 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Mirror Descent with Temporal Difference Learning: Sample Complexity under Online Markov Data
Dec 30, 2025This paper studies the policy mirror descent (PMD) method, which is a general policy optimization framework in reinforcement learning and can cover a wide range of policy gradient methods by specifying difference mirror maps. Existing sample complexity analysis for policy mirror descent either focuses on the generative sampling model, or the Markovian sampling model but with the action values being explicitly approximated to certain pre-specified accuracy. In contrast, we consider the sample complexity of policy mirror descent with temporal difference (TD) learning under the Markovian sampling model. Two algorithms called Expected TD-PMD and Approximate TD-PMD have been presented, which are off-policy and mixed policy algorithms respectively. Under a small enough constant policy update step size, the $\tilde{O}(\varepsilon^{-2})$ (a logarithm factor about $\varepsilon$ is hidden in $\tilde{O}(\cdot)$) sample complexity can be established for them to achieve average-time $\varepsilon$-optimality. The sample complexity is further improved to $O(\varepsilon^{-2})$ (without the hidden logarithm factor) to achieve the last-iterate $\varepsilon$-optimality based on adaptive policy update step sizes.
KAE: Kolmogorov-Arnold Auto-Encoder for Representation Learning
Dec 31, 2024



The Kolmogorov-Arnold Network (KAN) has recently gained attention as an alternative to traditional multi-layer perceptrons (MLPs), offering improved accuracy and interpretability by employing learnable activation functions on edges. In this paper, we introduce the Kolmogorov-Arnold Auto-Encoder (KAE), which integrates KAN with autoencoders (AEs) to enhance representation learning for retrieval, classification, and denoising tasks. Leveraging the flexible polynomial functions in KAN layers, KAE captures complex data patterns and non-linear relationships. Experiments on benchmark datasets demonstrate that KAE improves latent representation quality, reduces reconstruction errors, and achieves superior performance in downstream tasks such as retrieval, classification, and denoising, compared to standard autoencoders and other KAN variants. These results suggest KAE's potential as a useful tool for representation learning. Our code is available at \url{https://github.com/SciYu/KAE/}.
OpenTensor: Reproducing Faster Matrix Multiplication Discovering Algorithms
May 31, 2024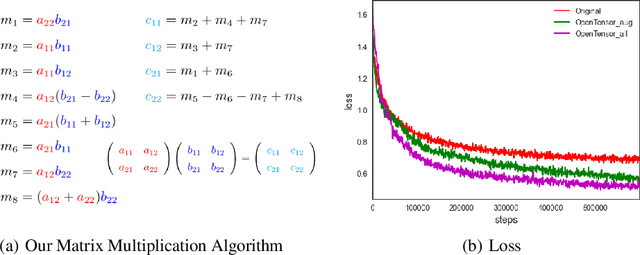
OpenTensor is a reproduction of AlphaTensor, which discovered a new algorithm that outperforms the state-of-the-art methods for matrix multiplication by Deep Reinforcement Learning (DRL). While AlphaTensor provides a promising framework for solving scientific problems, it is really hard to reproduce due to the massive tricks and lack of source codes. In this paper, we clean up the algorithm pipeline, clarify the technical details, and make some improvements to the training process. Computational results show that OpenTensor can successfully find efficient matrix multiplication algorithms.
Elementary Analysis of Policy Gradient Methods
Apr 11, 2024

Projected policy gradient under the simplex parameterization, policy gradient and natural policy gradient under the softmax parameterization, are fundamental algorithms in reinforcement learning. There have been a flurry of recent activities in studying these algorithms from the theoretical aspect. Despite this, their convergence behavior is still not fully understood, even given the access to exact policy evaluations. In this paper, we focus on the discounted MDP setting and conduct a systematic study of the aforementioned policy optimization methods. Several novel results are presented, including 1) global linear convergence of projected policy gradient for any constant step size, 2) sublinear convergence of softmax policy gradient for any constant step size, 3) global linear convergence of softmax natural policy gradient for any constant step size, 4) global linear convergence of entropy regularized softmax policy gradient for a wider range of constant step sizes than existing result, 5) tight local linear convergence rate of entropy regularized natural policy gradient, and 6) a new and concise local quadratic convergence rate of soft policy iteration without the assumption on the stationary distribution under the optimal policy. New and elementary analysis techniques have been developed to establish these results.
