 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimGym: A Framework for A/B Test Simulation in E-Commerce with Traffic-Grounded VLM Agents
May 19, 2026A/B testing remains the gold standard for evaluating modifications to e-commerce storefronts, yet it diverts traffic, requires weeks to reach statistical significance, and risks degrading user experience. We present SimGym, a framework for simulating A/B tests on e-commerce storefronts using vision-language model (VLM) agents operating in a live browser. The framework comprises three key components: (a) a traffic-grounded persona generation pipeline that derives per-shop buyer archetypes and intents from production clickstream data; (b) a live-browser agent architecture that combines multimodal perception over visual and browser-structured observations with episodic memory and guardrails to conduct coherent shopping sessions across control and treatment storefronts; and (c) an evaluation protocol that compares simulated outcome shifts with observed shifts in real buyer behavior. We validate SimGym on A/B tests of visually driven UI theme changes from a major e-commerce platform across diverse storefronts and product categories. Empirical results show that SimGym agents achieve strong agreement with observed outcome shifts, attaining 77% directional alignment with add-to-cart shifts observed across interface variants in real-buyer traffic. It reduces experimental cycles from weeks to under an hour, enabling rapid experimentation without exposing real buyers to candidate variants.
SimGym: Traffic-Grounded Browser Agents for Offline A/B Testing in E-Commerce
Feb 01, 2026A/B testing remains the gold standard for evaluating e-commerce UI changes, yet it diverts traffic, takes weeks to reach significance, and risks harming user experience. We introduce SimGym, a scalable system for rapid offline A/B testing using traffic-grounded synthetic buyers powered by Large Language Model agents operating in a live browser. SimGym extracts per-shop buyer profiles and intents from production interaction data, identifies distinct behavioral archetypes, and simulates cohort-weighted sessions across control and treatment storefronts. We validate SimGym against real human outcomes from real UI changes on a major e-commerce platform under confounder control. Even without alignment post training, SimGym agents achieve state of the art alignment with observed outcome shifts and reduces experiment cycles from weeks to under an hour , enabling rapid experimentation without exposure to real buyers.
Deep Neural Operator Learning for Probabilistic Models
Nov 10, 2025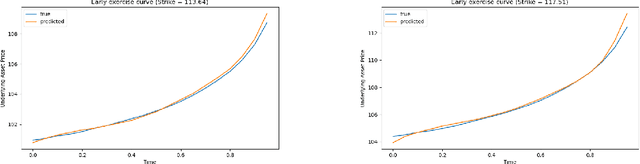
We propose a deep neural-operator framework for a general class of probability models. Under global Lipschitz conditions on the operator over the entire Euclidean space-and for a broad class of probabilistic models-we establish a universal approximation theorem with explicit network-size bounds for the proposed architecture. The underlying stochastic processes are required only to satisfy integrability and general tail-probability conditions. We verify these assumptions for both European and American option-pricing problems within the forward-backward SDE (FBSDE) framework, which in turn covers a broad class of operators arising from parabolic PDEs, with or without free boundaries. Finally, we present a numerical example for a basket of American options, demonstrating that the learned model produces optimal stopping boundaries for new strike prices without retraining.
Knowledge Graph-Based Explainable and Generalized Zero-Shot Semantic Communications
Jul 03, 2025Data-driven semantic communication is based on superficial statistical patterns, thereby lacking interpretability and generalization, especially for applications with the presence of unseen data. To address these challenges, we propose a novel knowledge graph-enhanced zero-shot semantic communication (KGZS-SC) network. Guided by the structured semantic information from a knowledge graph-based semantic knowledge base (KG-SKB), our scheme provides generalized semantic representations and enables reasoning for unseen cases. Specifically, the KG-SKB aligns the semantic features in a shared category semantics embedding space and enhances the generalization ability of the transmitter through aligned semantic features, thus reducing communication overhead by selectively transmitting compact visual semantics. At the receiver, zero-shot learning (ZSL) is leveraged to enable direct classification for unseen cases without the demand for retraining or additional computational overhead, thereby enhancing the adaptability and efficiency of the classification process in dynamic or resource-constrained environments. The simulation results conducted on the APY datasets show that the proposed KGZS-SC network exhibits robust generalization and significantly outperforms existing SC frameworks in classifying unseen categories across a range of SNR levels.