 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentDoG 1.5: A Lightweight and Scalable Alignment Framework for AI Agent Safety and Security
May 28, 2026Modern open-world agents such as OpenClaw exhibit powerful cross-environment execution capabilities yet introduce broad new safety risk sources. Meanwhile, advanced frontier AI models drastically lower attack barriers, rendering current agent alignment frameworks inadequate for real-world deployment. To tackle these emerging threats, we propose a lightweight and scalable agent safety alignment framework. Specifically, we update the agent safety taxonomy to accommodate emergent risks from Codex and OpenClaw execution scenarios. We further build a taxonomy-guided data engine with influence-function purification to train lightweight AgentDoG 1.5 variants (0.8B, 2B, 4B, and 8B parameters) using only around 1k samples, achieving comparable performance with leading closed-source models (e.g., GPT-5.4). Based on AgentDoG 1.5, we construct a highly efficient agentic safety SFT and RL training environment, which reduces deployment overhead in Docker-level environments by two orders of magnitude. Finally, we deploy AgentDoG 1.5 as a training-free online guardrail for real-time safety moderation. Extensive experimental results indicate that AgentDoG 1.5 achieves state-of-the-art performance in diverse and complex interactive agentic scenarios. All models and datasets are openly released.
Qumus: Realization of An Embodied AI Quantum Material Experimentalist
May 18, 2026While modern Large Language Models (LLMs) and agentic artificial intelligence (AI) have demonstrated transformative capabilities in digital domains, the realization of embodied AI capable of real-world scientific discovery remains a difficult frontier. The advancements are hindered by the inherent complexity of integrating high-level reasoning, multimodal information processing and real-time physical execution. Here we introduce Qumus, the first AI quantum materials experimentalist. Physically embodied within a robotic mini-laboratory, Qumus is an intelligent, multimodal, and multi-agent system designed for the creation and nano-processing of atomically thin two-dimensional (2D) materials and stacked van der Waals (vdW) structures. Qumus autonomously navigates the full scientific cycle, from hypothesis generation and protocol planning to multi-step experimental execution, result analysis and reporting, acting as an experimentalist. Markedly, the system has achieved, for the first time, the AI-creation of graphene, as well as the first AI-fabrication of complex nanodevices including atomically thin field-effect transistors via vdW stacking. Qumus excels at these tasks by demonstrating autonomous error correction and closed-loop experimentation. Our results establish a generalizable framework for self-improving embodied AI systems that learn directly from the quantum world, opening a pathway toward accelerated discovery in quantum materials, electronics and beyond.
Contrastive Reasoning Alignment: Reinforcement Learning from Hidden Representations
Mar 18, 2026We propose CRAFT, a red-teaming alignment framework that leverages model reasoning capabilities and hidden representations to improve robustness against jailbreak attacks. Unlike prior defenses that operate primarily at the output level, CRAFT aligns large reasoning models to generate safety-aware reasoning traces by explicitly optimizing objectives defined over the hidden state space. Methodologically, CRAFT integrates contrastive representation learning with reinforcement learning to separate safe and unsafe reasoning trajectories, yielding a latent-space geometry that supports robust, reasoning-level safety alignment. Theoretically, we show that incorporating latent-textual consistency into GRPO eliminates superficially aligned policies by ruling them out as local optima. Empirically, we evaluate CRAFT on multiple safety benchmarks using two strong reasoning models, Qwen3-4B-Thinking and R1-Distill-Llama-8B, where it consistently outperforms state-of-the-art defenses such as IPO and SafeKey. Notably, CRAFT delivers an average 79.0% improvement in reasoning safety and 87.7% improvement in final-response safety over the base models, demonstrating the effectiveness of hidden-space reasoning alignment.
