 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion Seeding via Pre-Activation Regularization: A Geometric View from Piecewise Affine Nerual Networks
May 07, 2026Deep networks with continuous piecewise affine activations induce polyhedral partitions of the input space, making the number of realized affine regions a natural measure of expressive capacity and a key determinant of how well the model can approximate nonlinear target functions. In practice, standard training realizes far fewer region refinements in data-visited neighborhoods than the architecture could in principle support, while existing region-count theory is primarily architectural and offers little guidance on how optimization shapes the realized partition near the data. Our theory provides a sufficient condition under which bringing neuron switching surfaces sufficiently close to data points ensures their intersection with local neighborhoods, which in turn implies a strict increase in the local affine-region count, yielding a principled training-time handle for seeding data-relevant partitions early in optimization. Guided by these results, we propose a plug-and-play region-seeding regularizer that encourages early partitioning while allowing task-driven refinement to dominate later in training. Experiments show that the regularizer increases the number of realized affine regions via exact enumeration and improves overall performance on toy datasets, while also improving early-stage accuracy and achieving comparable (or slightly improved) final accuracy on ImageNet-1k for classical models.
AffineLens: Capturing the Continuous Piecewise Affine Functions of Neural Networks
May 07, 2026Piecewise affine neural networks (PANNs) provide a principled geometric perspective on neural network expressivity by characterizing the input--output map as a continuous piecewise affine (CPA) function whose complexity is governed by the number, arrangement, and shapes of its affine regions. However, existing interpretability and expressivity analyses often rely on indirect proxies (e.g., activation statistics or theoretical upper bounds) and rarely offer practical, accurate tools for enumerating and visualizing the induced region partition under realistic architectures and bounded input domains. In this work, we present AffineLens, a unified framework for computing the hyperplane arrangements and polyhedral structures underlying PANNs. Given a calibrated (bounded) input polytope, AffineLens identifies the subset of neuron-induced hyperplanes that intersect the domain, enumerates the resulting affine sub-regions in a layer-wise manner, and returns provably non-empty maximal CPA regions together with interior representatives. The framework further provides visualizations of region partitioning and decision boundaries, enabling qualitative inspection alongside quantitative region counts. By exploiting the affine restriction property of CPA networks under fixed activation patterns, AffineLens supports a broad class of modern components, including batch normalization, pooling, residual connections, multilayer perceptrons, and convolutional layers. Finally, we use AffineLens to perform a systematic empirical study of architectural expressivity, comparing networks through region complexity metrics and revealing how design choices influence the geometry of learned functions.
Training-Time Batch Normalization Reshapes Local Partition Geometry in Piecewise-Affine Networks
May 06, 2026Batch normalization (BN) is central to modern deep networks, but its effect on the realized function during training remains less understood than its optimization benefits. We study training-time BN in continuous piecewise-affine (CPA) networks through the geometry of switching hyperplanes and the induced affine-region partition. Conditioned on a mini-batch, we show that BN defines for each neuron a reference hyperplane through the batch centroid, and that breakpoint-switching hyperplanes are parallel translates whose offsets are expressed in batch-standardized coordinates and are independent of the raw bias. This yields an exact criterion for when a switching hyperplane intersects a local $\ell_\infty$ window and motivates a local region-density functional based on exact affine-region counts. Under explicit sufficient conditions, we show that BN increases expected local partition refinement in ReLU and more general piecewise-affine networks, and that this mechanism transfers locally through depth inside parent affine regions where the upstream representation map is an affine embedding. These results provide a function-level geometric account of training-time BN as a batch-conditional recentering mechanism near the data.
