 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Select: Exploring Label Distribution Divergence for In-Context Demonstration Selection in Text Classification
Nov 10, 2025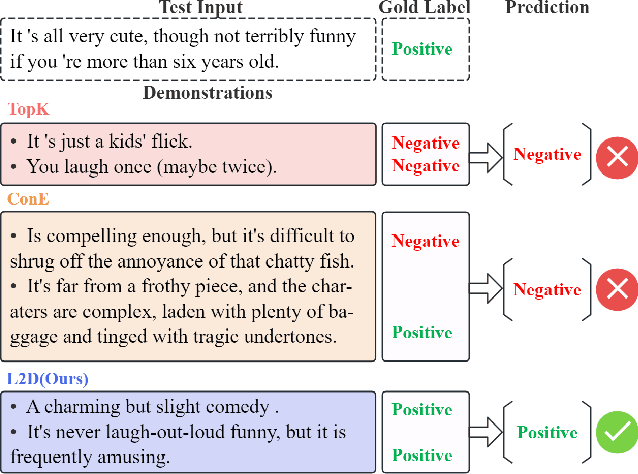
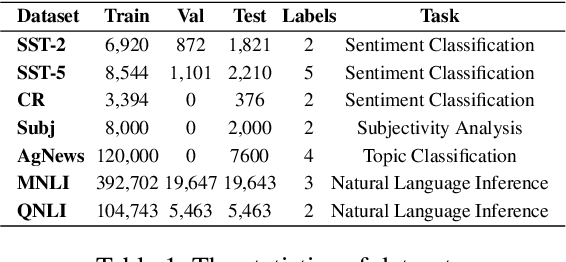
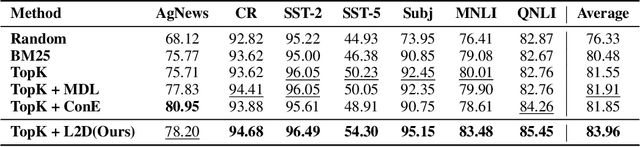
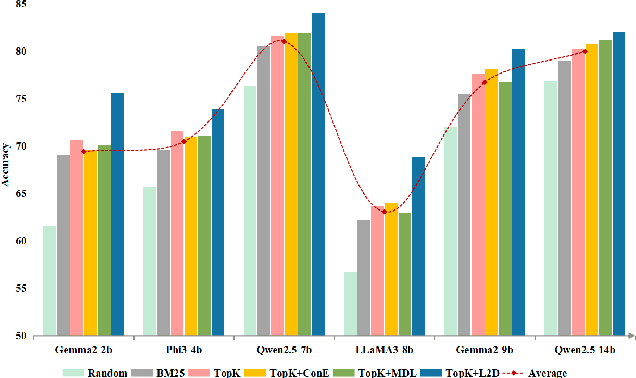
In-context learning (ICL) for text classification, which uses a few input-label demonstrations to describe a task, has demonstrated impressive performance on large language models (LLMs). However, the selection of in-context demonstrations plays a crucial role and can significantly affect LLMs' performance. Most existing demonstration selection methods primarily focus on semantic similarity between test inputs and demonstrations, often overlooking the importance of label distribution alignment. To address this limitation, we propose a two-stage demonstration selection method, TopK + Label Distribution Divergence (L2D), which leverages a fine-tuned BERT-like small language model (SLM) to generate label distributions and calculate their divergence for both test inputs and candidate demonstrations. This enables the selection of demonstrations that are not only semantically similar but also aligned in label distribution with the test input. Extensive experiments across seven text classification benchmarks show that our method consistently outperforms previous demonstration selection strategies. Further analysis reveals a positive correlation between the performance of LLMs and the accuracy of the underlying SLMs used for label distribution estimation.
AMPLE: Emotion-Aware Multimodal Fusion Prompt Learning for Fake News Detection
Oct 21, 2024Detecting fake news in large datasets is challenging due to its diversity and complexity, with traditional approaches often focusing on textual features while underutilizing semantic and emotional elements. Current methods also rely heavily on large annotated datasets, limiting their effectiveness in more nuanced analysis. To address these challenges, this paper introduces Emotion-\textbf{A}ware \textbf{M}ultimodal Fusion \textbf{P}rompt \textbf{L}\textbf{E}arning (\textbf{AMPLE}) framework to address the above issue by combining text sentiment analysis with multimodal data and hybrid prompt templates. This framework extracts emotional elements from texts by leveraging sentiment analysis tools. It then employs Multi-Head Cross-Attention (MCA) mechanisms and similarity-aware fusion methods to integrate multimodal data. The proposed AMPLE framework demonstrates strong performance on two public datasets in both few-shot and data-rich settings, with results indicating the potential of emotional aspects in fake news detection. Furthermore, the study explores the impact of integrating large language models with this method for text sentiment extraction, revealing substantial room for further improvement. The code can be found at :\url{https://github.com/xxm1215/MMM2025_few-shot/
Cross-Modal Augmentation for Few-Shot Multimodal Fake News Detection
Jul 16, 2024



The nascent topic of fake news requires automatic detection methods to quickly learn from limited annotated samples. Therefore, the capacity to rapidly acquire proficiency in a new task with limited guidance, also known as few-shot learning, is critical for detecting fake news in its early stages. Existing approaches either involve fine-tuning pre-trained language models which come with a large number of parameters, or training a complex neural network from scratch with large-scale annotated datasets. This paper presents a multimodal fake news detection model which augments multimodal features using unimodal features. For this purpose, we introduce Cross-Modal Augmentation (CMA), a simple approach for enhancing few-shot multimodal fake news detection by transforming n-shot classification into a more robust (n $\times$ z)-shot problem, where z represents the number of supplementary features. The proposed CMA achieves SOTA results over three benchmark datasets, utilizing a surprisingly simple linear probing method to classify multimodal fake news with only a few training samples. Furthermore, our method is significantly more lightweight than prior approaches, particularly in terms of the number of trainable parameters and epoch times. The code is available here: \url{https://github.com/zgjiangtoby/FND_fewshot}
Team QUST at SemEval-2024 Task 8: A Comprehensive Study of Monolingual and Multilingual Approaches for Detecting AI-generated Text
Feb 19, 2024



This paper presents the participation of team QUST in Task 8 SemEval 2024. We first performed data augmentation and cleaning on the dataset to enhance model training efficiency and accuracy. In the monolingual task, we evaluated traditional deep-learning methods, multiscale positive-unlabeled framework (MPU), fine-tuning, adapters and ensemble methods. Then, we selected the top-performing models based on their accuracy from the monolingual models and evaluated them in subtasks A and B. The final model construction employed a stacking ensemble that combined fine-tuning with MPU. Our system achieved 8th (scored 8th in terms of accuracy, officially ranked 13th) place in the official test set in multilingual settings of subtask A. We release our system code at:https://github.com/warmth27/SemEval2024_QUST