 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCReF: Cross-modal and Recurrent Fusion for Depth-conditioned Humanoid Locomotion
Apr 01, 2026Stable traversal over geometrically complex terrain increasingly requires exteroceptive perception, yet prior perceptive humanoid locomotion methods often remain tied to explicit geometric abstractions, either by mediating control through robot-centric 2.5D terrain representations or by shaping depth learning with auxiliary geometry-related targets. Such designs inherit the representational bias of the intermediate or supervisory target and can be restrictive for vertical structures, perforated obstacles, and complex real-world clutter. We propose CReF (Cross-modal and Recurrent Fusion), a single-stage depth-conditioned humanoid locomotion framework that learns locomotion-relevant features directly from raw forward-facing depth without explicit geometric intermediates. CReF couples proprioception and depth tokens through proprioception-queried cross-modal attention, fuses the resulting representation with a gated residual fusion block, and performs temporal integration with a Gated Recurrent Unit (GRU) regulated by a highway-style output gate for state-dependent blending of recurrent and feedforward features. To further improve terrain interaction, we introduce a terrain-aware foothold placement reward that extracts supportable foothold candidates from foot-end point-cloud samples and rewards touchdown locations that lie close to the nearest supportable candidate. Experiments in simulation and on a physical humanoid demonstrate robust traversal over diverse terrains and effective zero-shot transfer to real-world scenes containing handrails, hollow pallet assemblies, severe reflective interference, and visually cluttered outdoor surroundings.
Look Forward to Walk Backward: Efficient Terrain Memory for Backward Locomotion with Forward Vision
Mar 03, 2026Legged robots with egocentric forward-facing depth cameras can couple exteroception and proprioception to achieve robust forward agility on complex terrain. When these robots walk backward, the forward-only field of view provides no preview. Purely proprioceptive controllers can remain stable on moderate ground when moving backward but cannot fully exploit the robot's capabilities on complex terrain and must collide with obstacles. We present Look Forward to Walk Backward (LF2WB), an efficient terrain-memory locomotion framework that uses forward egocentric depth and proprioception to write a compact associative memory during forward motion and to retrieve it for collision-free backward locomotion without rearward vision. The memory backbone employs a delta-rule selective update that softly removes then writes the memory state along the active subspace. Training uses hardware-efficient parallel computation, and deployment runs recurrent, constant-time per-step inference with a constant-size state, making the approach suitable for onboard processors on low-cost robots. Experiments in both simulations and real-world scenarios demonstrate the effectiveness of our method, improving backward agility across complex terrains under limited sensing.
MOVE: Multi-skill Omnidirectional Legged Locomotion with Limited View in 3D Environments
Dec 04, 2024



Legged robots possess inherent advantages in traversing complex 3D terrains. However, previous work on low-cost quadruped robots with egocentric vision systems has been limited by a narrow front-facing view and exteroceptive noise, restricting omnidirectional mobility in such environments. While building a voxel map through a hierarchical structure can refine exteroception processing, it introduces significant computational overhead, noise, and delays. In this paper, we present MOVE, a one-stage end-to-end learning framework capable of multi-skill omnidirectional legged locomotion with limited view in 3D environments, just like what a real animal can do. When movement aligns with the robot's line of sight, exteroceptive perception enhances locomotion, enabling extreme climbing and leaping. When vision is obstructed or the direction of movement lies outside the robot's field of view, the robot relies on proprioception for tasks like crawling and climbing stairs. We integrate all these skills into a single neural network by introducing a pseudo-siamese network structure combining supervised and contrastive learning which helps the robot infer its surroundings beyond its field of view. Experiments in both simulations and real-world scenarios demonstrate the robustness of our method, broadening the operational environments for robotics with egocentric vision.
PIE: Parkour with Implicit-Explicit Learning Framework for Legged Robots
Aug 27, 2024
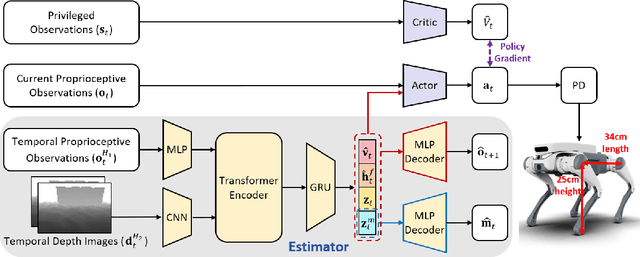


