 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDART-ing Through the Drift: Dynamic Tracing of Knowledge Neurons for Adaptive Inference-Time Pruning
Jan 30, 2026Large Language Models (LLMs) exhibit substantial parameter redundancy, particularly in Feed-Forward Networks (FFNs). Existing pruning methods suffer from two primary limitations. First, reliance on dataset-specific calibration introduces significant data dependency and computational overhead. Second, being predominantly static, they fail to account for the evolving subset of knowledge neurons in LLMs during autoregressive generation as the context evolves. To address this, we introduce DART, i.e., Dynamic Attention-Guided Runtime Tracing), a lightweight, training-free method that performs on-the-fly context-based pruning. DART monitors shifts in attention score distributions to infer context changes, dynamically updating neuron-level masks to retain salient parameters. Across ten benchmarks, DART outperforms prior dynamic baseline, achieving accuracy gains of up to 14.5% on LLAMA-3.1-8B at 70% FFN sparsity. Furthermore, DART achieves up to 3x better ROUGE-L scores with respect to static-masked pruning on summarization tasks, with its performance comparable to the original dense models. We conclusively demonstrate that the proposed framework effectively adapts to diverse semantic contexts, preserves model capabilities across both general and domain-specific tasks while running at less than 10MBs of memory for LLAMA-3.1-8B(16GBs) with 0.1% FLOPs overhead. The code is available at https://github.com/seeder-research/DART.
On Continuous Optimization for Constraint Satisfaction Problems
Oct 06, 2025



Constraint satisfaction problems (CSPs) are fundamental in mathematics, physics, and theoretical computer science. While conflict-driven clause learning Boolean Satisfiability (SAT) solvers have achieved remarkable success and become the mainstream approach for Boolean satisfiability, recent advances show that modern continuous local search (CLS) solvers can achieve highly competitive results on certain classes of SAT problems. Motivated by these advances, we extend the CLS framework from Boolean SAT to general CSP with finite-domain variables and expressive constraints. We present FourierCSP, a continuous optimization framework that generalizes the Walsh-Fourier transform to CSP, allowing for transforming versatile constraints to compact multilinear polynomials, thereby avoiding the need for auxiliary variables and memory-intensive encodings. Our approach leverages efficient evaluation and differentiation of the objective via circuit-output probability and employs a projected gradient optimization method with theoretical guarantees. Empirical results on benchmark suites demonstrate that FourierCSP is scalable and competitive, significantly broadening the class of problems that can be efficiently solved by CLS techniques.
Analysis of Higher-Order Ising Hamiltonians
Dec 18, 2024



It is challenging to scale Ising machines for industrial-level problems due to algorithm or hardware limitations. Although higher-order Ising models provide a more compact encoding, they are, however, hard to physically implement. This work proposes a theoretical framework of a higher-order Ising simulator, IsingSim. The Ising spins and gradients in IsingSim are decoupled and self-customizable. We significantly accelerate the simulation speed via a bidirectional approach for differentiating the hyperedge functions. Our proof-of-concept implementation verifies the theoretical framework by simulating the Ising spins with exact and approximate gradients. Experiment results show that our novel framework can be a useful tool for providing design guidelines for higher-order Ising machines.
Massively Parallel Continuous Local Search for Hybrid SAT Solving on GPUs
Aug 29, 2023



Although state-of-the-art (SOTA) SAT solvers based on conflict-driven clause learning (CDCL) have achieved remarkable engineering success, their sequential nature limits the parallelism that may be extracted for acceleration on platforms such as the graphics processing unit (GPU). In this work, we propose FastFourierSAT, a highly parallel hybrid SAT solver based on gradient-driven continuous local search (CLS). This is realized by a novel parallel algorithm inspired by the Fast Fourier Transform (FFT)-based convolution for computing the elementary symmetric polynomials (ESPs), which is the major computational task in previous CLS methods. The complexity of our algorithm matches the best previous result. Furthermore, the substantial parallelism inherent in our algorithm can leverage the GPU for acceleration, demonstrating significant improvement over the previous CLS approaches. We also propose to incorporate the restart heuristics in CLS to improve search efficiency. We compare our approach with the SOTA parallel SAT solvers on several benchmarks. Our results show that FastFourierSAT computes the gradient 100+ times faster than previous prototypes implemented on CPU. Moreover, FastFourierSAT solves most instances and demonstrates promising performance on larger-size instances.
