 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaCLIP 2: A Worldwide Scaling Recipe
Jul 29, 2025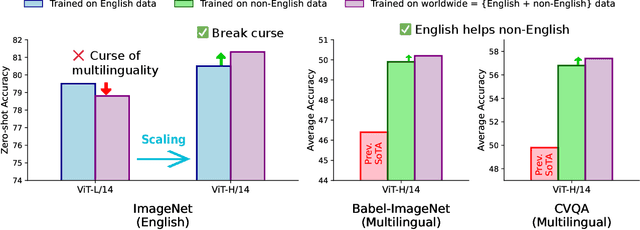
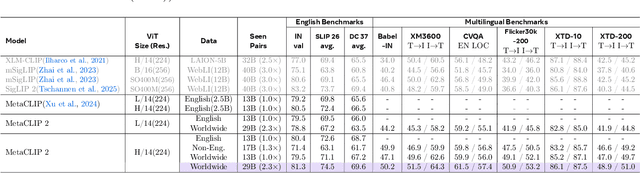
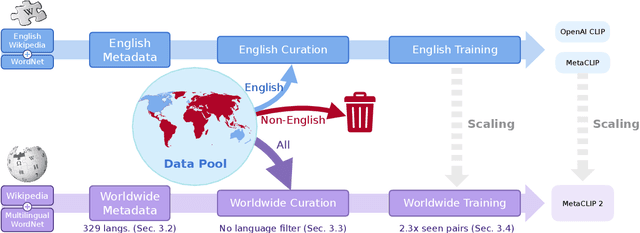

Contrastive Language-Image Pretraining (CLIP) is a popular foundation model, supporting from zero-shot classification, retrieval to encoders for multimodal large language models (MLLMs). Although CLIP is successfully trained on billion-scale image-text pairs from the English world, scaling CLIP's training further to learning from the worldwide web data is still challenging: (1) no curation method is available to handle data points from non-English world; (2) the English performance from existing multilingual CLIP is worse than its English-only counterpart, i.e., "curse of multilinguality" that is common in LLMs. Here, we present MetaCLIP 2, the first recipe training CLIP from scratch on worldwide web-scale image-text pairs. To generalize our findings, we conduct rigorous ablations with minimal changes that are necessary to address the above challenges and present a recipe enabling mutual benefits from English and non-English world data. In zero-shot ImageNet classification, MetaCLIP 2 ViT-H/14 surpasses its English-only counterpart by 0.8% and mSigLIP by 0.7%, and surprisingly sets new state-of-the-art without system-level confounding factors (e.g., translation, bespoke architecture changes) on multilingual benchmarks, such as CVQA with 57.4%, Babel-ImageNet with 50.2% and XM3600 with 64.3% on image-to-text retrieval.
Altogether: Image Captioning via Re-aligning Alt-text
Oct 22, 2024



This paper focuses on creating synthetic data to improve the quality of image captions. Existing works typically have two shortcomings. First, they caption images from scratch, ignoring existing alt-text metadata, and second, lack transparency if the captioners' training data (e.g. GPT) is unknown. In this paper, we study a principled approach Altogether based on the key idea to edit and re-align existing alt-texts associated with the images. To generate training data, we perform human annotation where annotators start with the existing alt-text and re-align it to the image content in multiple rounds, consequently constructing captions with rich visual concepts. This differs from prior work that carries out human annotation as a one-time description task solely based on images and annotator knowledge. We train a captioner on this data that generalizes the process of re-aligning alt-texts at scale. Our results show our Altogether approach leads to richer image captions that also improve text-to-image generation and zero-shot image classification tasks.
