 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Frontier of Audiovisual Perception with Large-Scale Multimodal Correspondence Learning
Dec 22, 2025We introduce Perception Encoder Audiovisual, PE-AV, a new family of encoders for audio and video understanding trained with scaled contrastive learning. Built on PE, PE-AV makes several key contributions to extend representations to audio, and natively support joint embeddings across audio-video, audio-text, and video-text modalities. PE-AV's unified cross-modal embeddings enable novel tasks such as speech retrieval, and set a new state of the art across standard audio and video benchmarks. We unlock this by building a strong audiovisual data engine that synthesizes high-quality captions for O(100M) audio-video pairs, enabling large-scale supervision consistent across modalities. Our audio data includes speech, music, and general sound effects-avoiding single-domain limitations common in prior work. We exploit ten pairwise contrastive objectives, showing that scaling cross-modality and caption-type pairs strengthens alignment and improves zero-shot performance. We further develop PE-A-Frame by fine-tuning PE-AV with frame-level contrastive objectives, enabling fine-grained audio-frame-to-text alignment for tasks such as sound event detection.
Perception Encoder: The best visual embeddings are not at the output of the network
Apr 17, 2025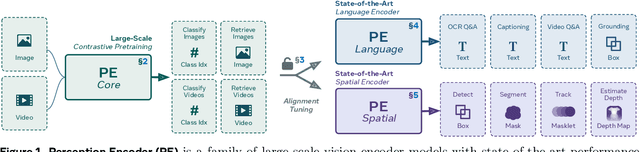

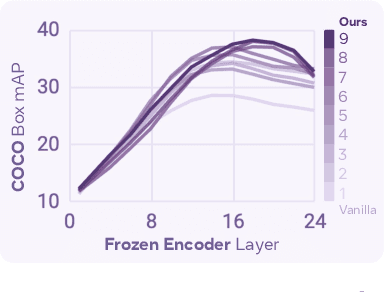
We introduce Perception Encoder (PE), a state-of-the-art encoder for image and video understanding trained via simple vision-language learning. Traditionally, vision encoders have relied on a variety of pretraining objectives, each tailored to specific downstream tasks such as classification, captioning, or localization. Surprisingly, after scaling our carefully tuned image pretraining recipe and refining with our robust video data engine, we find that contrastive vision-language training alone can produce strong, general embeddings for all of these downstream tasks. There is only one caveat: these embeddings are hidden within the intermediate layers of the network. To draw them out, we introduce two alignment methods, language alignment for multimodal language modeling, and spatial alignment for dense prediction. Together with the core contrastive checkpoint, our PE family of models achieves state-of-the-art performance on a wide variety of tasks, including zero-shot image and video classification and retrieval; document, image, and video Q&A; and spatial tasks such as detection, depth estimation, and tracking. To foster further research, we are releasing our models, code, and a novel dataset of synthetically and human-annotated videos.
PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
Altogether: Image Captioning via Re-aligning Alt-text
Oct 22, 2024



This paper focuses on creating synthetic data to improve the quality of image captions. Existing works typically have two shortcomings. First, they caption images from scratch, ignoring existing alt-text metadata, and second, lack transparency if the captioners' training data (e.g. GPT) is unknown. In this paper, we study a principled approach Altogether based on the key idea to edit and re-align existing alt-texts associated with the images. To generate training data, we perform human annotation where annotators start with the existing alt-text and re-align it to the image content in multiple rounds, consequently constructing captions with rich visual concepts. This differs from prior work that carries out human annotation as a one-time description task solely based on images and annotator knowledge. We train a captioner on this data that generalizes the process of re-aligning alt-texts at scale. Our results show our Altogether approach leads to richer image captions that also improve text-to-image generation and zero-shot image classification tasks.
Self-Supervised Audio-Visual Soundscape Stylization
Sep 22, 2024Speech sounds convey a great deal of information about the scenes, resulting in a variety of effects ranging from reverberation to additional ambient sounds. In this paper, we manipulate input speech to sound as though it was recorded within a different scene, given an audio-visual conditional example recorded from that scene. Our model learns through self-supervision, taking advantage of the fact that natural video contains recurring sound events and textures. We extract an audio clip from a video and apply speech enhancement. We then train a latent diffusion model to recover the original speech, using another audio-visual clip taken from elsewhere in the video as a conditional hint. Through this process, the model learns to transfer the conditional example's sound properties to the input speech. We show that our model can be successfully trained using unlabeled, in-the-wild videos, and that an additional visual signal can improve its sound prediction abilities. Please see our project webpage for video results: https://tinglok.netlify.app/files/avsoundscape/
Text Quality-Based Pruning for Efficient Training of Language Models
Apr 26, 2024