Learn to Select: Exploring Label Distribution Divergence for In-Context Demonstration Selection in Text Classification
Nov 10, 2025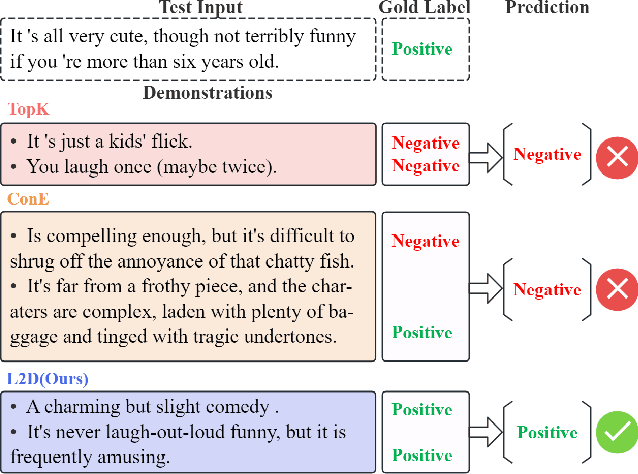
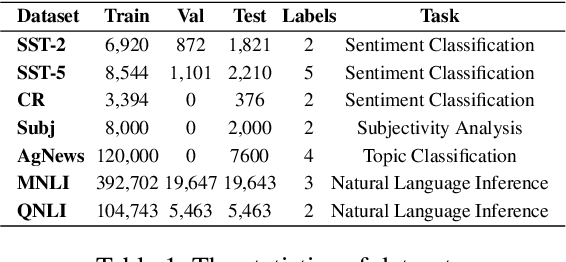
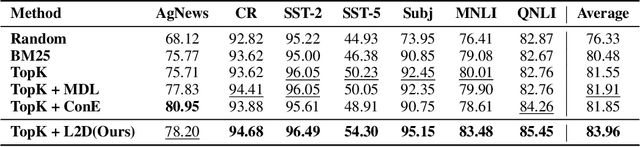
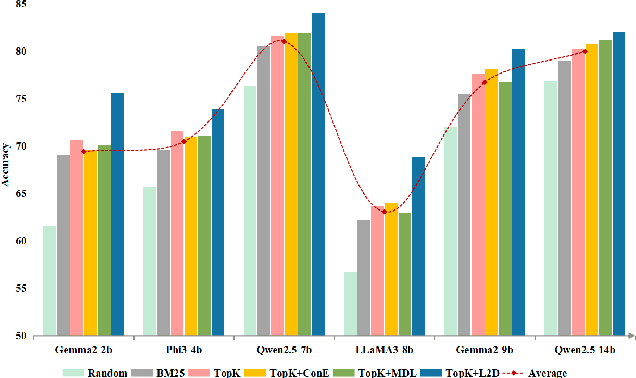
In-context learning (ICL) for text classification, which uses a few input-label demonstrations to describe a task, has demonstrated impressive performance on large language models (LLMs). However, the selection of in-context demonstrations plays a crucial role and can significantly affect LLMs' performance. Most existing demonstration selection methods primarily focus on semantic similarity between test inputs and demonstrations, often overlooking the importance of label distribution alignment. To address this limitation, we propose a two-stage demonstration selection method, TopK + Label Distribution Divergence (L2D), which leverages a fine-tuned BERT-like small language model (SLM) to generate label distributions and calculate their divergence for both test inputs and candidate demonstrations. This enables the selection of demonstrations that are not only semantically similar but also aligned in label distribution with the test input. Extensive experiments across seven text classification benchmarks show that our method consistently outperforms previous demonstration selection strategies. Further analysis reveals a positive correlation between the performance of LLMs and the accuracy of the underlying SLMs used for label distribution estimation.