Attention or Convolution: Transformer Encoders in Audio Language Models for Inference Efficiency
Nov 05, 2023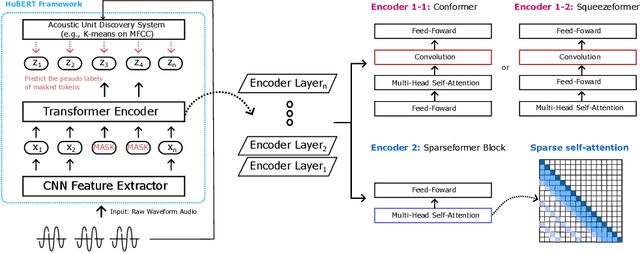
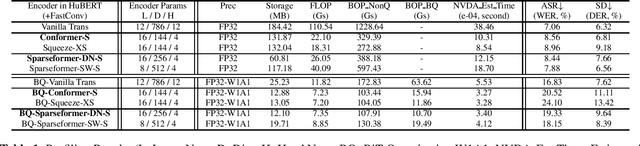
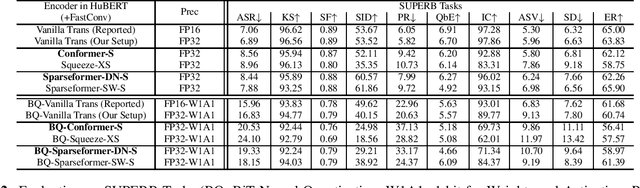
In this paper, we show that a simple self-supervised pre-trained audio model can achieve comparable inference efficiency to more complicated pre-trained models with speech transformer encoders. These speech transformers rely on mixing convolutional modules with self-attention modules. They achieve state-of-the-art performance on ASR with top efficiency. We first show that employing these speech transformers as an encoder significantly improves the efficiency of pre-trained audio models as well. However, our study shows that we can achieve comparable efficiency with advanced self-attention solely. We demonstrate that this simpler approach is particularly beneficial with a low-bit weight quantization technique of a neural network to improve efficiency. We hypothesize that it prevents propagating the errors between different quantized modules compared to recent speech transformers mixing quantized convolution and the quantized self-attention modules.
FLAP: Fast Language-Audio Pre-training
Nov 02, 2023We propose Fast Language-Audio Pre-training (FLAP), a self-supervised approach that efficiently and effectively learns aligned audio and language representations through masking, contrastive learning and reconstruction. For efficiency, FLAP randomly drops audio spectrogram tokens, focusing solely on the remaining ones for self-supervision. Through inter-modal contrastive learning, FLAP learns to align paired audio and text representations in a shared latent space. Notably, FLAP leverages multiple augmented views via masking for inter-modal contrast and learns to reconstruct the masked portion of audio tokens. Moreover, FLAP leverages large language models (LLMs) to augment the text inputs, contributing to improved performance. These approaches lead to more robust and informative audio-text representations, enabling FLAP to achieve state-of-the-art (SoTA) performance on audio-text retrieval tasks on AudioCaps (achieving 53.0% R@1) and Clotho (achieving 25.5% R@1).
Efficient Speech Representation Learning with Low-Bit Quantization
Dec 14, 2022


With the development of hardware for machine learning, newer models often come at the cost of both increased sizes and computational complexity. In effort to improve the efficiency for these models, we apply and investigate recent quantization techniques on speech representation learning models. The quantization techniques were evaluated on the SUPERB benchmark. On the ASR task, with aggressive quantization to 1 bit, we achieved 86.32% storage reduction (184.42 -> 25.23), 88% estimated runtime reduction (1.00 -> 0.12) with increased word error rate (7.06 -> 15.96). In comparison with DistillHuBERT which also aims for model compression, the 2-bit configuration yielded slightly smaller storage (35.84 vs. 46.98), better word error rate (12.68 vs. 13.37) and more efficient estimated runtime (0.15 vs. 0.73).