Parkour presents a highly challenging task for legged robots, requiring them to traverse various terrains with agile and smooth locomotion. This necessitates comprehensive understanding of both the robot's own state and the surrounding terrain, despite the inherent unreliability of robot perception and actuation. Current state-of-the-art methods either rely on complex pre-trained high-level terrain reconstruction modules or limit the maximum potential of robot parkour to avoid failure due to inaccurate perception. In this paper, we propose a one-stage end-to-end learning-based parkour framework: Parkour with Implicit-Explicit learning framework for legged robots (PIE) that leverages dual-level implicit-explicit estimation. With this mechanism, even a low-cost quadruped robot equipped with an unreliable egocentric depth camera can achieve exceptional performance on challenging parkour terrains using a relatively simple training process and reward function. While the training process is conducted entirely in simulation, our real-world validation demonstrates successful zero-shot deployment of our framework, showcasing superior parkour performance on harsh terrains.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
May 27, 2024



We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
MobileNetV4 -- Universal Models for the Mobile Ecosystem
Apr 16, 2024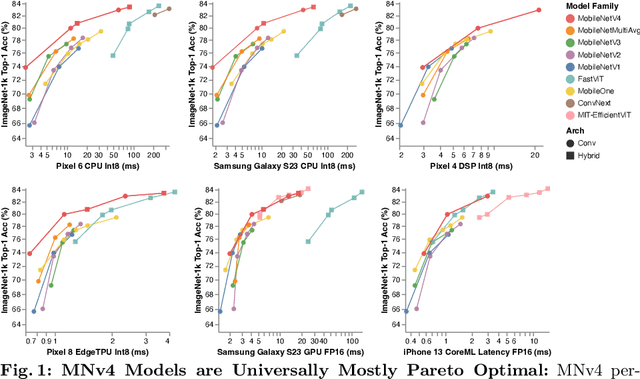
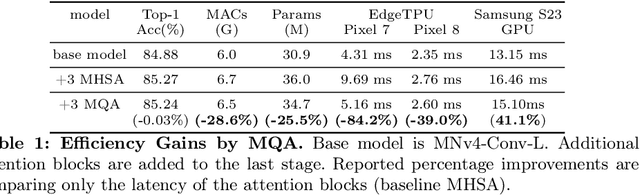
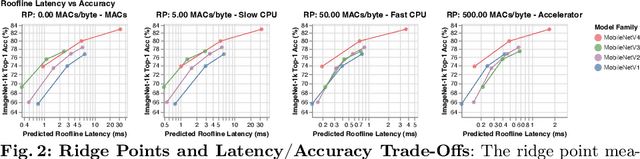
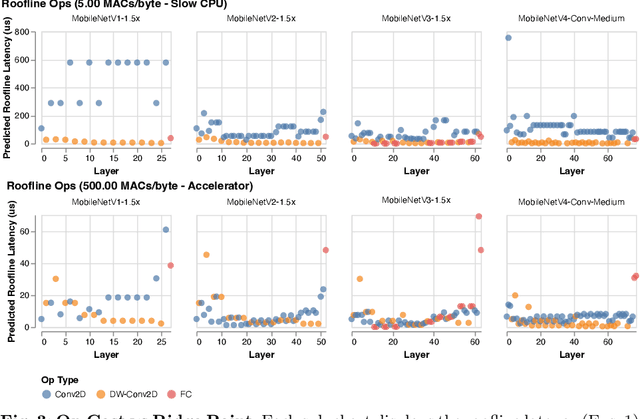
We present the latest generation of MobileNets, known as MobileNetV4 (MNv4), featuring universally efficient architecture designs for mobile devices. At its core, we introduce the Universal Inverted Bottleneck (UIB) search block, a unified and flexible structure that merges Inverted Bottleneck (IB), ConvNext, Feed Forward Network (FFN), and a novel Extra Depthwise (ExtraDW) variant. Alongside UIB, we present Mobile MQA, an attention block tailored for mobile accelerators, delivering a significant 39% speedup. An optimized neural architecture search (NAS) recipe is also introduced which improves MNv4 search effectiveness. The integration of UIB, Mobile MQA and the refined NAS recipe results in a new suite of MNv4 models that are mostly Pareto optimal across mobile CPUs, DSPs, GPUs, as well as specialized accelerators like Apple Neural Engine and Google Pixel EdgeTPU - a characteristic not found in any other models tested. Finally, to further boost accuracy, we introduce a novel distillation technique. Enhanced by this technique, our MNv4-Hybrid-Large model delivers 87% ImageNet-1K accuracy, with a Pixel 8 EdgeTPU runtime of just 3.8ms.