 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Algorithms for Generalized Linear Bandits with Heavy-tailed Rewards
Oct 28, 2023
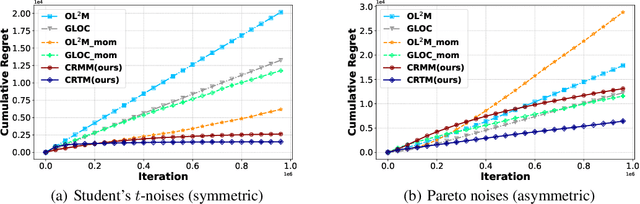
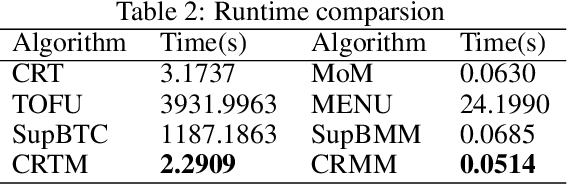
This paper investigates the problem of generalized linear bandits with heavy-tailed rewards, whose $(1+\epsilon)$-th moment is bounded for some $\epsilon\in (0,1]$. Although there exist methods for generalized linear bandits, most of them focus on bounded or sub-Gaussian rewards and are not well-suited for many real-world scenarios, such as financial markets and web-advertising. To address this issue, we propose two novel algorithms based on truncation and mean of medians. These algorithms achieve an almost optimal regret bound of $\widetilde{O}(dT^{\frac{1}{1+\epsilon}})$, where $d$ is the dimension of contextual information and $T$ is the time horizon. Our truncation-based algorithm supports online learning, distinguishing it from existing truncation-based approaches. Additionally, our mean-of-medians-based algorithm requires only $O(\log T)$ rewards and one estimator per epoch, making it more practical. Moreover, our algorithms improve the regret bounds by a logarithmic factor compared to existing algorithms when $\epsilon=1$. Numerical experimental results confirm the merits of our algorithms.
Smoothed Online Convex Optimization Based on Discounted-Normal-Predictor
May 02, 2022In this paper, we investigate an online prediction strategy named as Discounted-Normal-Predictor (Kapralov and Panigrahy, 2010) for smoothed online convex optimization (SOCO), in which the learner needs to minimize not only the hitting cost but also the switching cost. In the setting of learning with expert advice, Daniely and Mansour (2019) demonstrate that Discounted-Normal-Predictor can be utilized to yield nearly optimal regret bounds over any interval, even in the presence of switching costs. Inspired by their results, we develop a simple algorithm for SOCO: Combining online gradient descent (OGD) with different step sizes sequentially by Discounted-Normal-Predictor. Despite its simplicity, we prove that it is able to minimize the adaptive regret with switching cost, i.e., attaining nearly optimal regret with switching cost on every interval. By exploiting the theoretical guarantee of OGD for dynamic regret, we further show that the proposed algorithm can minimize the dynamic regret with switching cost in every interval.
How to Robustify Black-Box ML Models? A Zeroth-Order Optimization Perspective
Mar 27, 2022

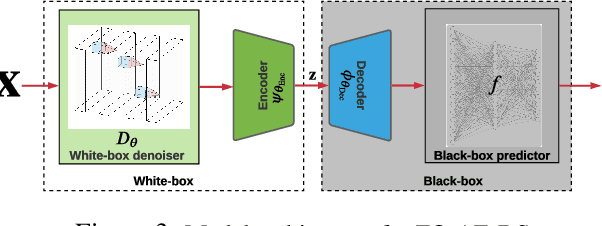

The lack of adversarial robustness has been recognized as an important issue for state-of-the-art machine learning (ML) models, e.g., deep neural networks (DNNs). Thereby, robustifying ML models against adversarial attacks is now a major focus of research. However, nearly all existing defense methods, particularly for robust training, made the white-box assumption that the defender has the access to the details of an ML model (or its surrogate alternatives if available), e.g., its architectures and parameters. Beyond existing works, in this paper we aim to address the problem of black-box defense: How to robustify a black-box model using just input queries and output feedback? Such a problem arises in practical scenarios, where the owner of the predictive model is reluctant to share model information in order to preserve privacy. To this end, we propose a general notion of defensive operation that can be applied to black-box models, and design it through the lens of denoised smoothing (DS), a first-order (FO) certified defense technique. To allow the design of merely using model queries, we further integrate DS with the zeroth-order (gradient-free) optimization. However, a direct implementation of zeroth-order (ZO) optimization suffers a high variance of gradient estimates, and thus leads to ineffective defense. To tackle this problem, we next propose to prepend an autoencoder (AE) to a given (black-box) model so that DS can be trained using variance-reduced ZO optimization. We term the eventual defense as ZO-AE-DS. In practice, we empirically show that ZO-AE- DS can achieve improved accuracy, certified robustness, and query complexity over existing baselines. And the effectiveness of our approach is justified under both image classification and image reconstruction tasks. Codes are available at https://github.com/damon-demon/Black-Box-Defense.