Continual Learning for On-Device Speech Recognition using Disentangled Conformers
Dec 13, 2022
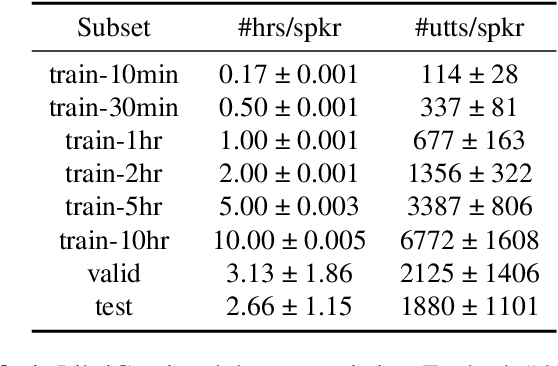
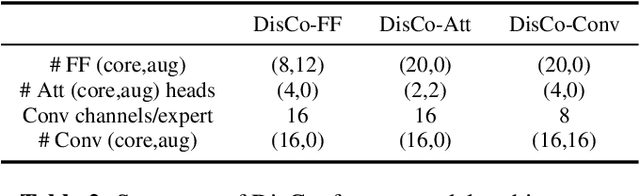
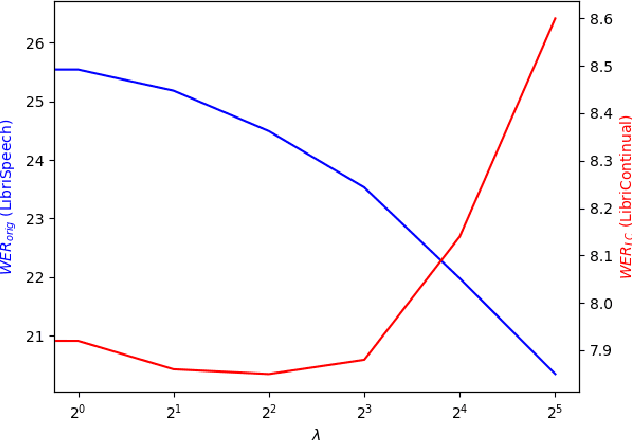
Automatic speech recognition research focuses on training and evaluating on static datasets. Yet, as speech models are increasingly deployed on personal devices, such models encounter user-specific distributional shifts. To simulate this real-world scenario, we introduce LibriContinual, a continual learning benchmark for speaker-specific domain adaptation derived from LibriVox audiobooks, with data corresponding to 118 individual speakers and 6 train splits per speaker of different sizes. Additionally, current speech recognition models and continual learning algorithms are not optimized to be compute-efficient. We adapt a general-purpose training algorithm NetAug for ASR and create a novel Conformer variant called the DisConformer (Disentangled Conformer). This algorithm produces ASR models consisting of a frozen 'core' network for general-purpose use and several tunable 'augment' networks for speaker-specific tuning. Using such models, we propose a novel compute-efficient continual learning algorithm called DisentangledCL. Our experiments show that the DisConformer models significantly outperform baselines on general ASR i.e. LibriSpeech (15.58% rel. WER on test-other). On speaker-specific LibriContinual they significantly outperform trainable-parameter-matched baselines (by 20.65% rel. WER on test) and even match fully finetuned baselines in some settings.
SUPERB @ SLT 2022: Challenge on Generalization and Efficiency of Self-Supervised Speech Representation Learning
Oct 16, 2022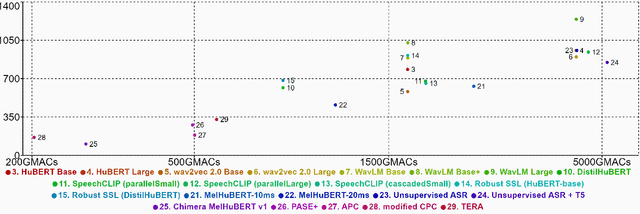
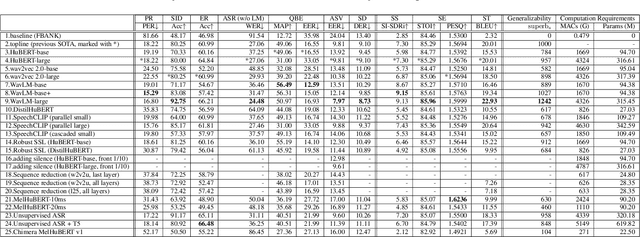
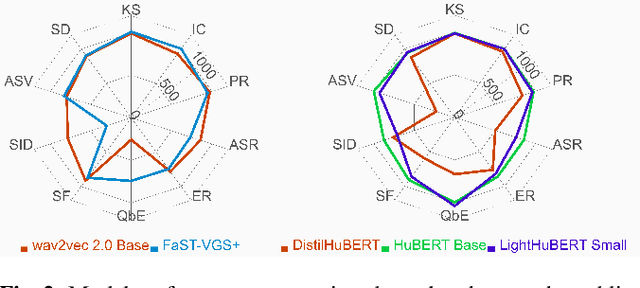
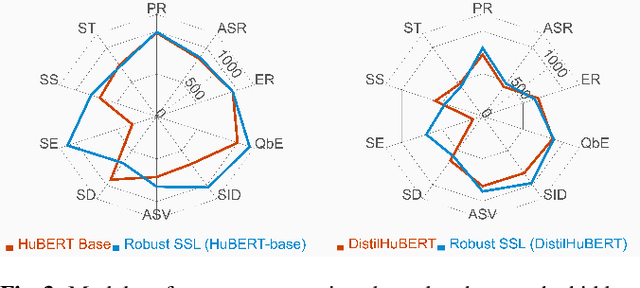
We present the SUPERB challenge at SLT 2022, which aims at learning self-supervised speech representation for better performance, generalization, and efficiency. The challenge builds upon the SUPERB benchmark and implements metrics to measure the computation requirements of self-supervised learning (SSL) representation and to evaluate its generalizability and performance across the diverse SUPERB tasks. The SUPERB benchmark provides comprehensive coverage of popular speech processing tasks, from speech and speaker recognition to audio generation and semantic understanding. As SSL has gained interest in the speech community and showed promising outcomes, we envision the challenge to uplevel the impact of SSL techniques by motivating more practical designs of techniques beyond task performance. We summarize the results of 14 submitted models in this paper. We also discuss the main findings from those submissions and the future directions of SSL research.