CITS: Coherent Ising Tree Search Algorithm Towards Solving Combinatorial Optimization Problems
Mar 09, 2022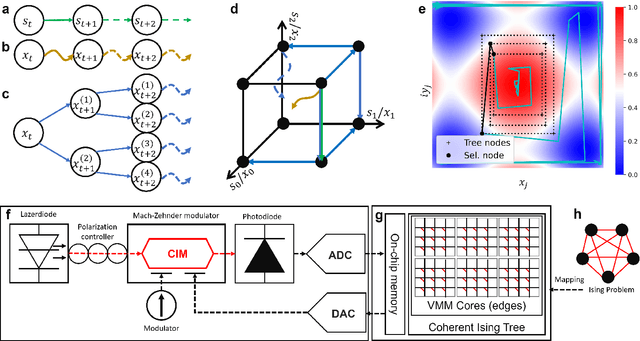
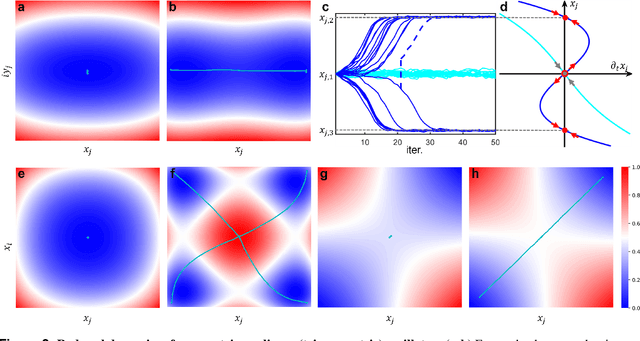
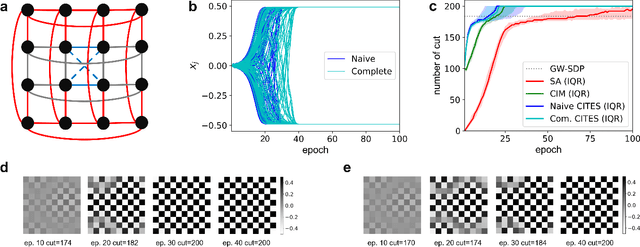
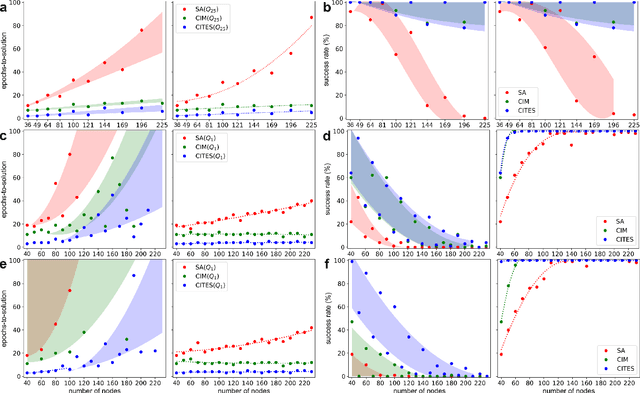
Simulated annealing (SA) attracts more attention among classical heuristic algorithms because the solution of the combinatorial optimization problem can be naturally mapped to the ground state of the Ising Hamiltonian. However, in practical implementation, the annealing process cannot be arbitrarily slow and hence, it may deviate from the expected stationary Boltzmann distribution and become trapped in a local energy minimum. To overcome this problem, this paper proposes a heuristic search algorithm by expanding search space from a Markov chain to a recursive depth limited tree based on SA, where the parent and child nodes represent the current and future spin states. At each iteration, the algorithm will select the best near-optimal solution within the feasible search space by exploring along the tree in the sense of `look ahead'. Furthermore, motivated by coherent Ising machine (CIM), we relax the discrete representation of spin states to continuous representation with a regularization term and utilize the reduced dynamics of the oscillators to explore the surrounding neighborhood of the selected tree nodes. We tested our algorithm on a representative NP-hard problem (MAX-CUT) to illustrate the effectiveness of this algorithm compared to semi-definite programming (SDP), SA, and simulated CIM. Our results show that above the primal heuristics SA and CIM, our high-level tree search strategy is able to provide solutions within fewer epochs for Ising formulated NP-optimization problems.