S-NeRF++: Autonomous Driving Simulation via Neural Reconstruction and Generation
Feb 03, 2024



Autonomous driving simulation system plays a crucial role in enhancing self-driving data and simulating complex and rare traffic scenarios, ensuring navigation safety. However, traditional simulation systems, which often heavily rely on manual modeling and 2D image editing, struggled with scaling to extensive scenes and generating realistic simulation data. In this study, we present S-NeRF++, an innovative autonomous driving simulation system based on neural reconstruction. Trained on widely-used self-driving datasets such as nuScenes and Waymo, S-NeRF++ can generate a large number of realistic street scenes and foreground objects with high rendering quality as well as offering considerable flexibility in manipulation and simulation. Specifically, S-NeRF++ is an enhanced neural radiance field for synthesizing large-scale scenes and moving vehicles, with improved scene parameterization and camera pose learning. The system effectively utilizes noisy and sparse LiDAR data to refine training and address depth outliers, ensuring high quality reconstruction and novel-view rendering. It also provides a diverse foreground asset bank through reconstructing and generating different foreground vehicles to support comprehensive scenario creation. Moreover, we have developed an advanced foreground-background fusion pipeline that skillfully integrates illumination and shadow effects, further enhancing the realism of our simulations. With the high-quality simulated data provided by our S-NeRF++, we found the perception methods enjoy performance boost on several autonomous driving downstream tasks, which further demonstrate the effectiveness of our proposed simulator.
S-NeRF: Neural Radiance Fields for Street Views
Mar 01, 2023



Neural Radiance Fields (NeRFs) aim to synthesize novel views of objects and scenes, given the object-centric camera views with large overlaps. However, we conjugate that this paradigm does not fit the nature of the street views that are collected by many self-driving cars from the large-scale unbounded scenes. Also, the onboard cameras perceive scenes without much overlapping. Thus, existing NeRFs often produce blurs, 'floaters' and other artifacts on street-view synthesis. In this paper, we propose a new street-view NeRF (S-NeRF) that considers novel view synthesis of both the large-scale background scenes and the foreground moving vehicles jointly. Specifically, we improve the scene parameterization function and the camera poses for learning better neural representations from street views. We also use the the noisy and sparse LiDAR points to boost the training and learn a robust geometry and reprojection based confidence to address the depth outliers. Moreover, we extend our S-NeRF for reconstructing moving vehicles that is impracticable for conventional NeRFs. Thorough experiments on the large-scale driving datasets (e.g., nuScenes and Waymo) demonstrate that our method beats the state-of-the-art rivals by reducing 7% to 40% of the mean-squared error in the street-view synthesis and a 45% PSNR gain for the moving vehicles rendering.