TorchAudio: Building Blocks for Audio and Speech Processing
Oct 28, 2021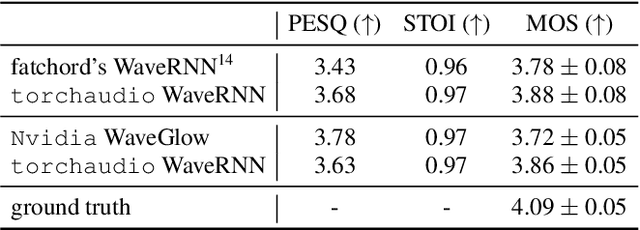
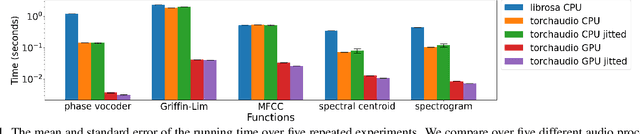


This document describes version 0.10 of torchaudio: building blocks for machine learning applications in the audio and speech processing domain. The objective of torchaudio is to accelerate the development and deployment of machine learning applications for researchers and engineers by providing off-the-shelf building blocks. The building blocks are designed to be GPU-compatible, automatically differentiable, and production-ready. torchaudio can be easily installed from Python Package Index repository and the source code is publicly available under a BSD-2-Clause License (as of September 2021) at https://github.com/pytorch/audio. In this document, we provide an overview of the design principles, functionalities, and benchmarks of torchaudio. We also benchmark our implementation of several audio and speech operations and models. We verify through the benchmarks that our implementations of various operations and models are valid and perform similarly to other publicly available implementations.
Dynamic Encoder Transducer: A Flexible Solution For Trading Off Accuracy For Latency
Apr 05, 2021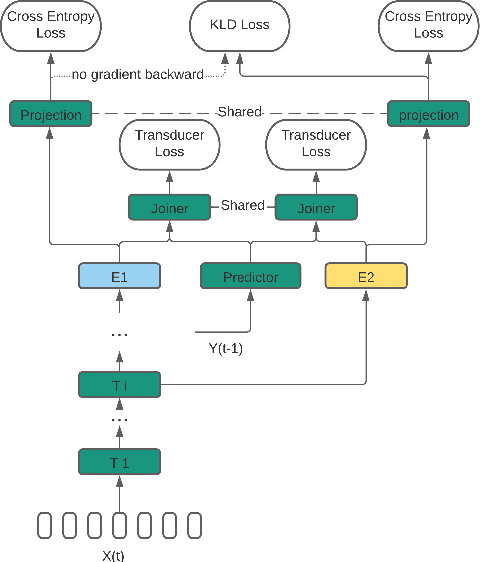
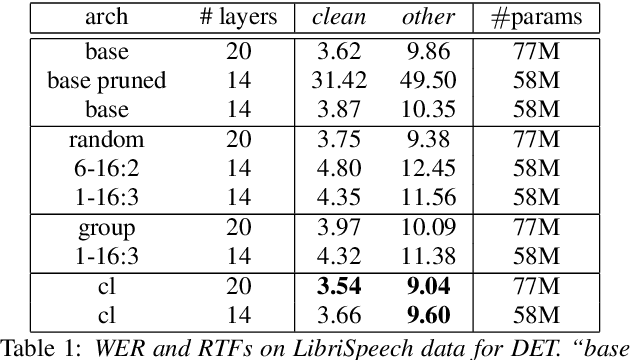
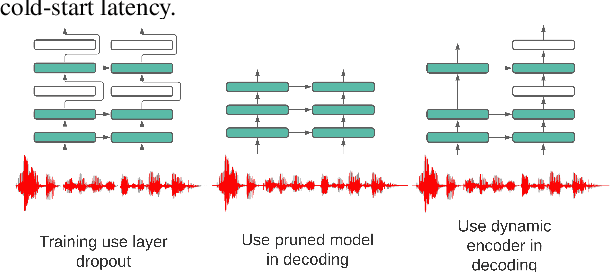
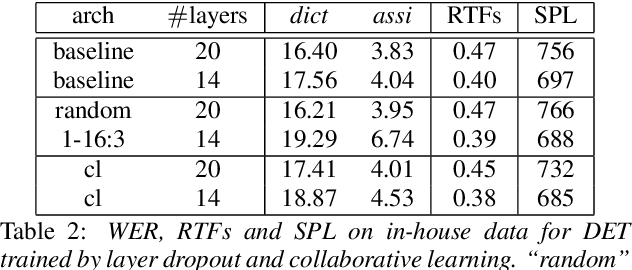
We propose a dynamic encoder transducer (DET) for on-device speech recognition. One DET model scales to multiple devices with different computation capacities without retraining or finetuning. To trading off accuracy and latency, DET assigns different encoders to decode different parts of an utterance. We apply and compare the layer dropout and the collaborative learning for DET training. The layer dropout method that randomly drops out encoder layers in the training phase, can do on-demand layer dropout in decoding. Collaborative learning jointly trains multiple