AgentDistill: Training-Free Agent Distillation with Generalizable MCP Boxes
Jun 17, 2025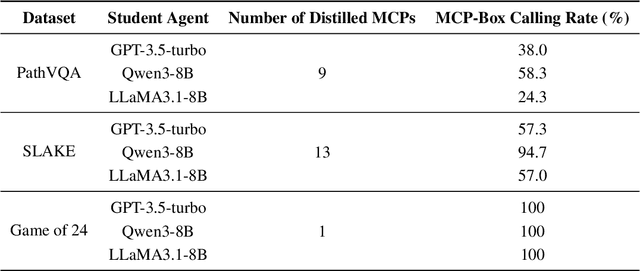
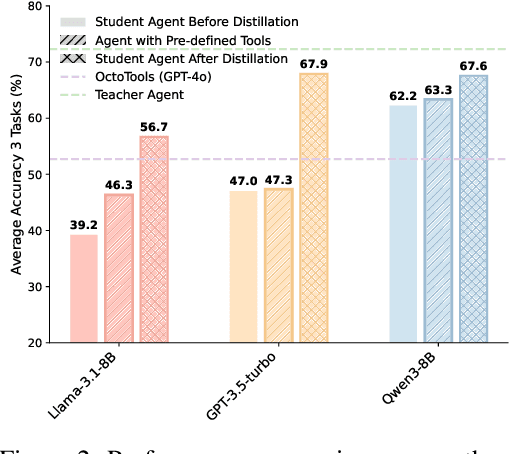
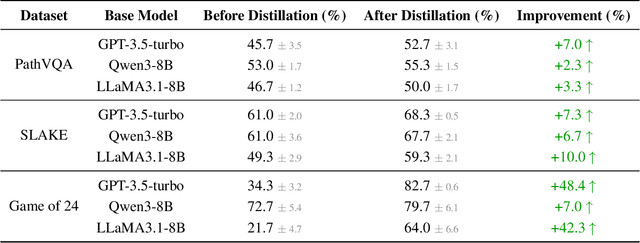
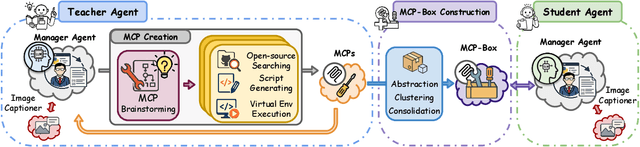
While knowledge distillation has become a mature field for compressing large language models (LLMs) into smaller ones by aligning their outputs or internal representations, the distillation of LLM-based agents, which involve planning, memory, and tool use, remains relatively underexplored. Existing agent distillation methods typically replay full teacher trajectories or imitate step-by-step teacher tool usage, but they often struggle to train student agents to dynamically plan and act in novel environments. We propose AgentDistill, a novel, training-free agent distillation framework that enables efficient and scalable knowledge transfer via direct reuse of Model-Context-Protocols (MCPs), which are structured and reusable task-solving modules autonomously generated by teacher agents. The reuse of these distilled MCPs enables student agents to generalize their capabilities across domains and solve new problems with minimal supervision or human intervention. Experiments on biomedical and mathematical benchmarks demonstrate that our distilled student agents, built on small language models, can achieve performance comparable to advanced systems using large LLMs such as OctoTools (GPT-4o), highlighting the effectiveness of our framework in building scalable and cost-efficient intelligent agents.
Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution
May 26, 2025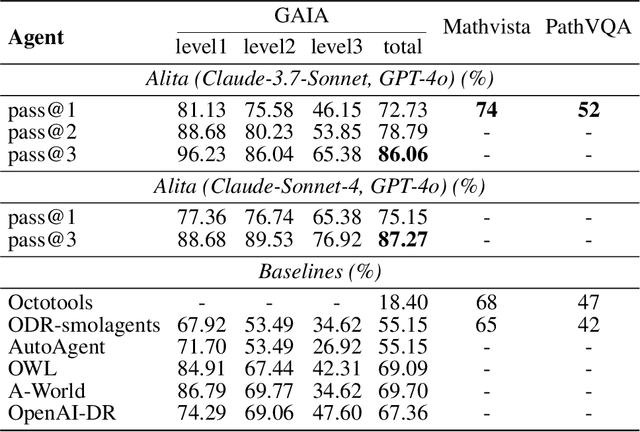
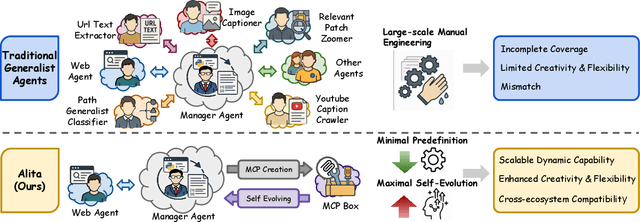
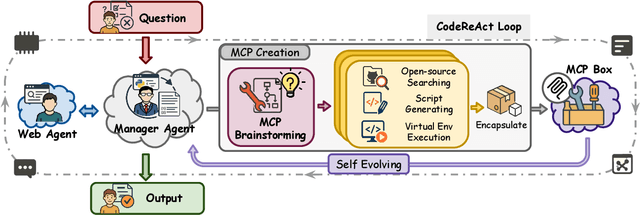

Recent advances in large language models (LLMs) have enabled agents to autonomously perform complex, open-ended tasks. However, many existing frameworks depend heavily on manually predefined tools and workflows, which hinder their adaptability, scalability, and generalization across domains. In this work, we introduce Alita--a generalist agent designed with the principle of "Simplicity is the ultimate sophistication," enabling scalable agentic reasoning through minimal predefinition and maximal self-evolution. For minimal predefinition, Alita is equipped with only one component for direct problem-solving, making it much simpler and neater than previous approaches that relied heavily on hand-crafted, elaborate tools and workflows. This clean design enhances its potential to generalize to challenging questions, without being limited by tools. For Maximal self-evolution, we enable the creativity of Alita by providing a suite of general-purpose components to