MoNET: Tackle State Momentum via Noise-Enhanced Training for Dialogue State Tracking
Nov 11, 2022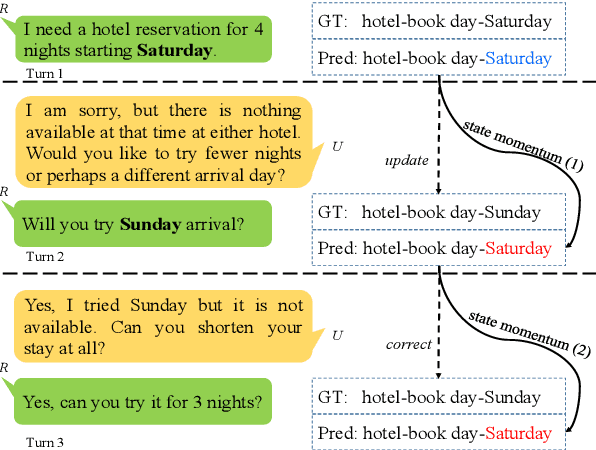
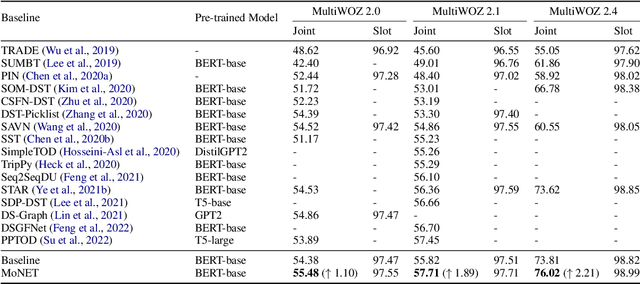
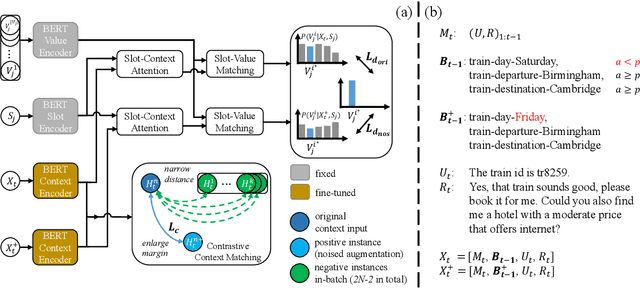
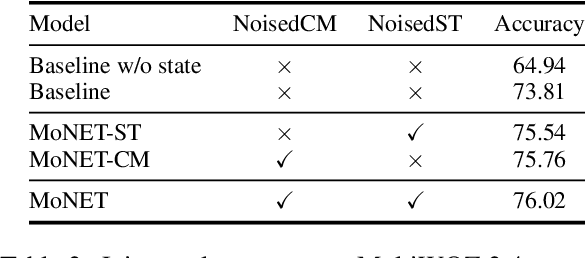
Dialogue state tracking (DST) aims to convert the dialogue history into dialogue states which consist of slot-value pairs. As condensed structural information memorizing all history information, the dialogue state in the last turn is typically adopted as the input for predicting the current state by DST models. However, these models tend to keep the predicted slot values unchanged, which is defined as state momentum in this paper. Specifically, the models struggle to update slot values that need to be changed and correct wrongly predicted slot values in the last turn. To this end, we propose MoNET to tackle state momentum via noise-enhanced training. First, the previous state of each turn in the training data is noised via replacing some of its slot values. Then, the noised previous state is used as the input to learn to predict the current state, improving the model's ability to update and correct slot values. Furthermore, a contrastive context matching framework is designed to narrow the representation distance between a state and its corresponding noised variant, which reduces the impact of noised state and makes the model better understand the dialogue history. Experimental results on MultiWOZ datasets show that MoNET outperforms previous DST methods. Ablations and analysis verify the effectiveness of MoNET in alleviating state momentum and improving anti-noise ability.
CSS: Combining Self-training and Self-supervised Learning for Few-shot Dialogue State Tracking
Oct 11, 2022
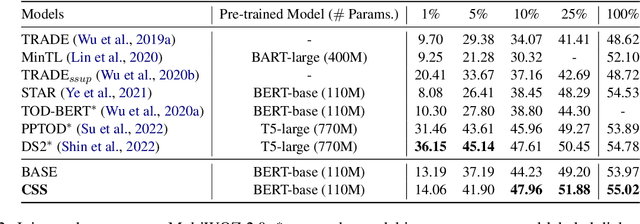
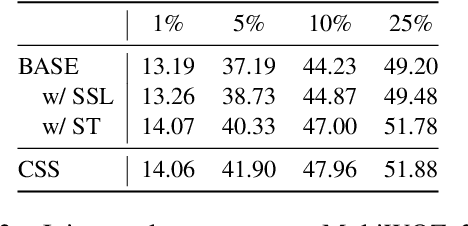
Few-shot dialogue state tracking (DST) is a realistic problem that trains the DST model with limited labeled data. Existing few-shot methods mainly transfer knowledge learned from external labeled dialogue data (e.g., from question answering, dialogue summarization, machine reading comprehension tasks, etc.) into DST, whereas collecting a large amount of external labeled data is laborious, and the external data may not effectively contribute to the DST-specific task. In this paper, we propose a few-shot DST framework called CSS, which Combines Self-training and Self-supervised learning methods. The unlabeled data of the DST task is incorporated into the self-training iterations, where the pseudo labels are predicted by a DST model trained on limited labeled data in advance. Besides, a contrastive self-supervised method is used to learn better representations, where the data is augmented by the dropout operation to train the model. Experimental results on the MultiWOZ dataset show that our proposed CSS achieves competitive performance in several few-shot scenarios.