encoders with different depths in one single model. Experiment results on Librispeech and in-house data show that DET provides a flexible accuracy and latency trade-off. Results on Librispeech show that the full-size encoder in DET relatively reduces the word error rate of the same size baseline by over 8%. The lightweight encoder in DET trained with collaborative learning reduces the model size by 25% but still gets similar WER as the full-size baseline. DET gets similar accuracy as a baseline model with better latency on a large in-house data set by assigning a lightweight encoder for the beginning part of one utterance and a full-size encoder for the rest.
Semantic Distance: A New Metric for ASR Performance Analysis Towards Spoken Language Understanding
Apr 05, 2021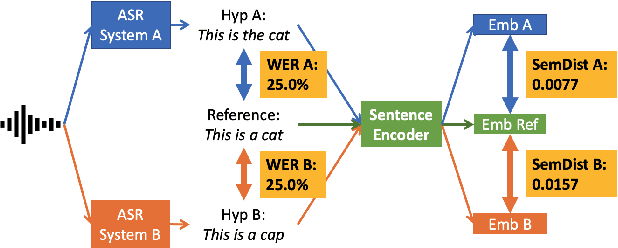

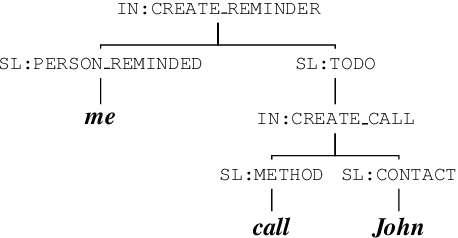

Word Error Rate (WER) has been the predominant metric used to evaluate the performance of automatic speech recognition (ASR) systems. However, WER is sometimes not a good indicator for downstream Natural Language Understanding (NLU) tasks, such as intent recognition, slot filling, and semantic parsing in task-oriented dialog systems. This is because WER takes into consideration only literal correctness instead of semantic correctness, the latter of which is typically more important for these downstream tasks. In this study, we propose a novel Semantic Distance (SemDist) measure as an alternative evaluation metric for ASR systems to address this issue. We define SemDist as the distance between a reference and hypothesis pair in a sentence-level embedding space. To represent the reference and hypothesis as a sentence embedding, we exploit RoBERTa, a state-of-the-art pre-trained deep contextualized language model based on the transformer architecture. We demonstrate the effectiveness of our proposed metric on various downstream tasks, including intent recognition, semantic parsing, and named entity recognition.