autonomously construct, refine, and reuse external capabilities by generating task-related model context protocols (MCPs) from open source, which contributes to scalable agentic reasoning. Notably, Alita achieves 75.15% pass@1 and 87.27% pass@3 accuracy, which is top-ranking among general-purpose agents, on the GAIA benchmark validation dataset, 74.00% and 52.00% pass@1, respectively, on Mathvista and PathVQA, outperforming many agent systems with far greater complexity. More details will be updated at $\href{https://github.com/CharlesQ9/Alita}{https://github.com/CharlesQ9/Alita}$.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
GenoArmory: A Unified Evaluation Framework for Adversarial Attacks on Genomic Foundation Models
May 16, 2025

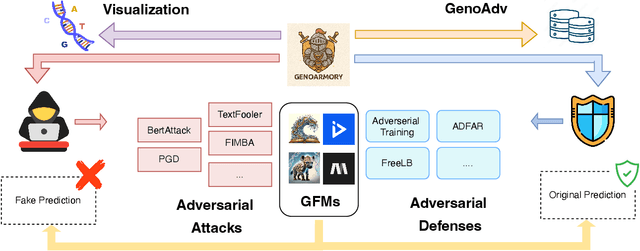

We propose the first unified adversarial attack benchmark for Genomic Foundation Models (GFMs), named GenoArmory. Unlike existing GFM benchmarks, GenoArmory offers the first comprehensive evaluation framework to systematically assess the vulnerability of GFMs to adversarial attacks. Methodologically, we evaluate the adversarial robustness of five state-of-the-art GFMs using four widely adopted attack algorithms and three defense strategies. Importantly, our benchmark provides an accessible and comprehensive framework to analyze GFM vulnerabilities with respect to model architecture, quantization schemes, and training datasets. Additionally, we introduce GenoAdv, a new adversarial sample dataset designed to improve GFM safety. Empirically, classification models exhibit greater robustness to adversarial perturbations compared to generative models, highlighting the impact of task type on model vulnerability. Moreover, adversarial attacks frequently target biologically significant genomic regions, suggesting that these models effectively capture meaningful sequence features.
Analysis of Higher-Order Ising Hamiltonians
Dec 18, 2024



It is challenging to scale Ising machines for industrial-level problems due to algorithm or hardware limitations. Although higher-order Ising models provide a more compact encoding, they are, however, hard to physically implement. This work proposes a theoretical framework of a higher-order Ising simulator, IsingSim. The Ising spins and gradients in IsingSim are decoupled and self-customizable. We significantly accelerate the simulation speed via a bidirectional approach for differentiating the hyperedge functions. Our proof-of-concept implementation verifies the theoretical framework by simulating the Ising spins with exact and approximate gradients. Experiment results show that our novel framework can be a useful tool for providing design guidelines for higher-order Ising machines.