Can Adversarial Training Be Manipulated By Non-Robust Features?
Jan 31, 2022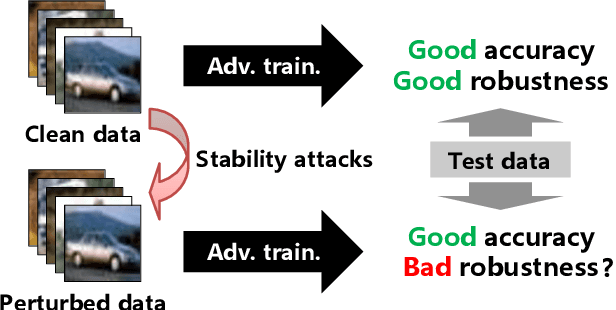
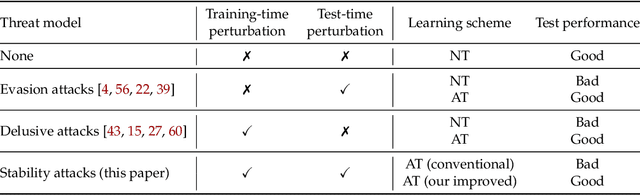
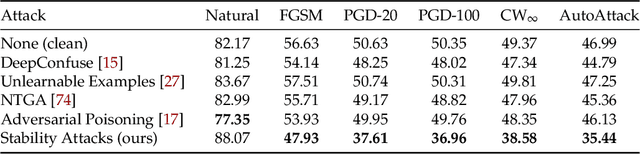
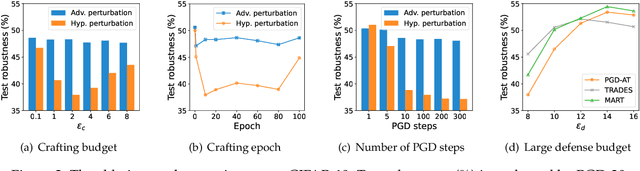
Adversarial training, originally designed to resist test-time adversarial examples, has shown to be promising in mitigating training-time availability attacks. This defense ability, however, is challenged in this paper. We identify a novel threat model named stability attacks, which aims to hinder robust availability by slightly perturbing the training data. Under this threat, we find that adversarial training using a conventional defense budget $\epsilon$ provably fails to provide test robustness in a simple statistical setting when the non-robust features of the training data are reinforced by $\epsilon$-bounded perturbation. Further, we analyze the necessity of enlarging the defense budget to counter stability attacks. Finally, comprehensive experiments demonstrate that stability attacks are harmful on benchmark datasets, and thus the adaptive defense is necessary to maintain robustness.