Brief Is Better: Non-Monotonic Chain-of-Thought Budget Effects in Function-Calling Language Agents
Apr 02, 2026How much should a language agent think before taking action? Chain-of-thought (CoT) reasoning is widely assumed to improve agent performance, but the relationship between reasoning length and accuracy in structured tool-use settings remains poorly understood. We present a systematic study of CoT budget effects on function-calling agents, sweeping six token budgets (0--512) across 200 tasks from the Berkeley Function Calling Leaderboard v3 Multiple benchmark. Our central finding is a striking non-monotonic pattern on Qwen2.5-1.5B-Instruct: brief reasoning (32 tokens) dramatically improves accuracy by 45% relative over direct answers, from 44.0% to 64.0%, while extended reasoning (256 tokens) degrades performance well below the no-CoT baseline, to 25.0% (McNemar p < 0.001). A three-way error decomposition reveals the mechanism. At d = 0, 30.5% of tasks fail because the model selects the wrong function from the candidate set; brief CoT reduces this to 1.5%, effectively acting as a function-routing step, while long CoT reverses the gain, yielding 28.0% wrong selections and 18.0% hallucinated functions at d = 256. Oracle analysis shows that 88.6% of solvable tasks require at most 32 reasoning tokens, with an average of 27.6 tokens, and a finer-grained sweep indicates that the true optimum lies at 8--16 tokens. Motivated by this routing effect, we propose Function-Routing CoT (FR-CoT), a structured brief-CoT method that templates the reasoning phase as "Function: [name] / Key args: [...]," forcing commitment to a valid function name at the start of reasoning. FR-CoT achieves accuracy statistically equivalent to free-form d = 32 CoT while reducing function hallucination to 0.0%, providing a structural reliability guarantee without budget tuning.
DataProphet: Demystifying Supervision Data Generalization in Multimodal LLMs
Mar 20, 2026Conventional wisdom for selecting supervision data for multimodal large language models (MLLMs) is to prioritize datasets that appear similar to the target benchmark, such as text-intensive or vision-centric tasks. However, it remains unclear whether such intuitive similarity reliably predicts downstream performance gains. In this work, we take a first step toward answering a practical question: can we estimate the influence of a training dataset on a target benchmark before any training is performed? To investigate this question, we conduct an in-depth analysis of transfer across 14 vision-language datasets spanning 7 diverse tasks. Our results show that intuitive task similarity is an unreliable predictor of transferability, and that generalization depends more on the specific dataset than on its broad task category. Motivated by this finding, we propose DATAPROPHET, a simple and effective training-free metric that combines multimodal perplexity, similarity, and data diversity. Experiments show that DATAPROPHET produces supervision-data rankings that strongly correlate with rankings based on actual post-training performance gains, achieving a Kendall's tau of 86.0%. Moreover, DATAPROPHET enables better supervision-data selection, yielding up to 6.9% improvement over uniform selection, 1.4% over a state-of-the-art training-based baseline, and 0.2% above oracle selection based on experimental performance. Our code and data will be released.
