 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUGUST: an Automatic Generation Understudy for Synthesizing Conversational Recommendation Datasets
Jun 16, 2023



High-quality data is essential for conversational recommendation systems and serves as the cornerstone of the network architecture development and training strategy design. Existing works contribute heavy human efforts to manually labeling or designing and extending recommender dialogue templates. However, they suffer from (i) the limited number of human annotators results in that datasets can hardly capture rich and large-scale cases in the real world, (ii) the limited experience and knowledge of annotators account for the uninformative corpus and inappropriate recommendations. In this paper, we propose a novel automatic dataset synthesis approach that can generate both large-scale and high-quality recommendation dialogues through a data2text generation process, where unstructured recommendation conversations are generated from structured graphs based on user-item information from the real world. In doing so, we comprehensively exploit: (i) rich personalized user profiles from traditional recommendation datasets, (ii) rich external knowledge from knowledge graphs, and (iii) the conversation ability contained in human-to-human conversational recommendation datasets. Extensive experiments validate the benefit brought by the automatically synthesized data under low-resource scenarios and demonstrate the promising potential to facilitate the development of a more effective conversational recommendation system.
Personalizing or Not: Dynamically Personalized Federated Learning with Incentives
Aug 12, 2022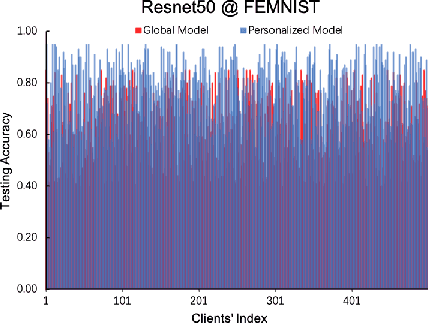
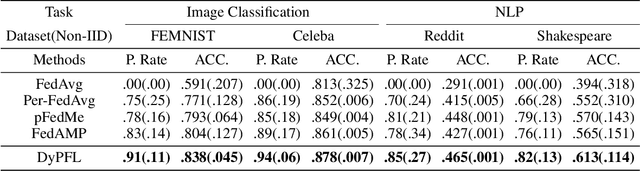
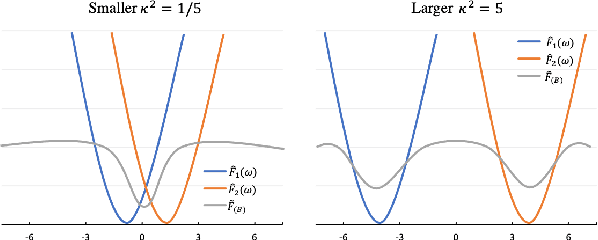
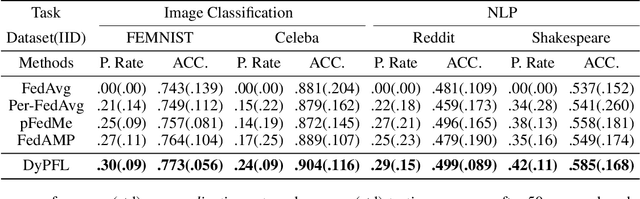
Personalized federated learning (FL) facilitates collaborations between multiple clients to learn personalized models without sharing private data. The mechanism mitigates the statistical heterogeneity commonly encountered in the system, i.e., non-IID data over different clients. Existing personalized algorithms generally assume all clients volunteer for personalization. However, potential participants might still be reluctant to personalize models since they might not work well. In this case, clients choose to use the global model instead. To avoid making unrealistic assumptions, we introduce the personalization rate, measured as the fraction of clients willing to train personalized models, into federated settings and propose DyPFL. This dynamically personalized FL technique incentivizes clients to participate in personalizing local models while allowing the adoption of the global model when it performs better. We show that the algorithmic pipeline in DyPFL guarantees good convergence performance, allowing it to outperform alternative personalized methods in a broad range of conditions, including variation in heterogeneity, number of clients, local epochs, and batch sizes.
Federated Two-stage Learning with Sign-based Voting
Dec 10, 2021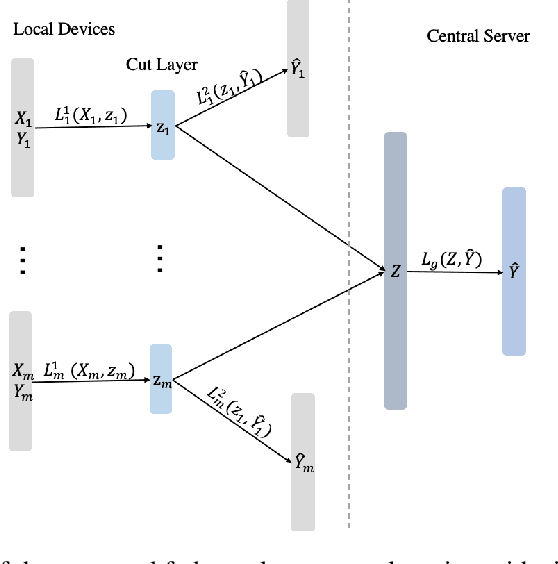
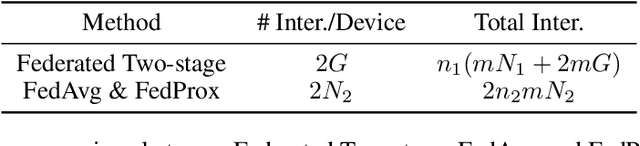
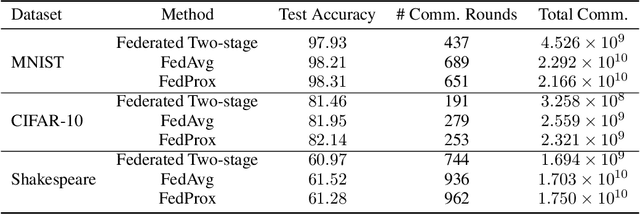
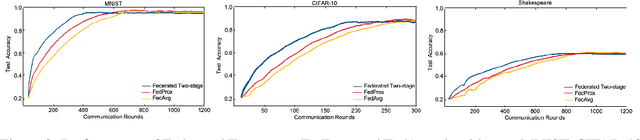
Federated learning is a distributed machine learning mechanism where local devices collaboratively train a shared global model under the orchestration of a central server, while keeping all private data decentralized. In the system, model parameters and its updates are transmitted instead of raw data, and thus the communication bottleneck has become a key challenge. Besides, recent larger and deeper machine learning models also pose more difficulties in deploying them in a federated environment. In this paper, we design a federated two-stage learning framework that augments prototypical federated learning with a cut layer on devices and uses sign-based stochastic gradient descent with the majority vote method on model updates. Cut layer on devices learns informative and low-dimension representations of raw data locally, which helps reduce global model parameters and prevents data leakage. Sign-based SGD with the majority vote method for model updates also helps alleviate communication limitations. Empirically, we show that our system is an efficient and privacy preserving federated learning scheme and suits for general application scenarios.
Towards Heterogeneous Clients with Elastic Federated Learning
Jun 17, 2021