On the Convergence and Robustness of Adversarial Training
Dec 15, 2021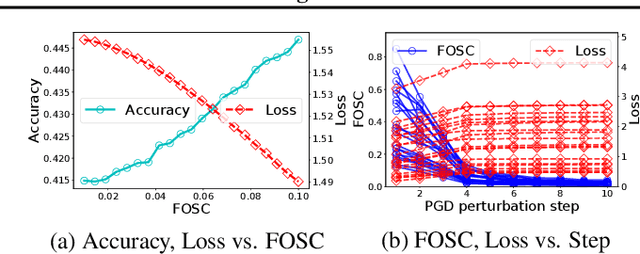

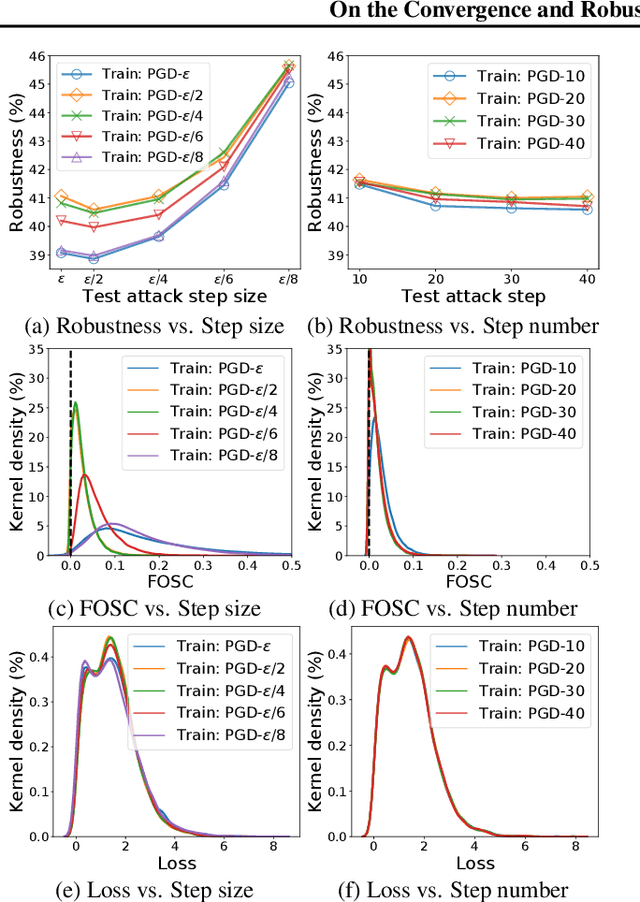

Improving the robustness of deep neural networks (DNNs) to adversarial examples is an important yet challenging problem for secure deep learning. Across existing defense techniques, adversarial training with Projected Gradient Decent (PGD) is amongst the most effective. Adversarial training solves a min-max optimization problem, with the \textit{inner maximization} generating adversarial examples by maximizing the classification loss, and the \textit{outer minimization} finding model parameters by minimizing the loss on adversarial examples generated from the inner maximization. A criterion that measures how well the inner maximization is solved is therefore crucial for adversarial training. In this paper, we propose such a criterion, namely First-Order Stationary Condition for constrained optimization (FOSC), to quantitatively evaluate the convergence quality of adversarial examples found in the inner maximization. With FOSC, we find that to ensure better robustness, it is essential to use adversarial examples with better convergence quality at the \textit{later stages} of training. Yet at the early stages, high convergence quality adversarial examples are not necessary and may even lead to poor robustness. Based on these observations, we propose a \textit{dynamic} training strategy to gradually increase the convergence quality of the generated adversarial examples, which significantly improves the robustness of adversarial training. Our theoretical and empirical results show the effectiveness of the proposed method.
Federated Two-stage Learning with Sign-based Voting
Dec 10, 2021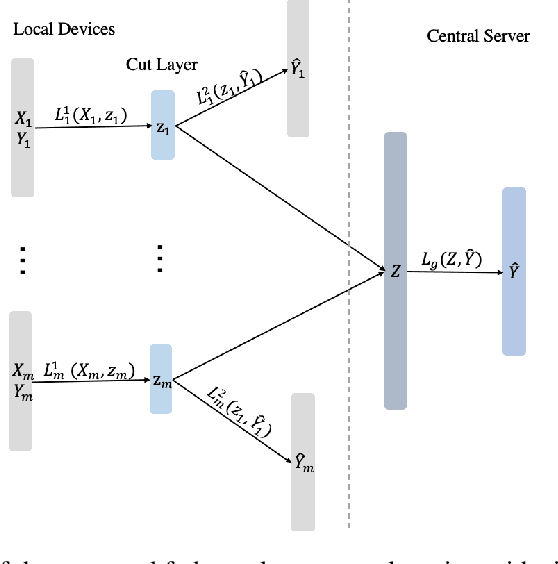
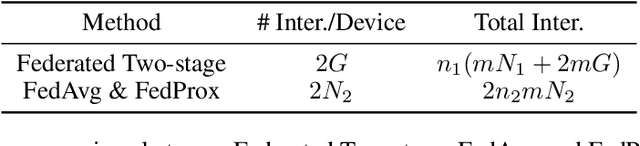
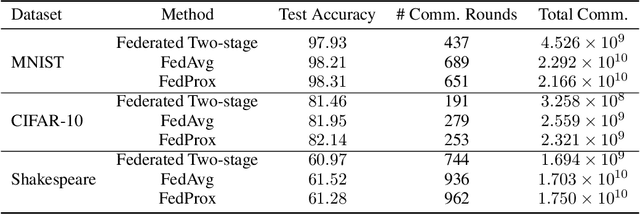
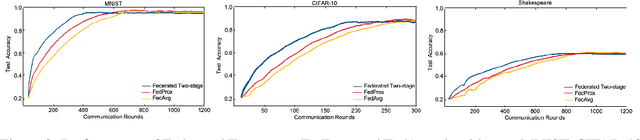
Federated learning is a distributed machine learning mechanism where local devices collaboratively train a shared global model under the orchestration of a central server, while keeping all private data decentralized. In the system, model parameters and its updates are transmitted instead of raw data, and thus the communication bottleneck has become a key challenge. Besides, recent larger and deeper machine learning models also pose more difficulties in deploying them in a federated