Difficulty-Based Preference Data Selection by DPO Implicit Reward Gap
Aug 06, 2025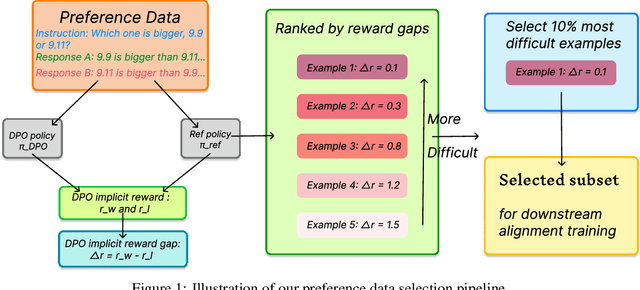
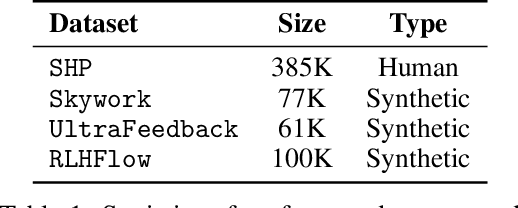
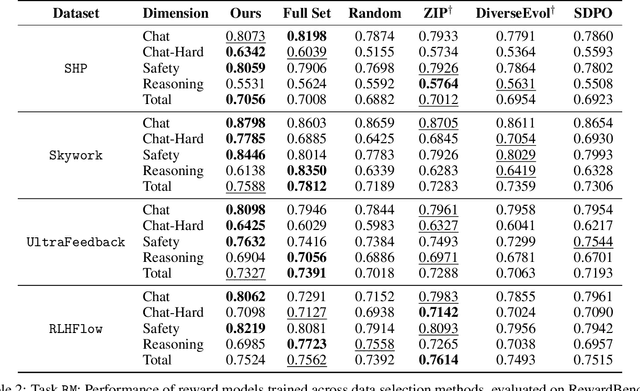
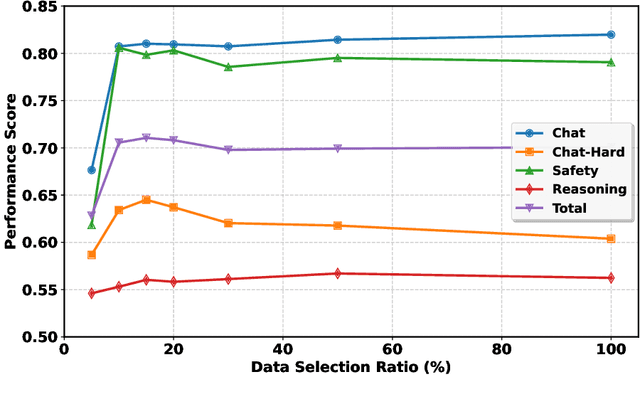
Aligning large language models (LLMs) with human preferences is a critical challenge in AI research. While methods like Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) are widely used, they often rely on large, costly preference datasets. The current work lacks methods for high-quality data selection specifically for preference data. In this work, we introduce a novel difficulty-based data selection strategy for preference datasets, grounded in the DPO implicit reward mechanism. By selecting preference data examples with smaller DPO implicit reward gaps, which are indicative of more challenging cases, we improve data efficiency and model alignment. Our approach consistently outperforms five strong baselines across multiple datasets and alignment tasks, achieving superior performance with only 10\% of the original data. This principled, efficient selection method offers a promising solution for scaling LLM alignment with limited resources.
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025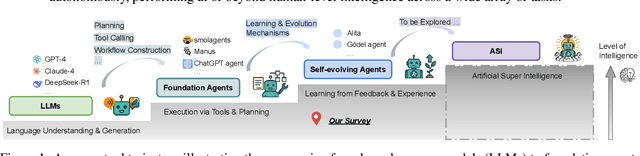

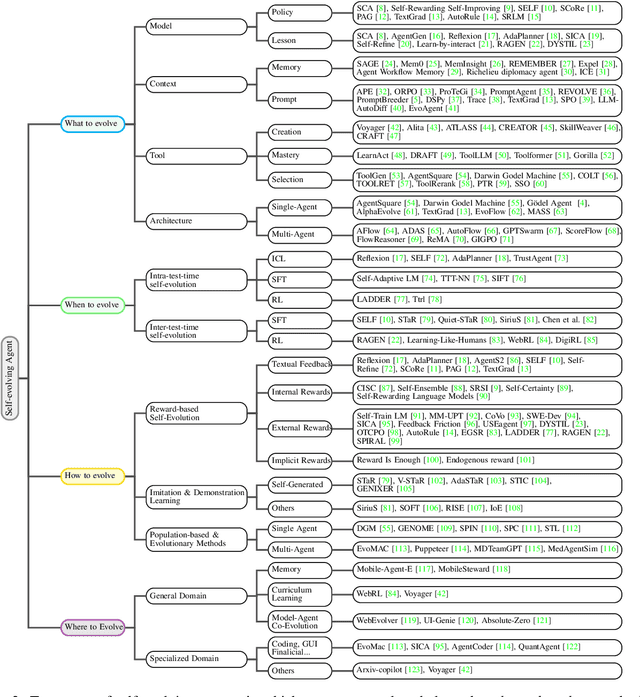
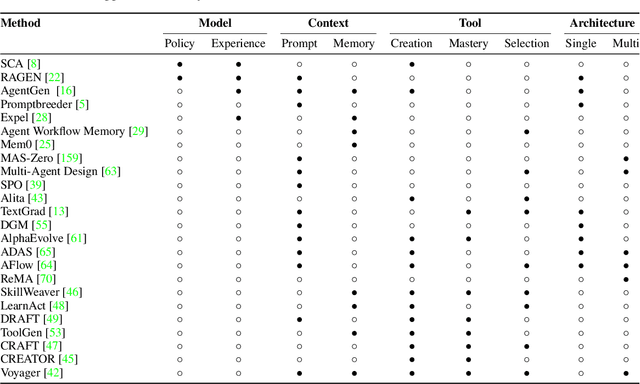
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
AgentDistill: Training-Free Agent Distillation with Generalizable MCP Boxes
Jun 17, 2025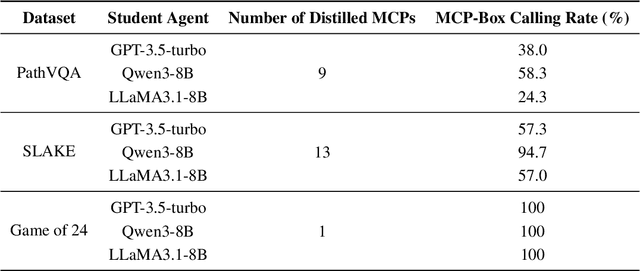