Personalizing or Not: Dynamically Personalized Federated Learning with Incentives
Aug 12, 2022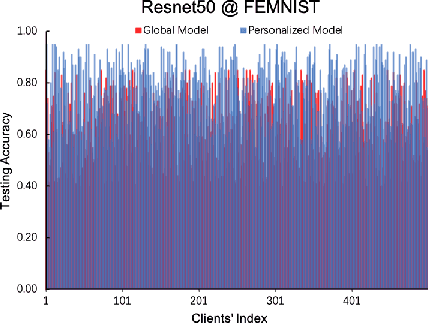
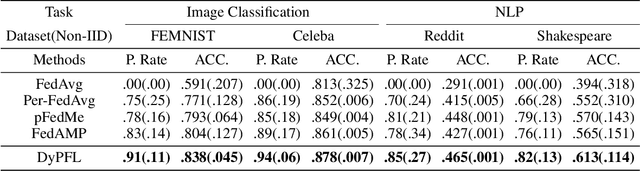
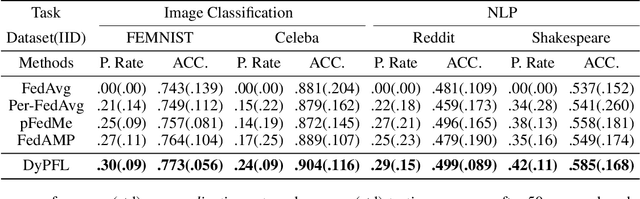
Personalized federated learning (FL) facilitates collaborations between multiple clients to learn personalized models without sharing private data. The mechanism mitigates the statistical heterogeneity commonly encountered in the system, i.e., non-IID data over different clients. Existing personalized algorithms generally assume all clients volunteer for personalization. However, potential participants might still be reluctant to personalize models since they might not work well. In this case, clients choose to use the global model instead. To avoid making unrealistic assumptions, we introduce the personalization rate, measured as the fraction of clients willing to train personalized models, into federated settings and propose DyPFL. This dynamically personalized FL technique incentivizes clients to participate in personalizing local models while allowing the adoption of the global model when it performs better. We show that the algorithmic pipeline in DyPFL guarantees good convergence performance, allowing it to outperform alternative personalized methods in a broad range of conditions, including variation in heterogeneity, number of clients, local epochs, and batch sizes.
