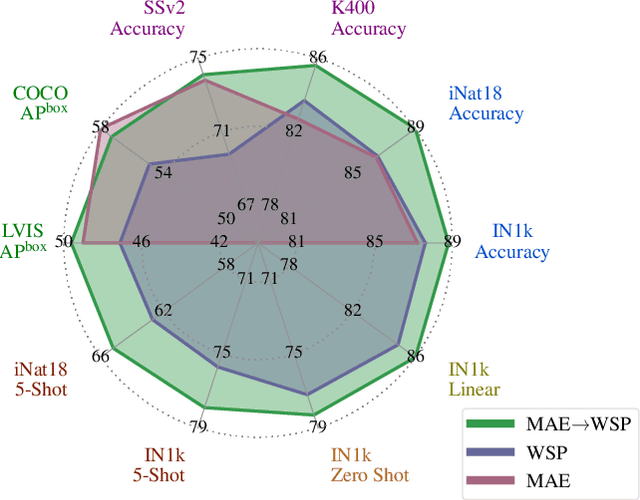

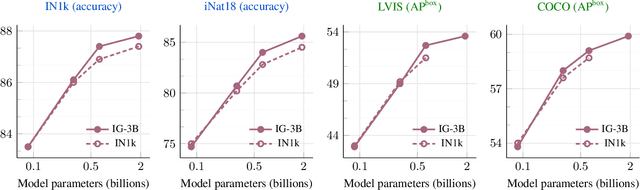
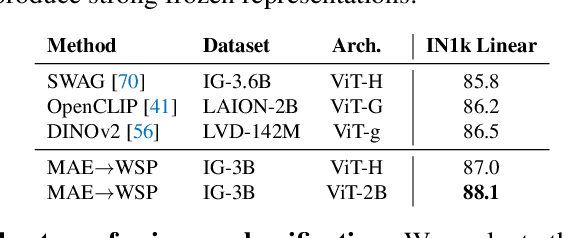
This paper revisits the standard pretrain-then-finetune paradigm used in computer vision for visual recognition tasks. Typically, state-of-the-art foundation models are pretrained using large scale (weakly) supervised datasets with billions of images. We introduce an additional pre-pretraining stage that is simple and uses the self-supervised MAE technique to initialize the model. While MAE has only been shown to scale with the size of models, we find that it scales with the size of the training dataset as well. Thus, our MAE-based pre-pretraining scales with both model and data size making it applicable for training foundation models. Pre-pretraining consistently improves both the model convergence and the downstream transfer performance across a range of model scales (millions to billions of parameters), and dataset sizes (millions to billions of images). We measure the effectiveness of pre-pretraining on 10 different visual recognition tasks spanning image classification, video recognition, object detection, low-shot classification and zero-shot recognition. Our largest model achieves new state-of-the-art results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%). Our study reveals that model initialization plays a significant role, even for web-scale pretraining with billions of images.