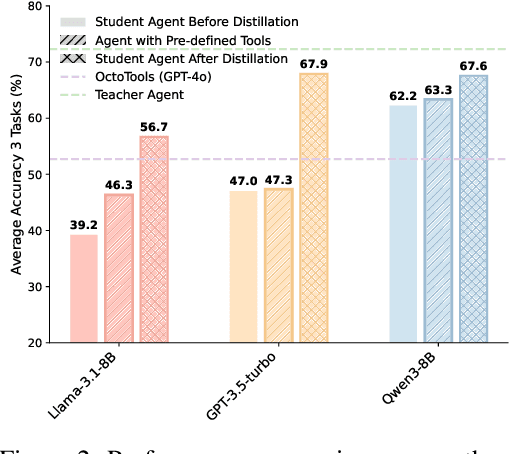
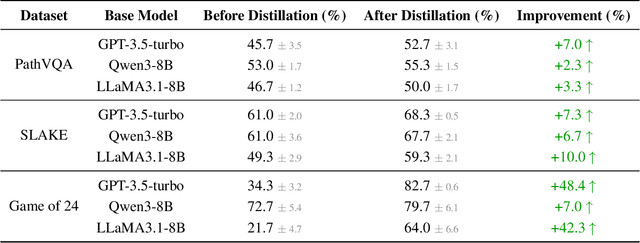
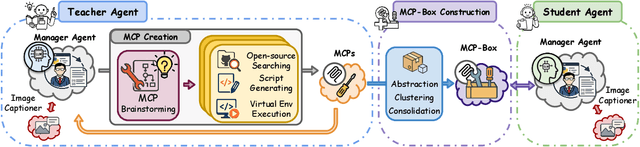
While knowledge distillation has become a mature field for compressing large language models (LLMs) into smaller ones by aligning their outputs or internal representations, the distillation of LLM-based agents, which involve planning, memory, and tool use, remains relatively underexplored. Existing agent distillation methods typically replay full teacher trajectories or imitate step-by-step teacher tool usage, but they often struggle to train student agents to dynamically plan and act in novel environments. We propose AgentDistill, a novel, training-free agent distillation framework that enables efficient and scalable knowledge transfer via direct reuse of Model-Context-Protocols (MCPs), which are structured and reusable task-solving modules autonomously generated by teacher agents. The reuse of these distilled MCPs enables student agents to generalize their capabilities across domains and solve new problems with minimal supervision or human intervention. Experiments on biomedical and mathematical benchmarks demonstrate that our distilled student agents, built on small language models, can achieve performance comparable to advanced systems using large LLMs such as OctoTools (GPT-4o), highlighting the effectiveness of our framework in building scalable and cost-efficient intelligent agents.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution
May 26, 2025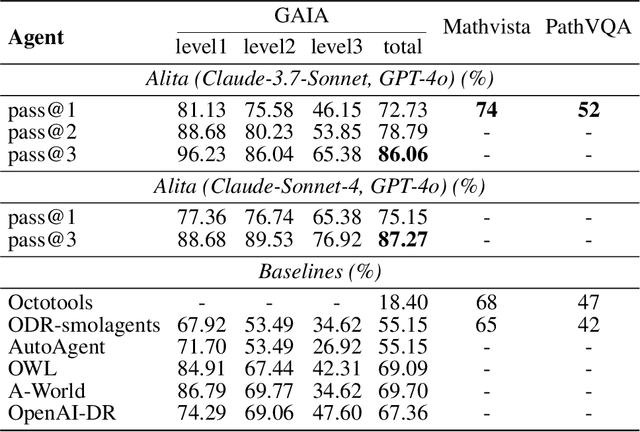
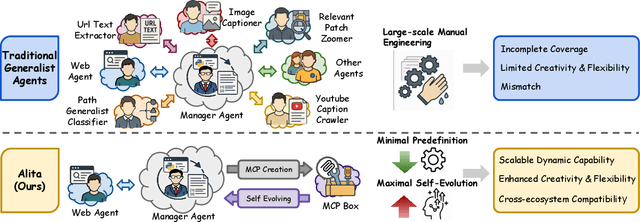