environment. In this paper, we design a federated two-stage learning framework that augments prototypical federated learning with a cut layer on devices and uses sign-based stochastic gradient descent with the majority vote method on model updates. Cut layer on devices learns informative and low-dimension representations of raw data locally, which helps reduce global model parameters and prevents data leakage. Sign-based SGD with the majority vote method for model updates also helps alleviate communication limitations. Empirically, we show that our system is an efficient and privacy preserving federated learning scheme and suits for general application scenarios.
How and When Adversarial Robustness Transfers in Knowledge Distillation?
Oct 22, 2021
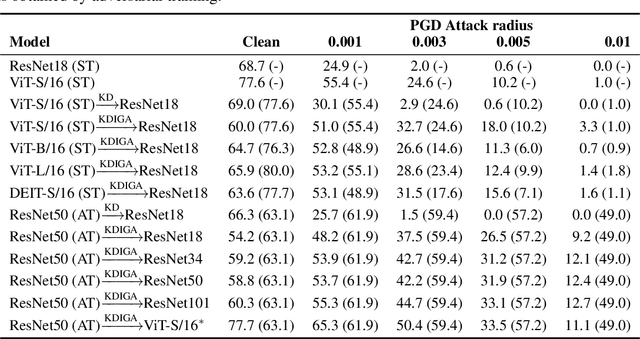
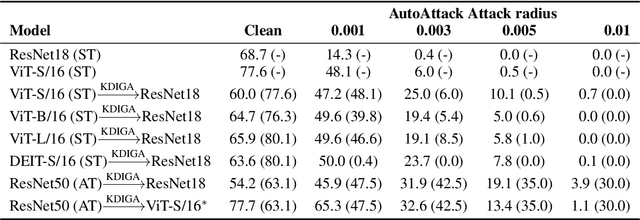
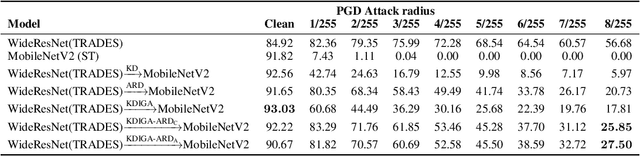
Knowledge distillation (KD) has been widely used in teacher-student training, with applications to model compression in resource-constrained deep learning. Current works mainly focus on preserving the accuracy of the teacher model. However, other important model properties, such as adversarial robustness, can be lost during distillation. This paper studies how and when the adversarial robustness can be transferred from a teacher model to a student model in KD. We show that standard KD training fails to preserve adversarial robustness, and we propose KD with input gradient alignment (KDIGA) for remedy. Under certain assumptions, we prove that the student model using our proposed KDIGA can achieve at least the same certified robustness as the teacher model. Our experiments of KD contain a diverse set of teacher and student models with varying network architectures and sizes evaluated on ImageNet and CIFAR-10 datasets, including residual neural networks (ResNets) and vision transformers (ViTs). Our comprehensive analysis shows several novel insights that (1) With KDIGA, students can preserve or even exceed the adversarial robustness of the teacher model, even when their models have fundamentally different architectures; (2) KDIGA enables robustness to transfer to pre-trained students, such as KD from an adversarially trained ResNet to a pre-trained ViT, without loss of clean accuracy; and (3) Our derived local linearity bounds for characterizing adversarial robustness in KD are consistent with the empirical results.