POViT: Vision Transformer for Multi-objective Design and Characterization of Nanophotonic Devices
May 17, 2022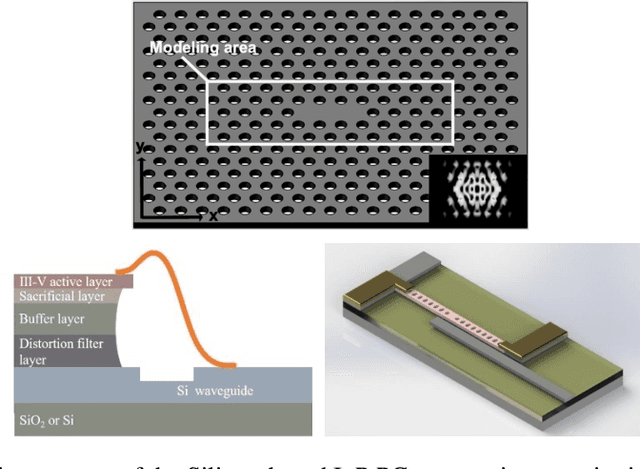
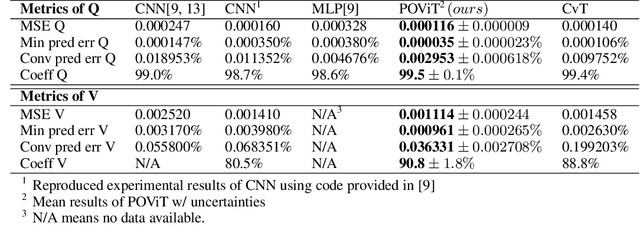
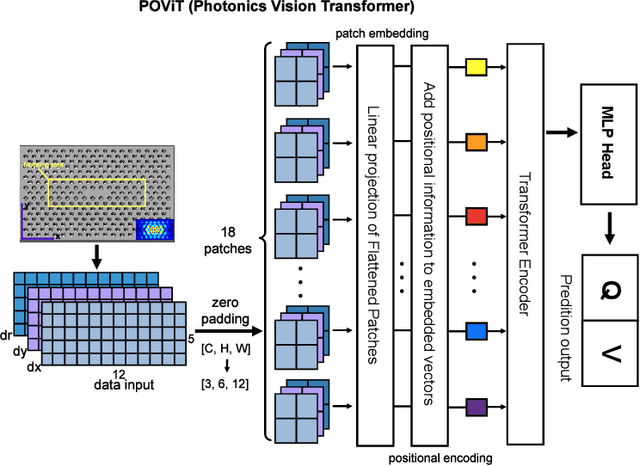
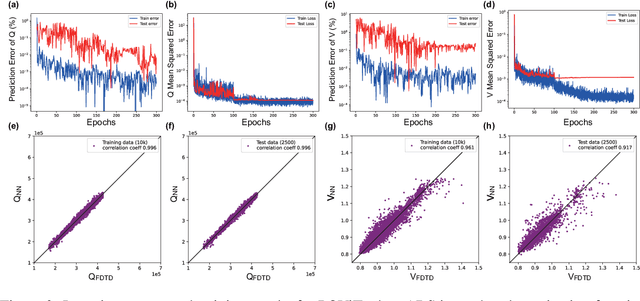
We solve a fundamental challenge in semiconductor IC design: the fast and accurate characterization of nanoscale photonic devices. Much like the fusion between AI and EDA, many efforts have been made to apply DNNs such as convolutional neural networks (CNN) to prototype and characterize next-gen optoelectronic devices commonly found in photonic integrated circuits (PIC) and LiDAR. These prior works generally strive to predict the quality factor (Q) and modal volume (V) of for instance, photonic crystals, with ultra-high accuracy and speed. However, state-of-the-art models are still far from being directly applicable in the real-world: e.g. the correlation coefficient of V ($V_{coeff}$ ) is only about 80%, which is much lower than what it takes to generate reliable and reproducible nanophotonic designs. Recently, attention-based transformer models have attracted extensive interests and been widely used in CV and NLP. In this work, we propose the first-ever Transformer model (POViT) to efficiently design and simulate semiconductor photonic devices with multiple objectives. Unlike the standard Vision Transformer (ViT), we supplied photonic crystals as data input and changed the activation layer from GELU to an absolute-value function (ABS). Our experiments show that POViT exceeds results reported by previous models significantly. The correlation coefficient $V_{coeff}$ increases by over 12% (i.e., to 92.0%) and the prediction errors of Q is reduced by an order of magnitude, among several other key metric improvements. Our work has the potential to drive the expansion of EDA to fully automated photonic design. The complete dataset and code will be released to aid researchers endeavoring in the interdisciplinary field of physics and computer science.