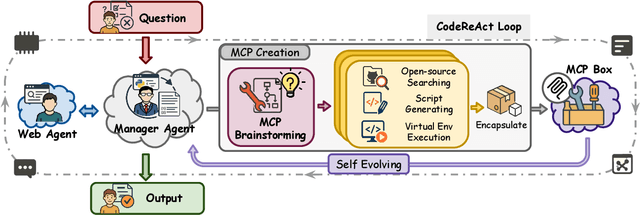

Recent advances in large language models (LLMs) have enabled agents to autonomously perform complex, open-ended tasks. However, many existing frameworks depend heavily on manually predefined tools and workflows, which hinder their adaptability, scalability, and generalization across domains. In this work, we introduce Alita--a generalist agent designed with the principle of "Simplicity is the ultimate sophistication," enabling scalable agentic reasoning through minimal predefinition and maximal self-evolution. For minimal predefinition, Alita is equipped with only one component for direct problem-solving, making it much simpler and neater than previous approaches that relied heavily on hand-crafted, elaborate tools and workflows. This clean design enhances its potential to generalize to challenging questions, without being limited by tools. For Maximal self-evolution, we enable the creativity of Alita by providing a suite of general-purpose components to autonomously construct, refine, and reuse external capabilities by generating task-related model context protocols (MCPs) from open source, which contributes to scalable agentic reasoning. Notably, Alita achieves 75.15% pass@1 and 87.27% pass@3 accuracy, which is top-ranking among general-purpose agents, on the GAIA benchmark validation dataset, 74.00% and 52.00% pass@1, respectively, on Mathvista and PathVQA, outperforming many agent systems with far greater complexity. More details will be updated at $\href{https://github.com/CharlesQ9/Alita}{https://github.com/CharlesQ9/Alita}$.