Connection Pruning for Deep Spiking Neural Networks with On-Chip Learning
Oct 12, 2020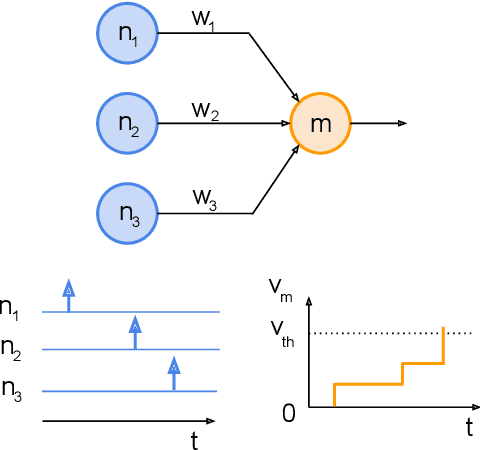

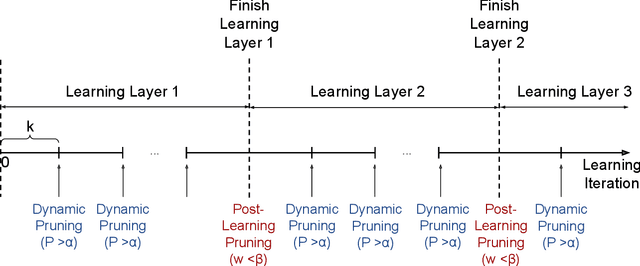
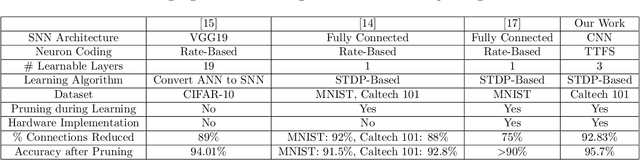
Long training time hinders the potential of the deep Spiking Neural Network (SNN) with the online learning capability to be realized on the embedded systems hardware. Our work proposes a novel connection pruning approach that can be applied during the online Spike Timing Dependent Plasticity (STDP)-based learning to optimize the learning time and the network connectivity of the SNN. Our connection pruning approach was evaluated on a deep SNN with the Time To First Spike (TTFS) coding and has successfully achieved 2.1x speed-up in the online learning and reduced the network connectivity by 92.83%. The energy consumption in the online learning was saved by 64%. Moreover, the connectivity reduction results in 2.83x speed-up and 78.24% energy saved in the inference. Meanwhile, the classification accuracy remains the same as our non-pruning baseline on the Caltech 101 dataset. In addition, we developed an event-driven hardware architecture on the Field Programmable Gate Array (FPGA) platform that efficiently incorporates our proposed connection pruning approach while incurring as little as 0.56% power overhead. Moreover, we performed a comparison between our work and the existing works on connection pruning for SNN to highlight the key features of each approach. To the best of our knowledge, our work is the first to propose a connection pruning algorithm that can be applied during the online STDP-based learning for a deep SNN with the TTFS coding.