Performance Analysis of Photon-Limited Free-Space Optical Communications with Practical Photon-Counting Receivers
Aug 24, 2024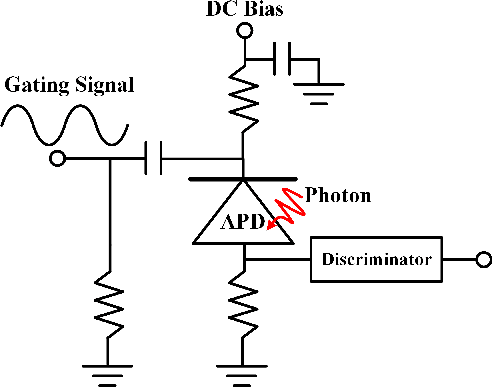
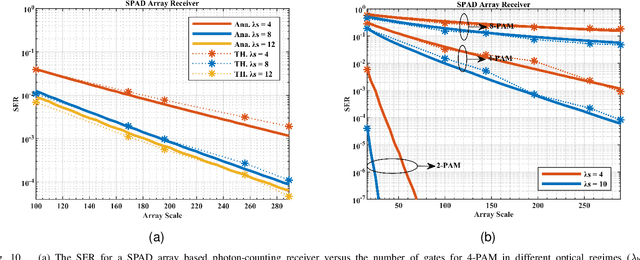
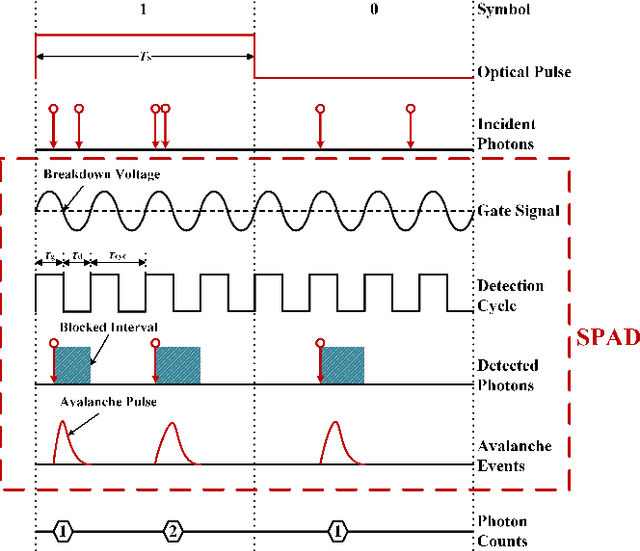
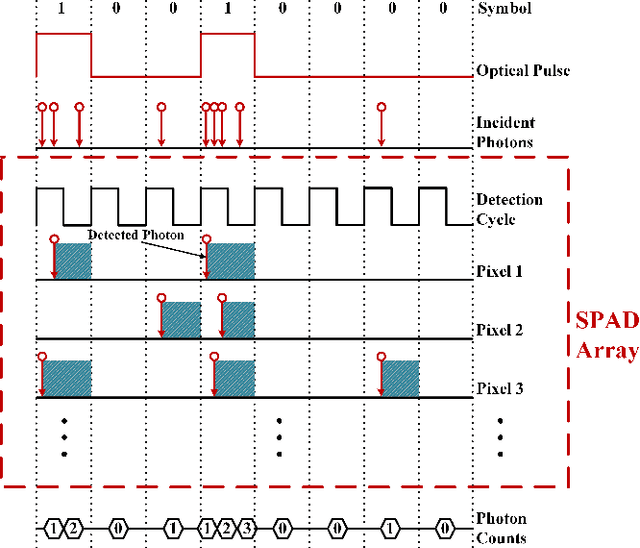
The non-perfect factors of practical photon-counting receiver are recognized as a significant challenge for long-distance photon-limited free-space optical (FSO) communication systems. This paper presents a comprehensive analytical framework for modeling the statistical properties of time-gated single-photon avalanche diode (TG-SPAD) based photon-counting receivers in presence of dead time, non-photon-number-resolving and afterpulsing effect. Drawing upon the non-Markovian characteristic of afterpulsing effect, we formulate a closed-form approximation for the probability mass function (PMF) of photon counts, when high-order pulse amplitude modulation (PAM) is used. Unlike the photon counts from a perfect photon-counting receiver, which adhere to a Poisson arrival process, the photon counts from a practical TG-SPAD based receiver are instead approximated by a binomial distribution. Additionally, by employing the maximum likelihood (ML) criterion, we derive a refined closed-form formula for determining the threshold in high-order PAM, thereby facilitating the development of an analytical model for the symbol error rate (SER). Utilizing this analytical SER model, the system performance is investigated. The numerical results underscore the crucial need to suppress background radiation below the tolerated threshold and to maintain a sufficient number of gates in order to achieve a target SER.