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
What Is Next for LLMs? Next-Generation AI Computing Hardware Using Photonic Chips
May 09, 2025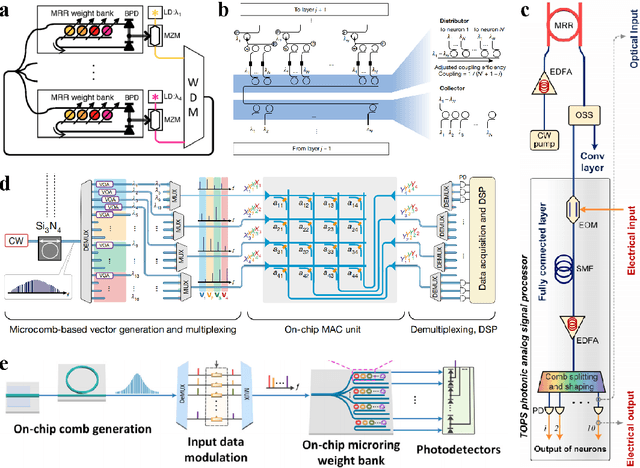
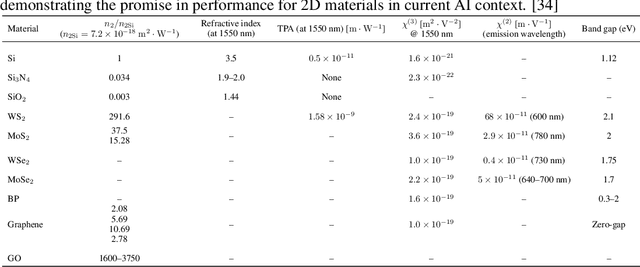
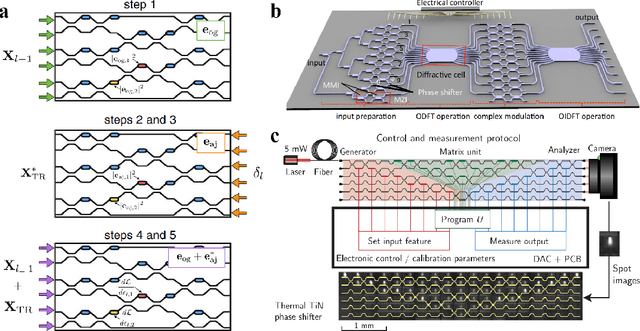
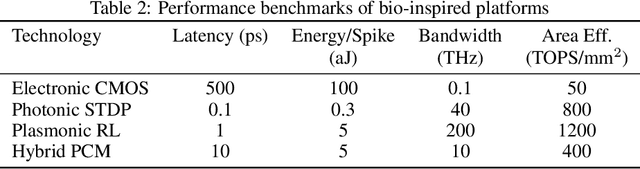
Large language models (LLMs) are rapidly pushing the limits of contemporary computing hardware. For example, training GPT-3 has been estimated to consume around 1300 MWh of electricity, and projections suggest future models may require city-scale (gigawatt) power budgets. These demands motivate exploration of computing paradigms beyond conventional von Neumann architectures. This review surveys emerging photonic hardware optimized for next-generation generative AI computing. We discuss integrated photonic neural network architectures (e.g., Mach-Zehnder interferometer meshes, lasers, wavelength-multiplexed microring resonators) that perform ultrafast matrix operations. We also examine promising alternative neuromorphic devices, including spiking neural network circuits and hybrid spintronic-photonic synapses, which combine memory and processing. The integration of two-dimensional materials (graphene, TMDCs) into silicon photonic platforms is reviewed for tunable modulators and on-chip synaptic elements. Transformer-based LLM architectures (self-attention and feed-forward layers) are analyzed in this context, identifying strategies and challenges for mapping dynamic matrix multiplications onto these novel hardware substrates. We then dissect the mechanisms of mainstream LLMs, such as ChatGPT, DeepSeek, and LLaMA, highlighting their architectural similarities and differences. We synthesize state-of-the-art components, algorithms, and integration methods, highlighting key advances and open issues in scaling such systems to mega-sized LLM models. We find that photonic computing systems could potentially surpass electronic processors by orders of magnitude in throughput and energy efficiency, but require breakthroughs in memory, especially for long-context windows and long token sequences, and in storage of ultra-large datasets.
Inverse Design of Photonic Crystal Surface Emitting Lasers is a Sequence Modeling Problem
Mar 08, 2024



Photonic Crystal Surface Emitting Lasers (PCSEL)'s inverse design demands expert knowledge in physics, materials science, and quantum mechanics which is prohibitively labor-intensive. Advanced AI technologies, especially reinforcement learning (RL), have emerged as a powerful tool to augment and accelerate this inverse design process. By modeling the inverse design of PCSEL as a sequential decision-making problem, RL approaches can construct a satisfactory PCSEL structure from scratch. However, the data inefficiency resulting from online interactions with precise and expensive simulation environments impedes the broader applicability of RL approaches. Recently, sequential models, especially the Transformer architecture, have exhibited compelling performance in sequential decision-making problems due to their simplicity and scalability to large language models. In this paper, we introduce a novel framework named PCSEL Inverse Design Transformer (PiT) that abstracts the inverse design of PCSEL as a sequence modeling problem. The central part of our PiT is a Transformer-based structure that leverages the past trajectories and current states to predict the current actions. Compared with the traditional RL approaches, PiT can output the optimal actions and achieve target PCSEL designs by leveraging offline data and conditioning on the desired return. Results demonstrate that PiT achieves superior performance and data efficiency compared to baselines.