In recent times training Language Models (LMs) have relied on computationally heavy training over massive datasets which makes this training process extremely laborious. In this paper we propose a novel method for numerically evaluating text quality in large unlabelled NLP datasets in a model agnostic manner to assign the text instances a "quality score". By proposing the text quality metric, the paper establishes a framework to identify and eliminate low-quality text instances, leading to improved training efficiency for LM models. Experimental results over multiple models and datasets demonstrate the efficacy of this approach, showcasing substantial gains in training effectiveness and highlighting the potential for resource-efficient LM training. For example, we observe an absolute accuracy improvement of 0.9% averaged over 14 downstream evaluation tasks for multiple LM models while using 40% lesser data and training 42% faster when training on the OpenWebText dataset and 0.8% average absolute accuracy improvement while using 20% lesser data and training 21% faster on the Wikipedia dataset.
MoDE: CLIP Data Experts via Clustering
Apr 24, 2024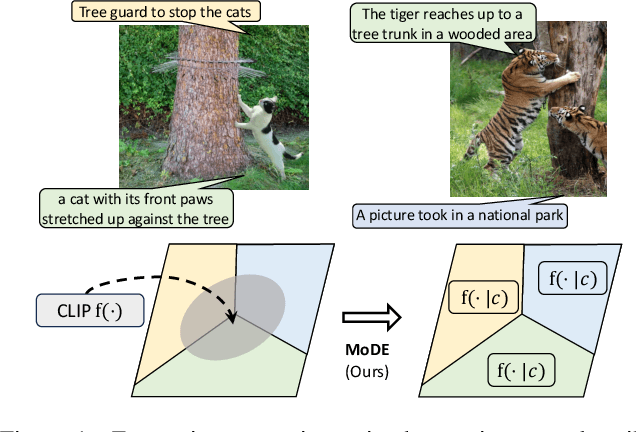
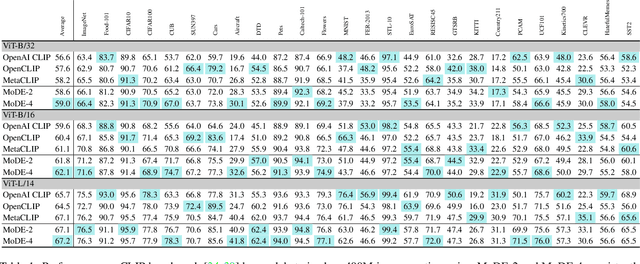

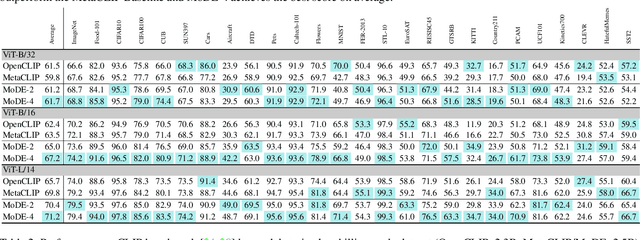
The success of contrastive language-image pretraining (CLIP) relies on the supervision from the pairing between images and captions, which tends to be noisy in web-crawled data. We present Mixture of Data Experts (MoDE) and learn a system of CLIP data experts via clustering. Each data expert is trained on one data cluster, being less sensitive to false negative noises in other clusters. At inference time, we ensemble their outputs by applying weights determined through the correlation between task metadata and cluster conditions. To estimate the correlation precisely, the samples in one cluster should be semantically similar, but the number of data experts should still be reasonable for training and inference. As such, we consider the ontology in human language and propose to use fine-grained cluster centers to represent each data expert at a coarse-grained level. Experimental studies show that four CLIP data experts on ViT-B/16 outperform the ViT-L/14 by OpenAI CLIP and OpenCLIP on zero-shot image classification but with less ($<$35\%) training cost. Meanwhile, MoDE can train all data expert asynchronously and can flexibly include new data experts. The code is available at https://github.com/facebookresearch/MetaCLIP/tree/main/mode.
VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild
Mar 25, 2024We introduce VoiceCraft, a token infilling neural codec language model, that achieves state-of-the-art performance on both speech editing and zero-shot text-to-speech (TTS) on audiobooks, internet videos, and podcasts. VoiceCraft employs a Transformer decoder architecture and introduces a token rearrangement procedure that combines causal masking and delayed stacking to enable generation within an existing sequence. On speech editing tasks, VoiceCraft produces edited speech that is nearly indistinguishable from unedited recordings in terms of naturalness, as evaluated by humans; for zero-shot TTS, our model outperforms prior SotA models including VALLE and the popular commercial model XTTS-v2. Crucially, the models are evaluated on challenging and realistic datasets, that consist of diverse accents, speaking styles, recording conditions, and background noise and music, and our model performs consistently well compared to other models and real recordings. In particular, for speech editing evaluation, we introduce a high quality, challenging, and realistic dataset named RealEdit. We encourage readers to listen to the demos at https://jasonppy.github.io/VoiceCraft_web.
Adversarially Masked Video Consistency for Unsupervised Domain Adaptation
Mar 24, 2024



We study the problem of unsupervised domain adaptation for egocentric videos. We propose a transformer-based model to learn class-discriminative and domain-invariant feature representations. It consists of two novel designs. The first module is called Generative Adversarial Domain Alignment Network with the aim of learning domain-invariant representations. It simultaneously learns a mask generator and a domain-invariant encoder in an adversarial way. The domain-invariant encoder is trained to minimize the distance between the source and target domain. The masking generator, conversely, aims at producing challenging masks by maximizing the domain distance. The second is a Masked Consistency Learning module to learn class-discriminative representations. It enforces the prediction consistency between the masked target videos and their full forms. To better evaluate the effectiveness of domain adaptation methods, we construct a more challenging benchmark for egocentric videos, U-Ego4D. Our method achieves state-of-the-art performance on the Epic-Kitchen and the proposed U-Ego4D benchmark.
FLAP: Fast Language-Audio Pre-training
Nov 02, 2023We propose Fast Language-Audio Pre-training (FLAP), a self-supervised approach that efficiently and effectively learns aligned audio and language representations through masking, contrastive learning and reconstruction. For efficiency, FLAP randomly drops audio spectrogram tokens, focusing solely on the remaining ones for self-supervision. Through inter-modal contrastive learning, FLAP learns to align paired audio and text representations in a shared latent space. Notably, FLAP leverages multiple augmented views via masking for inter-modal contrast and learns to reconstruct the masked portion of audio tokens. Moreover, FLAP leverages large language models (LLMs) to augment the text inputs, contributing to improved performance. These approaches lead to more robust and informative audio-text representations, enabling FLAP to achieve state-of-the-art (SoTA) performance on audio-text retrieval tasks on AudioCaps (achieving 53.0% R@1) and Clotho (achieving 25.5% R@1).