 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow and When Adversarial Robustness Transfers in Knowledge Distillation?
Paper and Code
Oct 22, 2021
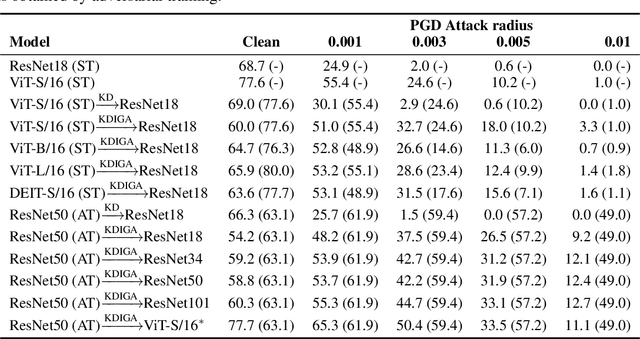
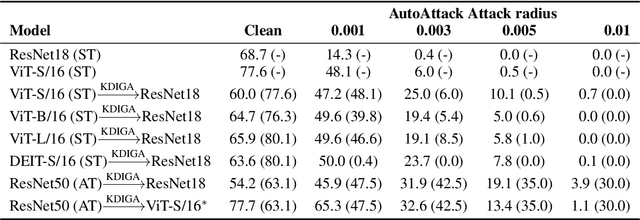
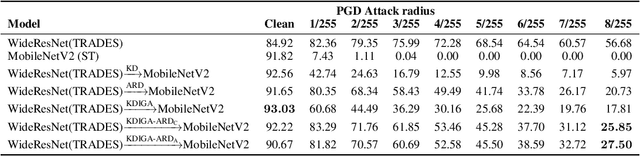
Knowledge distillation (KD) has been widely used in teacher-student training, with applications to model compression in resource-constrained deep learning. Current works mainly focus on preserving the accuracy of the teacher model. However, other important model properties, such as adversarial robustness, can be lost during distillation. This paper studies how and when the adversarial robustness can be transferred from a teacher model to a student model in KD. We show that standard KD training fails to preserve adversarial robustness, and we propose KD with input gradient alignment (KDIGA) for remedy. Under certain assumptions, we prove that the student model using our proposed KDIGA can achieve at least the same certified robustness as the teacher model. Our experiments of KD contain a diverse set of teacher and student models with varying network architectures and sizes evaluated on ImageNet and CIFAR-10 datasets, including residual neural networks (ResNets) and vision transformers (ViTs). Our comprehensive analysis shows several novel insights that (1) With KDIGA, students can preserve or even exceed the adversarial robustness of the teacher model, even when their models have fundamentally different architectures; (2) KDIGA enables robustness to transfer to pre-trained students, such as KD from an adversarially trained ResNet to a pre-trained ViT, without loss of clean accuracy; and (3) Our derived local linearity bounds for characterizing adversarial robustness in KD are consistent with the empirical results.