 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Restricted Streaming Recurrent Neural Network Transducer
Nov 05, 2020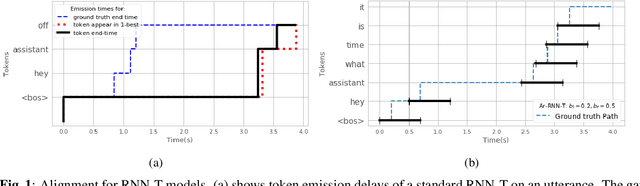
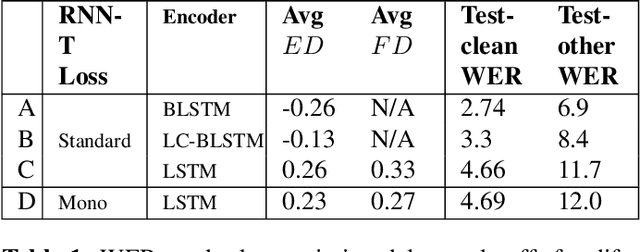
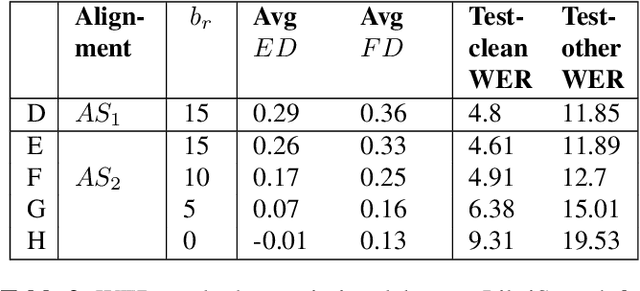
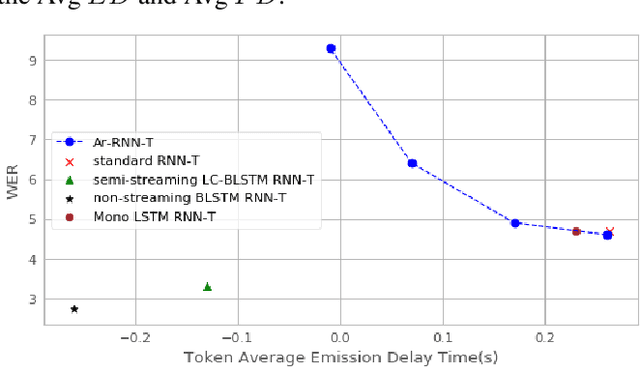
There is a growing interest in the speech community in developing Recurrent Neural Network Transducer (RNN-T) models for automatic speech recognition (ASR) applications. RNN-T is trained with a loss function that does not enforce temporal alignment of the training transcripts and audio. As a result, RNN-T models built with uni-directional long short term memory (LSTM) encoders tend to wait for longer spans of input audio, before streaming already decoded ASR tokens. In this work, we propose a modification to the RNN-T loss function and develop Alignment Restricted RNN-T (Ar-RNN-T) models, which utilize audio-text alignment information to guide the loss computation. We compare the proposed method with existing works, such as monotonic RNN-T, on LibriSpeech and in-house datasets. We show that the Ar-RNN-T loss provides a refined control to navigate the trade-offs between the token emission delays and the Word Error Rate (WER). The Ar-RNN-T models also improve downstream applications such as the ASR End-pointing by guaranteeing token emissions within any given range of latency. Moreover, the Ar-RNN-T loss allows for bigger batch sizes and 4 times higher throughput for our LSTM model architecture, enabling faster training and convergence on GPUs.
Query-Efficient Hard-label Black-box Attack:An Optimization-based Approach
Jul 12, 2018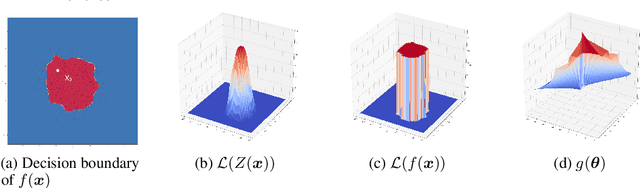

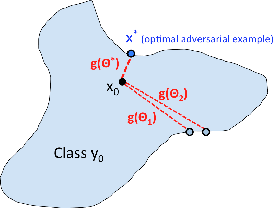
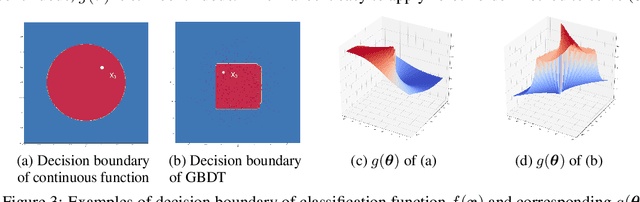
We study the problem of attacking a machine learning model in the hard-label black-box setting, where no model information is revealed except that the attacker can make queries to probe the corresponding hard-label decisions. This is a very challenging problem since the direct extension of state-of-the-art white-box attacks (e.g., CW or PGD) to the hard-label black-box setting will require minimizing a non-continuous step function, which is combinatorial and cannot be solved by a gradient-based optimizer. The only current approach is based on random walk on the boundary, which requires lots of queries and lacks convergence guarantees. We propose a novel way to formulate the hard-label black-box attack as a real-valued optimization problem which is usually continuous and can be solved by any zeroth order optimization algorithm. For example, using the Randomized Gradient-Free method, we are able to bound the number of iterations needed for our algorithm to achieve stationary points. We demonstrate that our proposed method outperforms the previous random walk approach to attacking convolutional neural networks on MNIST, CIFAR, and ImageNet datasets. More interestingly, we show that the proposed algorithm can also be used to attack other discrete and non-continuous machine learning models, such as Gradient Boosting Decision Trees (GBDT).