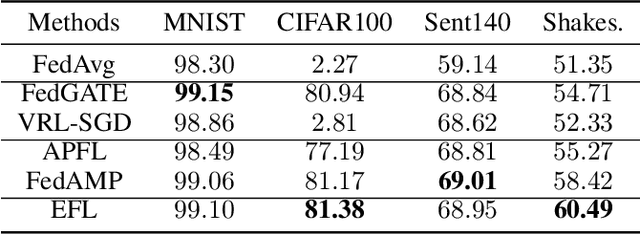

Federated learning involves training machine learning models over devices or data silos, such as edge processors or data warehouses, while keeping the data local. Training in heterogeneous and potentially massive networks introduces bias into the system, which is originated from the non-IID data and the low participation rate in reality. In this paper, we propose Elastic Federated Learning (EFL), an unbiased algorithm to tackle the heterogeneity in the system, which makes the most informative parameters less volatile during training, and utilizes the incomplete local updates. It is an efficient and effective algorithm that compresses both upstream and downstream communications. Theoretically, the algorithm has convergence guarantee when training on the non-IID data at the low participation rate. Empirical experiments corroborate the competitive performance of EFL framework on the robustness and the efficiency.
RevCore: Review-augmented Conversational Recommendation
Jun 02, 2021
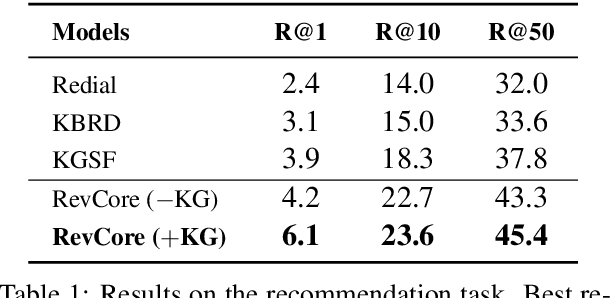
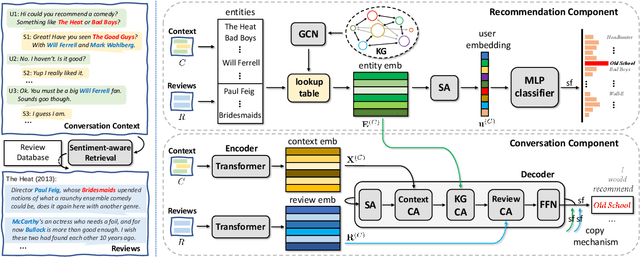
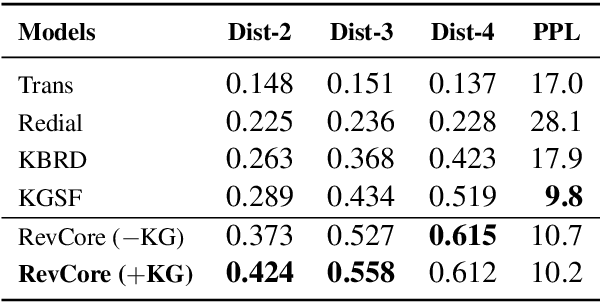
Existing conversational recommendation (CR) systems usually suffer from insufficient item information when conducted on short dialogue history and unfamiliar items. Incorporating external information (e.g., reviews) is a potential solution to alleviate this problem. Given that reviews often provide a rich and detailed user experience on different interests, they are potential ideal resources for providing high-quality recommendations within an informative conversation. In this paper, we design a novel end-to-end framework, namely, Review-augmented Conversational Recommender (RevCore), where reviews are seamlessly incorporated to enrich item information and assist in generating both coherent and informative responses. In detail, we extract sentiment-consistent reviews, perform review-enriched and entity-based recommendations for item suggestions, as well as use a review-attentive encoder-decoder for response generation. Experimental results demonstrate the superiority of our approach in yielding better performance on both recommendation and conversation responding.