Adversarial Attack across Datasets
Oct 13, 2021
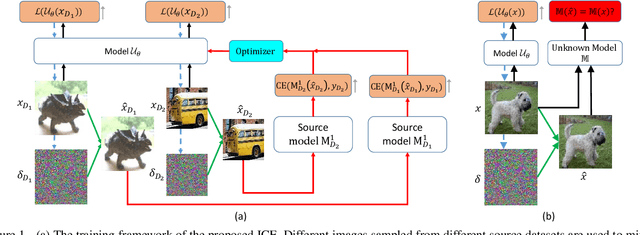
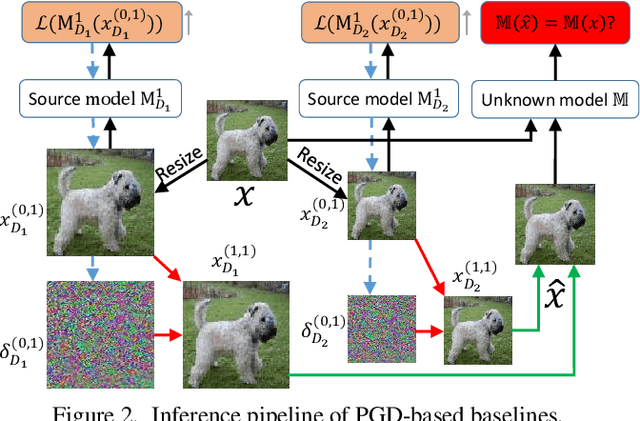
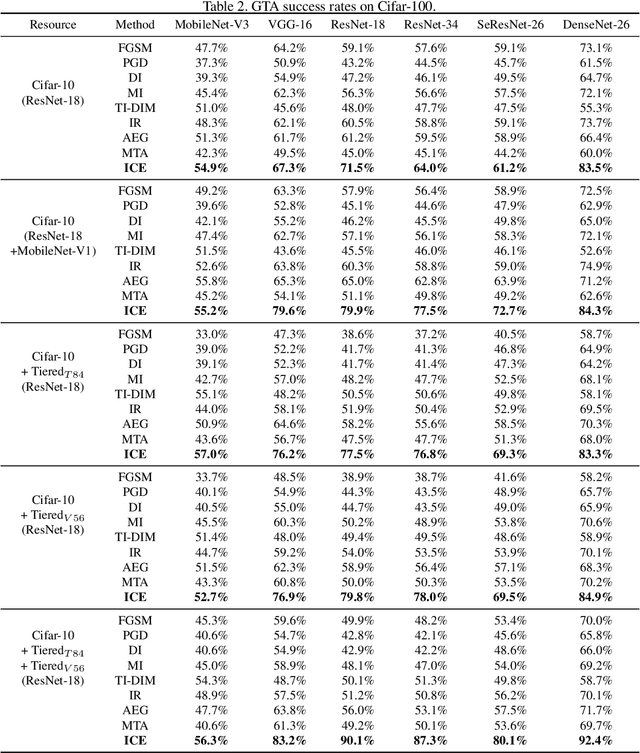
It has been observed that Deep Neural Networks (DNNs) are vulnerable to transfer attacks in the query-free black-box setting. However, all the previous studies on transfer attack assume that the white-box surrogate models possessed by the attacker and the black-box victim models are trained on the same dataset, which means the attacker implicitly knows the label set and the input size of the victim model. However, this assumption is usually unrealistic as the attacker may not know the dataset used by the victim model, and further, the attacker needs to attack any randomly encountered images that may not come from the same dataset. Therefore, in this paper we define a new Generalized Transferable Attack (GTA) problem where we assume the attacker has a set of surrogate models trained on different datasets (with different label sets and image sizes), and none of them is equal to the dataset used by the victim model. We then propose a novel method called Image Classification Eraser (ICE) to erase classification information for any encountered images from arbitrary dataset. Extensive experiments on Cifar-10, Cifar-100, and TieredImageNet demonstrate the effectiveness of the proposed ICE on the GTA problem. Furthermore, we show that existing transfer attack methods can be modified to tackle the GTA problem, but with significantly worse performance compared with ICE.