Spatio-temporal Prompting Network for Robust Video Feature Extraction
Feb 04, 2024Frame quality deterioration is one of the main challenges in the field of video understanding. To compensate for the information loss caused by deteriorated frames, recent approaches exploit transformer-based integration modules to obtain spatio-temporal information. However, these integration modules are heavy and complex. Furthermore, each integration module is specifically tailored for its target task, making it difficult to generalise to multiple tasks. In this paper, we present a neat and unified framework, called Spatio-Temporal Prompting Network (STPN). It can efficiently extract robust and accurate video features by dynamically adjusting the input features in the backbone network. Specifically, STPN predicts several video prompts containing spatio-temporal information of neighbour frames. Then, these video prompts are prepended to the patch embeddings of the current frame as the updated input for video feature extraction. Moreover, STPN is easy to generalise to various video tasks because it does not contain task-specific modules. Without bells and whistles, STPN achieves state-of-the-art performance on three widely-used datasets for different video understanding tasks, i.e., ImageNetVID for video object detection, YouTubeVIS for video instance segmentation, and GOT-10k for visual object tracking. Code is available at https://github.com/guanxiongsun/vfe.pytorch.
Induced Generative Adversarial Particle Transformers
Dec 08, 2023In high energy physics (HEP), machine learning methods have emerged as an effective way to accurately simulate particle collisions at the Large Hadron Collider (LHC). The message-passing generative adversarial network (MPGAN) was the first model to simulate collisions as point, or ``particle'', clouds, with state-of-the-art results, but suffered from quadratic time complexity. Recently, generative adversarial particle transformers (GAPTs) were introduced to address this drawback; however, results did not surpass MPGAN. We introduce induced GAPT (iGAPT) which, by integrating ``induced particle-attention blocks'' and conditioning on global jet attributes, not only offers linear time complexity but is also able to capture intricate jet substructure, surpassing MPGAN in many metrics. Our experiments demonstrate the potential of iGAPT to simulate complex HEP data accurately and efficiently.
Deep Signature Algorithm for Path-Dependent American option pricing
Nov 21, 2022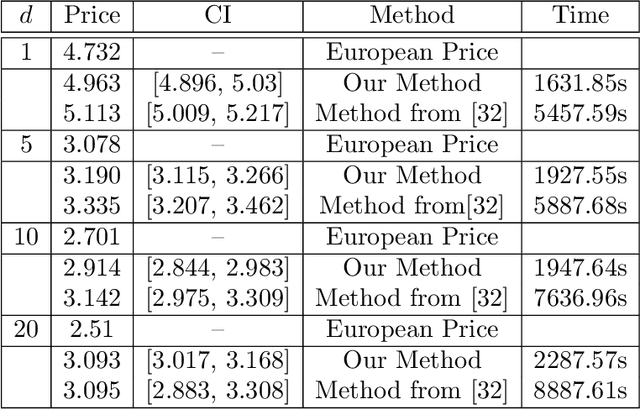
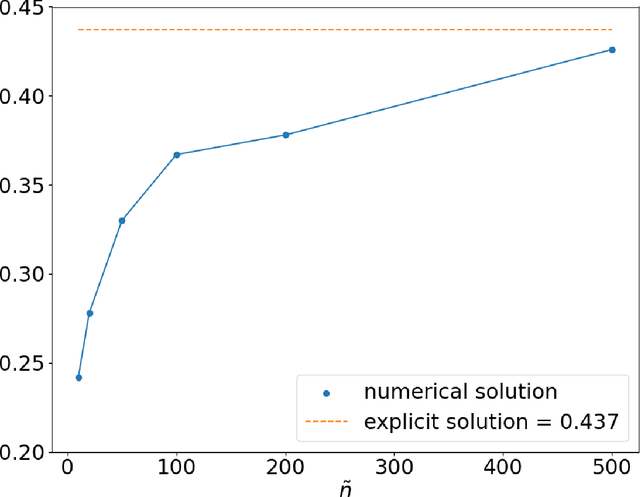
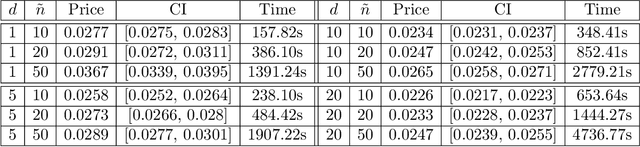
In this work, we study the deep signature algorithms for path-dependent FBSDEs with reflections. We follow the backward scheme in [Hur\'e-Pham-Warin. Mathematics of Computation 89, no. 324 (2020)] for state-dependent FBSDEs with reflections, and combine it with the signature layer to solve American type option pricing problems while the payoff function depends on the whole paths of the underlying forward stock process. We prove the convergence analysis of our numerical algorithm and provide numerical example for Amerasian option under the Black-Scholes model.