Trustworthy AI: From Principles to Practices
Oct 04, 2021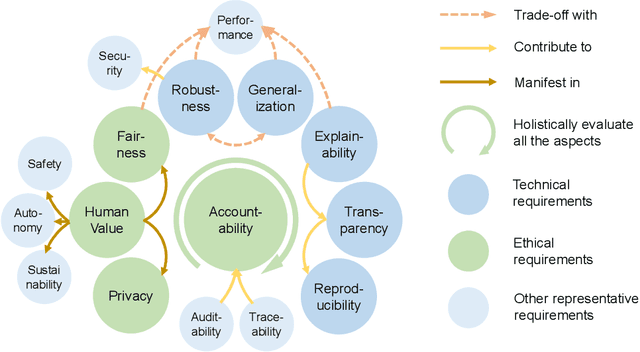
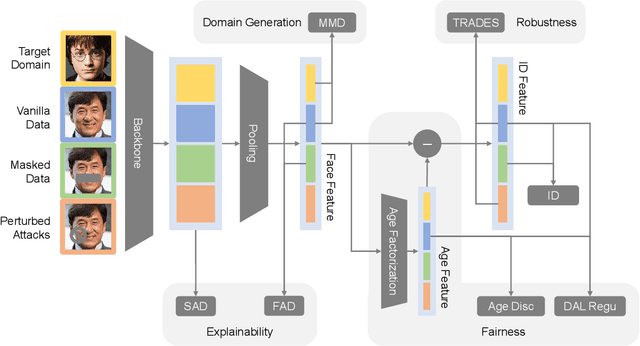
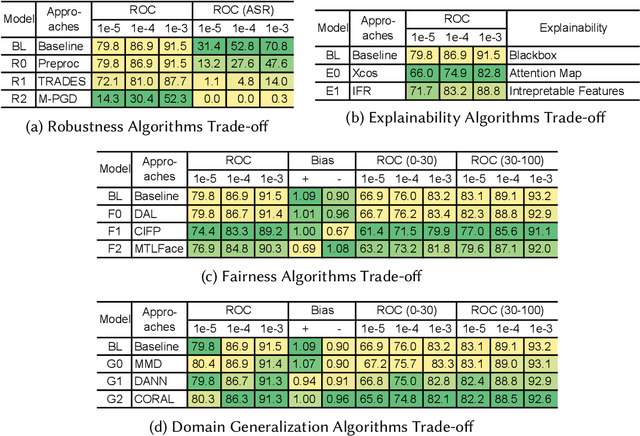
Fast developing artificial intelligence (AI) technology has enabled various applied systems deployed in the real world, impacting people's everyday lives. However, many current AI systems were found vulnerable to imperceptible attacks, biased against underrepresented groups, lacking in user privacy protection, etc., which not only degrades user experience but erodes the society's trust in all AI systems. In this review, we strive to provide AI practitioners a comprehensive guide towards building trustworthy AI systems. We first introduce the theoretical framework of important aspects of AI trustworthiness, including robustness, generalization, explainability, transparency, reproducibility, fairness, privacy preservation, alignment with human values, and accountability. We then survey leading approaches in these aspects in the industry. To unify the current fragmented approaches towards trustworthy AI, we propose a systematic approach that considers the entire lifecycle of AI systems, ranging from data acquisition to model development, to development and deployment, finally to continuous monitoring and governance. In this framework, we offer concrete action items to practitioners and societal stakeholders (e.g., researchers and regulators) to improve AI trustworthiness. Finally, we identify key opportunities and challenges in the future development of trustworthy AI systems, where we identify the need for paradigm shift towards comprehensive trustworthy AI systems.
Training Meta-Surrogate Model for Transferable Adversarial Attack
Sep 07, 2021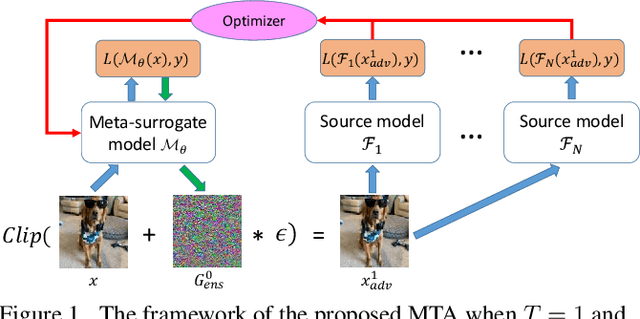
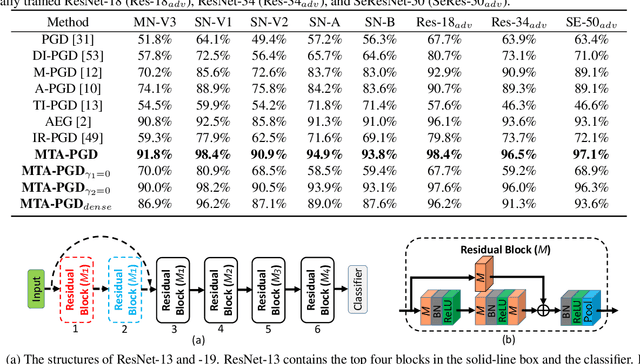
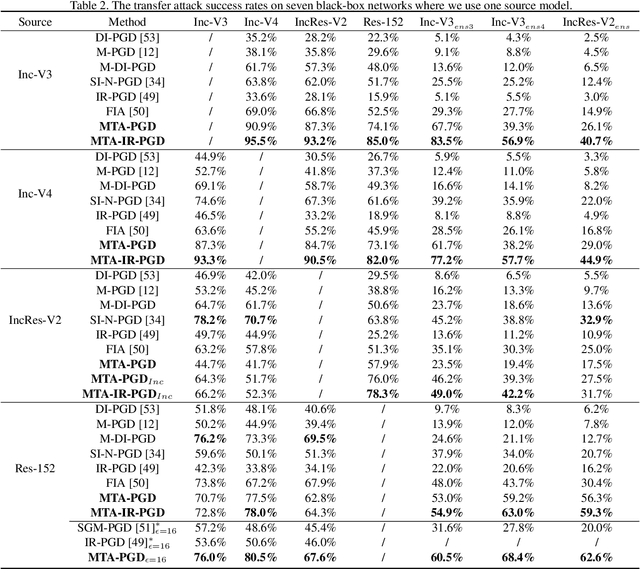
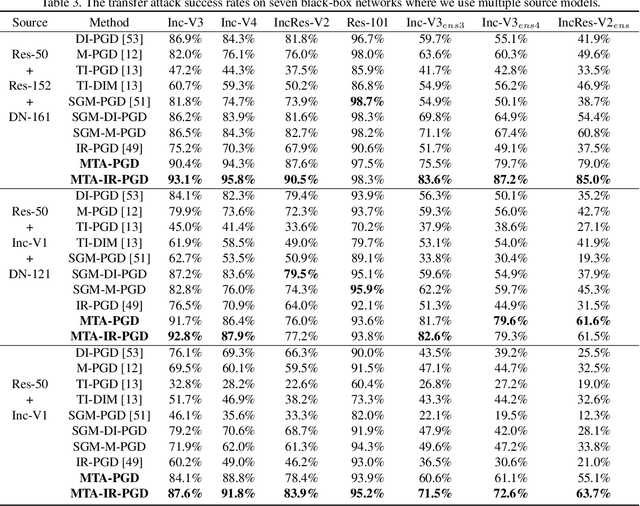
We consider adversarial attacks to a black-box model when no queries are allowed. In this setting, many methods directly attack surrogate models and transfer the obtained adversarial examples to fool the target model. Plenty of previous works investigated what kind of attacks to the surrogate model can generate more transferable adversarial examples, but their performances are still limited due to the mismatches between surrogate models and the target model. In this paper, we tackle this problem from a novel angle -- instead of using the original surrogate models, can we obtain a Meta-Surrogate Model (MSM) such that attacks to this model can be easier transferred to other models? We show that this goal can be mathematically formulated as a well-posed (bi-level-like) optimization problem and design a differentiable attacker to make training feasible. Given one or a set of surrogate models, our method can thus obtain an MSM such that adversarial examples generated on MSM enjoy eximious transferability. Comprehensive experiments on Cifar-10 and ImageNet demonstrate that by attacking the MSM, we can obtain stronger transferable adversarial examples to fool black-box models including adversarially trained ones, with much higher success rates than existing methods. The proposed method reveals significant security challenges of deep models and is promising to be served as a state-of-the-art benchmark for evaluating the robustness of deep models in the black-box setting.